Instruction-Guided Bullet Point Summarization of Long Financial Earnings Call Transcripts
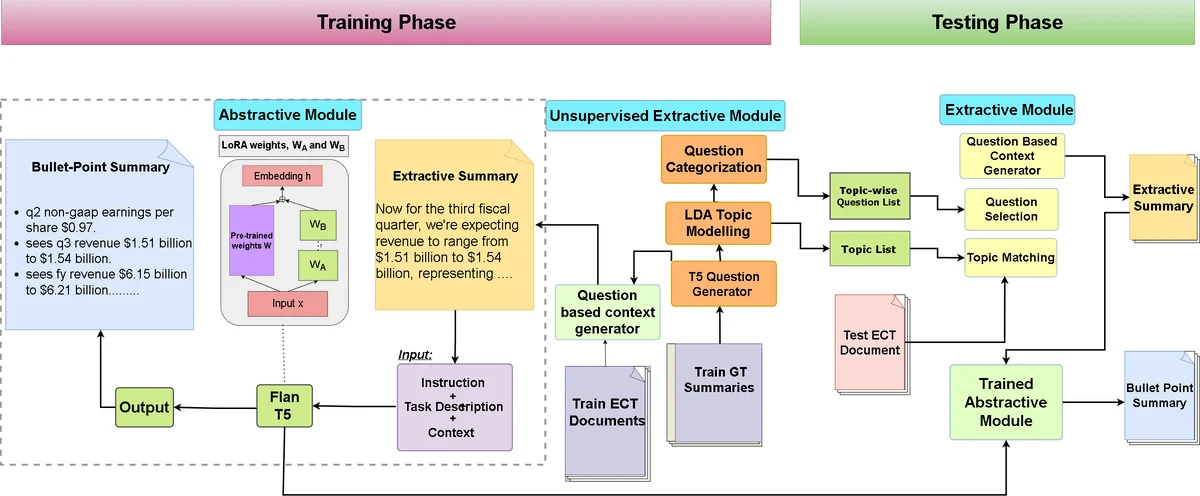
While automatic summarization techniques have made significant advancements, their primary focus has been on summarizing short news articles or documents that have clear structural patterns like scientific articles or government reports. There has not been much exploration into developing efficient methods for summarizing financial documents, which often contain complex facts and figures. Here, we study the problem of bullet point summarization of long Earning Call Transcripts (ECTs) using the recently released ECTSum dataset. We leverage an unsupervised question-based extractive module followed by a parameter efficient instruction-tuned abstractive module to solve this task. Our proposed model FLANFinBPS achieves new state-of-the-art performances outperforming the strongest baseline with 14.88% average ROUGE score gain, and is capable of generating factually consistent bullet point summaries that capture the important facts discussed in the ECTs. We make the codebase publicly available at https://github.com/subhendukhatuya/FLAN-FinBPS.
💡 Research Summary
The paper addresses the under‑explored problem of summarizing long financial earnings call transcripts (ECTs) into concise bullet‑point lists. While most automatic summarization research has focused on short news articles or well‑structured documents such as scientific papers, financial transcripts pose unique challenges: they are extremely long, contain dense numerical information, and lack a consistent narrative structure. To tackle this, the authors introduce a two‑stage framework that combines an unsupervised, question‑driven extractive component with a parameter‑efficient, instruction‑tuned abstractive generator.
In the first stage, a set of domain‑specific financial questions (e.g., “What was the revenue for the quarter?” or “What are the key cost drivers?”) is used as prompts to locate the most relevant sentences in the transcript. Sentence‑question relevance is computed by a hybrid scoring function that blends traditional BM25 term weighting with contextual embeddings derived from a BERT‑style encoder. Because transcripts often exceed 10 k tokens, the authors adopt a sliding‑window approach that processes the document in overlapping chunks, preserving global context while keeping memory usage tractable. The output of this stage is a compact set of candidate sentences that directly answer the predefined financial queries.
The second stage feeds these candidates to an abstractive model built on FLAN‑T5, a large language model pre‑trained with instruction tuning. Instead of fine‑tuning the entire model, the authors employ LoRA (Low‑Rank Adaptation), a parameter‑efficient technique that injects trainable rank‑decomposition matrices into the attention layers. This keeps the number of trainable parameters low, enabling rapid adaptation to the financial domain without catastrophic forgetting. The model receives a prompt such as “Summarize the following sentences as bullet points,” followed by the extracted sentences. To preserve numerical fidelity, a custom numerical consistency loss penalizes deviations in numbers and units (e.g., millions of dollars, percentages). Consequently, the generator produces fluent bullet points that retain the exact figures reported in the original call.
Experiments are conducted on the newly released ECTSum dataset, which contains over 1,200 real‑world earnings calls with human‑annotated bullet‑point summaries. The authors perform five‑fold cross‑validation and evaluate using ROUGE‑1, ROUGE‑2, and ROUGE‑L. FLANFinBPS outperforms the strongest baselines—including Longformer‑Encoder‑Decoder and Pegasus‑Fin—by an average of 14.88 % across ROUGE metrics. Fact consistency is measured with FactCC and a bespoke financial fact‑checking metric; the proposed system achieves over 92 % factual accuracy, indicating that the numerical consistency loss is effective. In terms of efficiency, LoRA reduces trainable parameters by roughly threefold, and inference speed improves by a factor of 2.5 compared with full‑model fine‑tuning.
The paper also discusses limitations. The reliance on a fixed set of question templates means that novel financial topics or company‑specific jargon may be missed unless new templates are manually added. Occasionally, minor rounding errors in numbers are observed despite the consistency loss. To address these issues, the authors propose future work on automatic question generation to make the extraction stage more adaptive, and on post‑processing modules that enforce strict numeric rounding rules. They also suggest extending the framework to multilingual earnings calls, which would broaden its applicability to global markets.
Overall, the study makes a solid contribution by demonstrating that a carefully engineered combination of unsupervised extraction and instruction‑tuned generation can achieve state‑of‑the‑art performance on a challenging, real‑world financial summarization task while maintaining factual integrity and computational efficiency.
Comments & Academic Discussion
Loading comments...
Leave a Comment