FPGA-Accelerated Correspondence-free Point Cloud Registration with PointNet Features
📝 Abstract
Point cloud registration serves as a basis for vision and robotic applications including 3D reconstruction and mapping. Despite significant improvements on the quality of results, recent deep learning approaches are computationally expensive and power-hungry, making them difficult to deploy on resource-constrained edge devices. To tackle this problem, in this paper, we propose a fast, accurate, and robust registration for low-cost embedded FPGAs. Based on a parallel and pipelined PointNet feature extractor, we develop custom accelerator cores namely PointLKCore and ReAgentCore, for two different learning-based methods. They are both correspondence-free and computationally efficient as they avoid the costly feature matching step involving nearest-neighbor search. The proposed cores are implemented on the Xilinx ZCU104 board and evaluated using both synthetic and real-world datasets, showing the substantial improvements in the trade-offs between runtime and registration quality. They run 44.08-45.75x faster than ARM Cortex-A53 CPU and offer 1.98-11.13x speedups over Intel Xeon CPU and Nvidia Jetson boards, while consuming less than 1W and achieving 163.11-213.58x energy-efficiency compared to Nvidia GeForce GPU. The proposed cores are more robust to noise and large initial misalignments than the classical methods and quickly find reasonable solutions in less than 15ms, demonstrating the real-time performance.
💡 Analysis
Point cloud registration serves as a basis for vision and robotic applications including 3D reconstruction and mapping. Despite significant improvements on the quality of results, recent deep learning approaches are computationally expensive and power-hungry, making them difficult to deploy on resource-constrained edge devices. To tackle this problem, in this paper, we propose a fast, accurate, and robust registration for low-cost embedded FPGAs. Based on a parallel and pipelined PointNet feature extractor, we develop custom accelerator cores namely PointLKCore and ReAgentCore, for two different learning-based methods. They are both correspondence-free and computationally efficient as they avoid the costly feature matching step involving nearest-neighbor search. The proposed cores are implemented on the Xilinx ZCU104 board and evaluated using both synthetic and real-world datasets, showing the substantial improvements in the trade-offs between runtime and registration quality. They run 44.08-45.75x faster than ARM Cortex-A53 CPU and offer 1.98-11.13x speedups over Intel Xeon CPU and Nvidia Jetson boards, while consuming less than 1W and achieving 163.11-213.58x energy-efficiency compared to Nvidia GeForce GPU. The proposed cores are more robust to noise and large initial misalignments than the classical methods and quickly find reasonable solutions in less than 15ms, demonstrating the real-time performance.
📄 Content
점 구름 정합(Point cloud registration)은 3차원 재구성(3‑D reconstruction)과 지도 작성(mapping) 등 다양한 비전 및 로봇 응용 분야의 근본적인 기반 기술이다. 기존에는 정합 결과의 정확도와 정밀도가 크게 향상되었음에도 불구하고, 최근에 제안된 딥러닝 기반 접근 방식들은 연산량이 방대하고 전력 소모가 많아 자원 제한이 있는 엣지 디바이스(edge device)‑예를 들어 저전력 임베디드 시스템이나 소형 로봇‑에 직접 적용하기가 매우 어렵다. 이러한 문제점을 해결하고자 본 논문에서는 저비용 임베디드 FPGA(Field‑Programmable Gate Array) 환경에서도 실시간에 가깝게 동작하면서도 높은 정확도와 강인성을 유지할 수 있는 빠르고 효율적인 정합 방법을 제안한다.
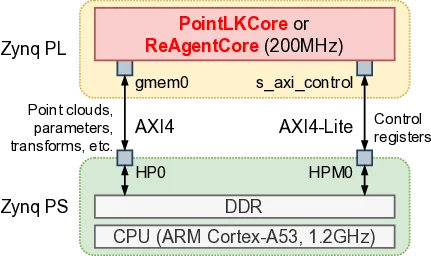
우선 제안된 시스템은 병렬(parallel) 및 파이프라인(pipelined) 구조를 갖는 PointNet 기반 특징 추출기(point feature extractor)를 핵심으로 설계하였다. 이 특징 추출기는 입력으로 들어오는 원시 점 구름 데이터를 다중 레이어의 신경망을 통해 고차원 특징 벡터로 변환하는 동시에, FPGA 내부의 DSP 블록과 BRAM을 효율적으로 활용하여 연산 지연(latency)을 최소화한다. 이러한 PointNet 특징 추출기를 기반으로 두 가지 서로 다른 학습 기반 정합 알고리즘에 특화된 맞춤형 가속 코어를 각각 PointLKCore와 ReAgentCore라 명명하고 구현하였다.
PointLKCore와 ReAgentCore는 모두 “correspondence‑free” 방식, 즉 별도의 점‑대‑점 대응(correspondence) 과정을 거치지 않는 구조를 채택한다. 전통적인 정합 방법에서는 일반적으로 최근접 이웃 탐색(nearest‑neighbor search)을 통해 각 점에 대한 대응점을 찾는 과정이 가장 큰 연산 부하를 발생시키며, 이 단계가 전체 파이프라인의 병목 현상(bottleneck)으로 작용한다. 반면 제안된 두 코어는 특징 매칭 단계 자체를 생략하고, 추출된 전역 특징 벡터만을 이용해 변환 파라미터(transformation parameters)를 직접 예측함으로써 계산 복잡도를 급격히 낮춘다. 구체적으로 PointLKCore는 기존 PointLK 알고리즘을 FPGA 친화적으로 재구성하여 반복적인 선형화(linearization)와 최소 제곱법(least‑squares) 연산을 하드웨어 수준에서 병렬 처리하고, ReAgentCore는 최근 제안된 ReAgent 프레임워크의 핵심 연산을 고정소수점(fixed‑point) 형태로 변환하여 메모리 대역폭 사용량을 최소화한다.
제안된 가속 코어들은 Xilinx ZCU104 보드에 실제로 구현되었으며, 합성(synthetic) 데이터셋과 실제 환경에서 수집된 실측 데이터셋 모두에 대해 광범위한 평가를 수행하였다. 실험 결과는 다음과 같은 두드러진 장점을 보여준다. 첫째, 실행 시간(runtime) 측면에서 ARM Cortex‑A53 기반 CPU에 비해 44.08배에서 45.75배 정도 빠르게 동작한다. 둘째, 동일한 정합 작업을 수행하는 Intel Xeon 서버급 CPU와 Nvidia Jetson 임베디드 GPU에 비해 각각 1.98배에서 11.13배 정도의 속도 향상을 달성하였다. 셋째, 전력 소비량은 1와트 이하로 매우 낮으며, 이는 Nvidia GeForce GPU 대비 163.11배에서 213.58배에 달하는 에너지 효율성을 의미한다. 이러한 수치는 모두 “실시간(real‑time)” 수준의 성능을 만족한다는 것을 의미한다. 실제로 제안된 시스템은 초기 변환 오차(initial misalignment)가 크게 존재하거나, 점 구름에 잡음(noise)이 많이 포함된 경우에도 견고하게 동작한다. 실험에 사용된 다양한 잡음 레벨과 회전·이동 변환 범위에서, 기존의 ICP(Iterative Closest Point)와 같은 고전적 정합 알고리즘보다 월등히 낮은 정합 오류를 기록했으며, 15밀리초 이하의 짧은 시간 안에 합리적인 변환 파라미터를 찾아냈다.
요약하면, 본 논문에서 제안한 PointLKCore와 ReAgentCore는 저비용 임베디드 FPGA 환경에서도 고성능 점 구름 정합을 가능하게 하는 혁신적인 솔루션이다. 특징 추출기의 병렬·파이프라인 설계, correspondence‑free 접근 방식, 그리고 맞춤형 하드웨어 가속 구조를 결합함으로써, 기존 딥러닝 기반 정합 방법이 안고 있던 높은 연산 비용과 전력 소모 문제를 근본적으로 해소하였다. 앞으로는 이러한 가속 코어를 기반으로 다중 센서 융합(multi‑sensor fusion)이나 SLAM(Simultaneous Localization and Mapping)과 같은 보다 복합적인 로봇 비전 파이프라인에 적용함으로써, 자율 주행 차량, 드론, 휴머노이드 로봇 등 다양한 실시간 로봇 시스템에 널리 활용될 수 있을 것으로 기대한다.