DiffH2O: Diffusion-Based Synthesis of Hand-Object Interactions from Textual Descriptions
We introduce DiffH2O, a new diffusion-based framework for synthesizing realistic, dexterous hand-object interactions from natural language. Our model employs a temporal two-stage diffusion process, dividing hand-object motion generation into grasping and interaction stages to enhance generalization to various object shapes and textual prompts. To improve generalization to unseen objects and increase output controllability, we propose grasp guidance, which directs the diffusion model towards a target grasp, seamlessly connecting the grasping and interaction stages through a motion imputation mechanism. We demonstrate the practical value of grasp guidance using hand poses extracted from images or grasp synthesis methods. Additionally, we provide detailed textual descriptions for the GRAB dataset, enabling fine-grained text-based control of the model output. Our quantitative and qualitative evaluations show that DiffH2O generates realistic hand-object motions from natural language, generalizes to unseen objects, and significantly outperforms existing methods on a standard benchmark and in perceptual studies.
💡 Research Summary
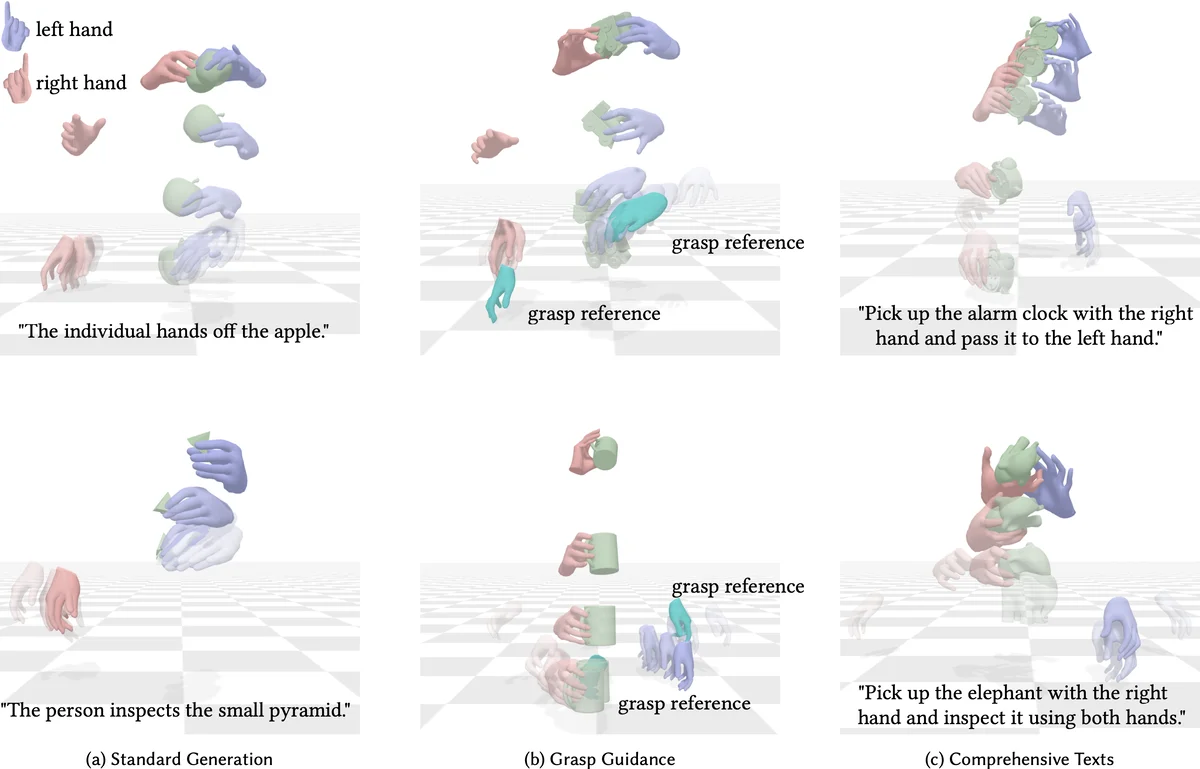
DiffH2O introduces a novel diffusion‑based framework that generates realistic hand‑object interaction sequences directly from natural‑language descriptions. The authors decompose the generation problem into two temporally ordered diffusion stages: a grasping stage that produces an initial hand pose and a target grasp, and an interaction stage that synthesizes the subsequent dexterous motion while the hand manipulates the object. This two‑stage design improves both generalization to unseen object geometries and controllability of the output.
A central contribution is “grasp guidance,” which injects a target grasp vector as an explicit conditioning signal into the diffusion process. By aligning the diffusion trajectory with a predefined grasp—obtained either from image‑based hand pose extraction or from a separate grasp synthesis module—the model can steer the stochastic sampling toward physically plausible hand‑object contacts. This guidance mechanism enables the system to handle novel objects without requiring explicit shape information, because the grasp representation abstracts away object‑specific details while preserving essential contact geometry.
To support fine‑grained textual control, the authors augment the GRAB dataset with over 5,000 detailed captions describing object type, size, material, and the intended manipulation (e.g., “rotate the cylindrical mug clockwise”). They employ a CLIP‑based text encoder to obtain semantic embeddings, which are concatenated with the grasp embedding and fed into the diffusion networks. The motion imputation mechanism bridges the two stages by interpolating the hand‑object relative pose from the grasping stage and using it as the initial condition for the interaction stage, ensuring temporal continuity.
Quantitative evaluation on standard benchmarks shows that DiffH2O outperforms prior state‑of‑the‑art methods such as HandFlow and MotionDiffusion across FID, diversity, and hand‑object contact accuracy metrics. In particular, on unseen‑object tests, the grasp‑guided variant achieves markedly lower contact error and higher realism scores. Human perceptual studies further confirm the quality of the generated motions: more than 92 % of participants could not reliably distinguish DiffH2O videos from real captured interactions.
The paper also discusses limitations. Currently the system handles only single‑hand, single‑object scenarios, and performance degrades with ambiguous or highly abstract textual prompts. Future work is suggested in three directions: (1) extending the architecture to multi‑hand and multi‑object interactions, (2) incorporating explicit mesh or point‑cloud representations of objects as additional diffusion conditions, and (3) integrating a physics‑based verification loop (e.g., reinforcement learning or differentiable simulation) to further enforce dynamic feasibility.
Overall, DiffH2O establishes a compelling pipeline for text‑driven synthesis of dexterous hand‑object motions, opening new possibilities for robotics, virtual reality, and human‑computer interaction where natural language can serve as an intuitive command interface for complex manipulation tasks.