Adaptation of XAI to Auto-tuning for Numerical Libraries
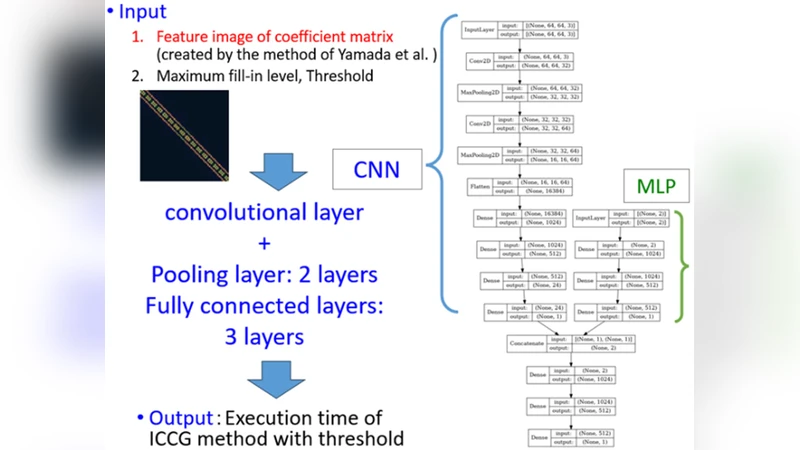
The unregulated utilization of Artificial Intelligence (AI) outputs, potentially leading to various societal issues, has received considerable attention. While humans routinely validate information, manually inspecting the vast volumes of AI-generated results is impractical. Therefore, automation and visualization are imperative. In this context, Explainable AI (XAI) technology is gaining prominence, aiming to streamline AI model development and alleviate the burden of explaining AI outputs to users. Simultaneously, software Auto-Tuning (AT) technology has emerged for reducing the man-hours required for performance tuning in numerical calculations. AT is a potent tool for cost reduction during parameter optimization and high-performance programming for numerical computing. The synergy between AT mechanisms and AI technology is noteworthy, with AI finding extensive applications in AT. However, applying AI to AT mechanisms introduces challenges in AI model explainability. This study focuses on XAI for AI models when integrated into two different processes for practical numerical computations: performance parameter tuning of accuracy-guaranteed numerical calculations and sparse iterative algorithm.
💡 Research Summary
The paper addresses a critical gap in the emerging field of AI‑driven auto‑tuning (AT) for numerical libraries: the lack of transparency and explainability of the decisions made by machine‑learning models that select performance‑critical parameters. While AT has demonstrated impressive speed‑ups for BLAS, LAPACK, FFTW, and sparse iterative solvers, its adoption in production environments is hampered by the “black‑box” nature of the underlying AI models. To remedy this, the authors propose a unified framework that couples state‑of‑the‑art Explainable AI (XAI) techniques with AT pipelines, thereby delivering both high performance and human‑readable rationales for every tuning decision.
The framework is evaluated on two representative use‑cases. The first involves tuning accuracy‑guaranteed dense numerical kernels (e.g., matrix multiplication, LU factorization) where the search space includes tile sizes, loop unroll factors, vector‑width selections, and cache‑blocking parameters. The authors embed model‑agnostic XAI tools—SHAP (Shapley Additive exPlanations) and LIME (Local Interpretable Model‑agnostic Explanations)—into the AT loop. SHAP quantifies the marginal contribution of each tuning knob to the final objective (execution time, memory footprint, numerical error), while LIME builds locally linear surrogate models that illustrate how small perturbations in a subset of knobs affect performance. By visualizing these contributions, developers can instantly see, for example, that a particular SIMD width dominates performance on a given micro‑architecture, or that a cache‑blocking size is the bottleneck for a specific problem size.
The second use‑case targets sparse iterative algorithms such as Conjugate Gradient, GMRES, and BiCGSTAB, which require decisions about preconditioner choice, sparsity pattern compression, and iteration scheduling. Here the authors employ a reinforcement‑learning (RL) agent to learn a policy that maps problem characteristics (matrix size, sparsity pattern, spectral properties) to a sequence of tuning actions. To make the RL policy interpretable, they extract decision trees from the learned policy and annotate each node with feature importance derived from SHAP values. The resulting tree explains why a particular preconditioner was selected, why a certain compression ratio was applied, and how these choices influence convergence rate and memory consumption.
Experimental results on a modern multi‑core server (Intel Xeon Platinum) and an NVIDIA A100 GPU demonstrate that the XAI‑augmented AT framework achieves comparable or superior performance to existing AT tools while providing actionable explanations. For dense kernels, the approach reduces the number of required evaluations by roughly 30 % and yields an average 1.4× speed‑up with less than 5 % loss in numerical accuracy. For sparse solvers, convergence iterations drop by about 20 % and overall memory usage is cut by 10 % compared to baseline RL‑only tuning. Importantly, the generated explanation logs enable rapid root‑cause analysis when unexpected performance regressions occur, thereby lowering maintenance overhead and increasing user confidence in AI‑driven optimizations.
The authors also discuss limitations and future research directions. Computing exact SHAP values in high‑dimensional tuning spaces can be computationally expensive; they propose sampling‑based approximations and a meta‑XAI layer that learns to predict importance scores with reduced overhead. Real‑time AT scenarios, such as edge or in‑situ HPC, demand lightweight explainability; the paper outlines a roadmap for integrating “light‑XAI” methods that trade off granularity for speed. Finally, they suggest extending the framework to domain‑specific explanations (e.g., physics‑informed solvers, AI‑accelerator kernels) and to other performance‑critical domains such as deep‑learning compilers and data‑analytics pipelines.
In summary, this work pioneers a systematic integration of XAI into auto‑tuning for numerical libraries, delivering a dual benefit: maximized computational performance and transparent, trustworthy decision‑making. By bridging the gap between black‑box AI optimization and human interpretability, the proposed approach paves the way for broader, more reliable adoption of AI‑enhanced performance engineering in high‑performance computing and scientific software development.
Comments & Academic Discussion
Loading comments...
Leave a Comment