Deep Learning Based Sphere Decoding
In this paper, a deep learning (DL)-based sphere decoding algorithm is proposed, where the radius of the decoding hypersphere is learned by a deep neural network (DNN). The performance achieved by the proposed algorithm is very close to the optimal m…
Authors: Mostafa Mohammadkarimi, Mehrtash Mehrabi, Masoud Ardakani
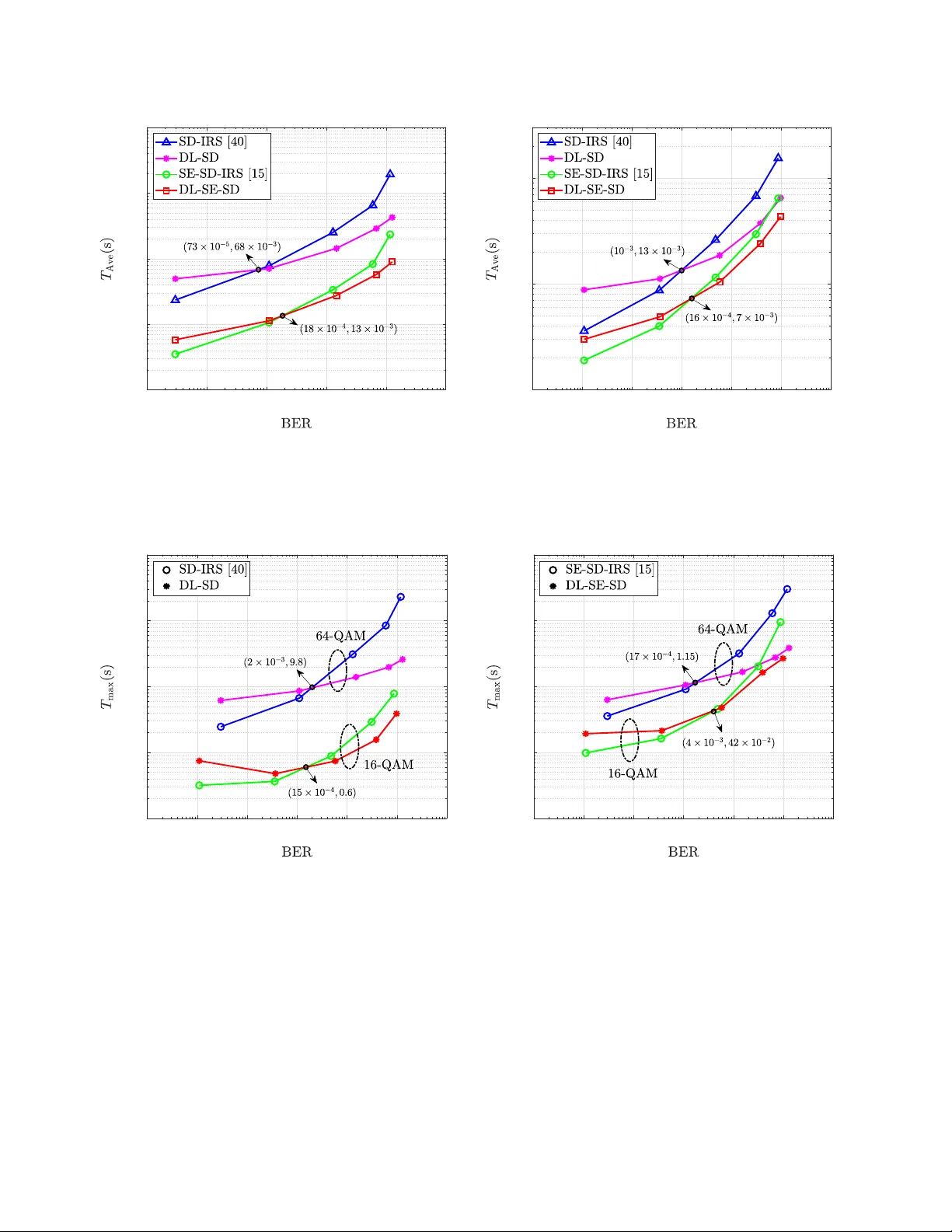
THIS P APER PUBLISHED IN IEEE TRANSA CTIONS ON WIRELESS COMMUNICA TIONS (DOI: 10.1109/TWC.2019.2924220). 1 Deep Learning Based Sphere Decoding Mostafa Mohammadkarimi, Member , IEEE , Mehrtash Mehrabi, Student Member , IEEE , Masoud Ardakani, Senior Member , IEEE , and Y indi Jing, Member , IEEE Abstract —In this paper , a deep learning (DL)-based sphere decoding algorithm is proposed, where the radius of the decoding hyperspher e is learned by a deep neural network (DNN). The performance achieved by the proposed algorithm is very close to the optimal maximum likelihood decoding (MLD) over a wide range of signal-to-noise ratios (SNRs), while the computational complexity , compared to existing sphere decoding variants, is significantly reduced. This impr ovement is attrib uted to DNN’ s ability of intelligently learning the radius of the hyperspher e used in decoding. The expected complexity of the pr oposed DL-based algorithm is analytically derived and compared with existing ones. It is shown that the number of lattice points inside the decoding hypersphere drastically reduces in the DL- based algorithm in both the av erage and worst-case senses. The effectiveness of the proposed algorithm is shown through simulation for high-dimensional multiple-input multiple-output (MIMO) systems, using high-order modulations. Index T erms —Sphere decoding, integer least-squares problem, maximum likelihood decoding, deep learning, deep neural net- work, multiple-input multiple-output, complexity analysis. I . I N T R O D U C T I O N T HE problem of optimum maximum likelihood decoding (MLD) in spatial multiplexing multiple-input multiple- output (MIMO) systems leads to an integer least-squares (LS) problem, which is equi v alent to finding the closest lattice point to a giv en point [ 1 ]–[ 3 ]. The integer LS problem is much more challenging compared to the con ventional LS problem, where the unknown vector is an arbitrary complex vector , and the solution is easily obtained through pseudo in v erse. This is because of the discrete search space of the integer LS problem which makes it NP hard in both the worst-case sense and the av erage sense [ 3 ]. V arious suboptimal solutions, such as zero-forcing (ZF) receiv er, minimum mean squared error (MMSE) receiver , nulling and cancelling (NC), NC with optimal ordering, have been proposed for the integer LS problem in MIMO systems with reduced computational complexity [ 4 ]. These solutions first solve the unconstrained LS problem and then perform simple rounding to obtain a feasible lattice point. While these solutions result in cubic-order complexity , their performance is significantly worse than the optimal solution. The idea of sphere decoding for MIMO detection was intro- duced in [ 5 ]. Sphere decoding suggests to confine the search space of the original integer LS problem to a hypersphere and implement a branch-and-bound search ov er a tree to achieve M. Mohammadkarimi, M. Mehrabi, M. Ardakani, and Y . Jing are with the Department of Electrical and Computer Engineering, Uni versity of Al- berta, Edmonton, AB, Canada. (e-mail: { mostafa.mohammadkarimi, mehrtash, ardakani,yindi } @ualberta.ca ). This research was supported by the Huawei Innov ation Research Program (HIRP). MLD performance. It can reduce the number of lattice points to be trialled, thus lower the complexity . Naturally , choosing an appropriate radius for the decoding hypersphere is crucial for sphere decoding. If the radius is too small, there might not be any lattice point inside the hypersphere. On the other hand, an overly large radius may result in too many lattice points in the hypersphere, hence increasing the decoding complexity . For example, the choice of radius based on the Babai estimate guarantees the existence of at least one lattice point inside the hypersphere [ 6 ]; ho wev er , it may lead to a large number of points within the hypersphere. T o achieve the exact MLD performance with reduced complexity , sphere decoding with increasing radius search (SD-IRS) was proposed in [ 3 ], [ 7 ]. Many variations of sphere decoding with reduced compu- tational complexity hav e also been proposed in the literature [ 8 ]–[ 17 ]. Complexity reduction in sphere decoding through lattice reduction, geometric and probabilistic tree pruning, and K -based lattice selection methods have been addressed in [ 8 ]– [ 17 ]. On the other hand, a few studies have addressed the problem of radius selection in sphere decoding [ 3 ], [ 6 ]. A method to determine the radius of the decoding hypersphere was proposed in [ 3 ]. The proposed algorithm chooses the radiuses based on the noise statistics; howe ver , it ignores the effect of the fading channel matrix. A modified version of radius selection based on Babai estimate has been dev eloped in [ 6 ]. The proposed method can solve the problem of sphere decoding failure due to rounding error in floating-point com- putations. T o take the advantage of sphere decoding for high- dimensional MIMO systems with high-order modulations and other applications, such as multi-user communications, mas- siv e MIMO, and relay communications [ 18 ]–[ 20 ], a promising solution is to develop an intelligent mechanism for radius selection to reduce computational complexity without perfor- mance degradation. Recent studies show that deep learning (DL) can provide significant performance improv ement in signal processing and communications problems [ 21 ]–[ 33 ]. Specifically , DL tech- niques ha ve been employed to improve certain parts of con ven- tional communication systems, such as decoding, modulation, and more [ 21 ]–[ 23 ]. These improvements are related to the intrinsic property of a deep neural network (DNN), which is a universal function approximator with superior logarithmic learning ability and conv enient optimization capability [ 34 ]– [ 36 ]. Besides, existing signal processing algorithms in commu- nications, while work well for systems with tractable mathe- matical models, can become inefficient for complicated and large-scale systems with large amount of imperfections and high nonlinearities. Such scenarios can be solved through DL, which can characterize imperfections and nonlinearities via well-structured approximations [ 25 ]–[ 27 ]. Moreov er , physical THIS P APER PUBLISHED IN IEEE TRANSA CTIONS ON WIRELESS COMMUNICA TIONS (DOI: 10.1109/TWC.2019.2924220). 2 layer communication based on the concept of autoencoder has been in vestigated in [ 28 ]–[ 33 ]. Specifically , the problem of MIMO detection through DL has been in vestigated in [ 26 ]–[ 29 ]. The authors in [ 26 ], [ 27 ] proposed the DetNet architecture for MIMO detection which can achiev e near MLD performance with lo wer computational complexity without any kno wledge regarding the SNR value. The joint design of encoder and decoder using DL autoencoder for MIMO systems was explored in [ 28 ]. The authors showed that autoencoder demonstrates significant potential, and its per - formance approaches the conv entional methods. The problem of MIMO detection in time-varying and spatially correlated fading channels w as inv estigated in [ 29 ]. The authors em- ployed DL unfolding to improve the iterativ e MIMO detection algorithms. Motiv ated by these facts, a sphere decoding algorithm based on DL is proposed in this paper , where the radius of the decoding hypersphere is learned by a DNN prior to decoding. The DNN maps a sequence of the fading channel matrix elements and the received signals at its input layer into a sequence of learned radiuses at its output layer . The DNN is trained in an off-line procedure for the desired signal-to-noise ratio (SNR) once and is used for the entire communication phase. Unlike the SD-IRS algorithm, the proposed DL-based al- gorithm restricts the number of sequential sphere decoding implementations to a maximum predefined value. Moreover , since the decoding radiuses are intelligently learnt by a DNN, the number of lattice points that lies inside the hypersphere remarkably decreases, which significantly reduces the com- putational complexity . On the other hand, the probability of failing to find a solution is close to zero. T o the best of our knowledge, this is the first work in the literature that proposes a mechanism for radius selection dependent on both the fading channel matrix and the noise statistics. The remaining of this paper is organized as follows. Section II briefly introduces the basics of DL and DNN. Section III presents the system model. Section IV describes the proposed DL-based sphere decoding algorithm. In Section V , an analyt- ical expression for the expected complexity of the proposed algorithm is deriv ed. Simulation results are pro vided in Section VI , and conclusions are drawn in Section VII . A. Notations Throughout the paper, ( · ) ∗ is used for the complex conju- gate, ( · ) T is used for transpose, ( · ) H is used for Hermitian, | · | represents the absolute value operator 1 ⌊·⌉ is the operation that rounds a number to its closest integer , ∅ denotes the empty set, E {·} is the statistical expectation, ˆ x is an estimate of x , the symbol I denotes the identity matrix, and the Frobenius norm of vector a is denoted by ∥ a ∥ . The inv erse of matrix A is denoted by A − 1 . ℜ{·} and ℑ{·} denote real and imaginary operands, respectively . The gradient operator is denoted by ∇ . The m -dimensional complex, real, and comple x integer spaces are denoted by C m , R m , and CZ m , respectiv ely . Finally , the circularly symmetric comple x 1 For the sets, it represents the cardinality . I np ut l a yer H i dde n l a ye r 1 H i dde n l a ye r 2 H i dde n l a ye r 3 O ut put l a ye r Fig. 1: A typical DNN with three hidden layers. Gaussian distribution with mean vector µ and covariance matrix Σ is denoted by C N µ , Σ , and U ( a, b ) represents the continues uniform distribution over the interval [ a, b ] . I I . D N N F O R D E E P L E A R N I N G Deep learning is a subset of artificial intelligence and machine learning that uses multi-layered nonlinear process- ing units for feature extraction and transformation. On the contrary to the conv entional machine learning techniques, the performance of the DL techniques significantly improve as the number of training data increases. Most of the modern DL techniques have been dev eloped based on artificial neural network and are referred to as DNN. A DNN is a fully connected feedforward neural network (NN) composed of sev eral hidden layers and the neurons between the input and output layers. It is distinguished from the con ventional NN by its depth, i.e., the number of hidden layers and the number of neurons. A larger number of hidden layers and neurons enables a DNN to extract more meaningful features and patterns from the data. From a mathematical point of vie w , a NN is a ”uni versal approximator”, because it can learn to approximate an y function z = Υ( x ) mapping the input vector x ∈ R m to the output vector z ∈ R n . By employing a cascade of L nonlinear transformations on the input x , a NN approximates z as z ≈ T ( L ) T ( L − 1) · · · T 1 ( x ; θ 1 ); θ L − 1 ; θ L , (1) with T ( ℓ ) x ; θ ℓ ≜ A ℓ W ℓ x + b ℓ , ℓ = 1 , · · · , L, (2) where θ ℓ ≜ W ℓ b ℓ denotes the set of parameters, W ℓ ∈ R n ℓ × n ℓ − 1 (where n 0 = m , n L = n ) and b ℓ ∈ R n ℓ represents the weights and biases, and A ℓ is the acti v ation function of the l th layer . The activ ation function is applied at each neuron to produce non-linearity . The weights and biases are usually learned through a training set with known desired outputs [ 35 ]. Fig. 1 shows a typical DNN with three hidden layers. THIS P APER PUBLISHED IN IEEE TRANSA CTIONS ON WIRELESS COMMUNICA TIONS (DOI: 10.1109/TWC.2019.2924220). 3 I I I . S Y S T E M M O D E L W e consider a spatial multiplexing MIMO system with m transmit and n receiv e antennas. The vector of receiv ed basedband symbols, y ∈ C n × 1 , in block-fading channels is modeled as y = Hs + w , (3) where s = [ s 1 , s 2 , · · · , s m ] T ⊂ CZ m denotes the vector of transmitted complex symbols drawn from an arbitrary constellation D , H ∈ C n × m is the channel matrix, and w ∈ C n × 1 is the zero-mean additive white Gaussian noise (A WGN) with covariance matrix Σ w = σ 2 w I . The channel from transmit antenna j to receiv e antenna i is denoted by h ij . The vector s spans the ”rectangular” m -dimensional com- plex integer lattice D m ⊂ CZ m , and the n -dimensional vector Hs spans a ”skewed” lattice for any given lattice-generating matrix H . W ith the assumption that H is perfectly estimated at the recei ver , MLD of the vector s in ( 3 ) giv en the observ ation vector y , leads to the following integer LS problem: min s ∈ D m ⊂ CZ m y − Hs 2 . (4) As seen, the integer LS problem in ( 4 ) is equiv alent to finding the closest point in the ske wed lattice Hs to the vector y in the Euclidean sense. For lar ge values of m and high-order modulation, exhausti ve search is computationally unaffordable. Sphere decoding can speed up the process of finding the optimal solution by searching only the points of the ske wed lattice that lie within a hypersphere of radius d centered at the vector y . This can be mathematically expressed as min s ∈ D m ⊂ CZ m ∥ y − Hs ∥ 2 ⩽ d 2 y − Hs 2 . (5) It is obvious that the closest lattice point inside the hypersphere is also the closest point for the whole lattice. The main problem in sphere decoding is how to choose d to av oid a large number of lattice points inside the hypersphere and at the same time guarantee the existence of a lattice point inside the hypersphere for any vector y . T o achieve MLD error performance, SD-IRS is required since for any hypersphere radius r i , there is always a non- zero probability that this hypersphere does not contain any lattice point. When no lattice point is av ailable, the search radius needs to be increased from r i to r i +1 , and the search is conducted again. This procedure continues until the optimal solution is obtained. While SD-IRS substantially improve on the complexity of MLD from an implementation standpoint, the av erage and worst-case complexity can still be huge when there are no lattice points in the hypersphere with radius r i , but many in the hypersphere with radius r i +1 . Hence, the choice of r i ’ s is critical. I V . D L - B A S E D S P H E R E D E C O D I N G The main idea behind our proposed DL-based sphere de- coding algorithm is to implement SD-IRS for a small number of intelligently learned radiuses. That is, r i ’ s are learned and chosen intelligently by a DNN. DL-based sphere decoding makes it possible to choose the decoding radiuses based on the noise statistics and the structure of H . This significantly increases the probability of successful MLD with searching ov er only a small number of lattice points. In the proposed DL-based sphere decoding, the Euclidean distance of the q closest lattice points to vector y in the ske wed lattice space is reconstructed via a DNN (as the DNN output) prior to sequential sphere decoding implementations. Then, these q learned Euclidean distances are used as radiuses of the hyperspheres in sphere decoding implementations. The value of q is chosen small due to computational complexity consideration. Ideally , if the distances are produced with no error , q = 1 is sufficient for the optimal decoding with the lowest complexity , since the radius is the distance of y to the optimal MLD solution. This radius for sphere decoding guarantees the existence of a point inside the hypersphere and actually only the optimal point is inside the hypersphere. Howe ver , since a DNN is an approximator, there is the possibility that no points lies within the hypersphere with the learned radius. Thus, instead of learning the closest distance only , q closest Euclidean distances are learnt by the DNN to increase the probability of finding the optimal lattice point. Since for any finite value of q , still there is the possibility that no lattice point lies within the hypersphere with the largest learned radius, a suboptimal detector , such as MMSE with rounding or NC with optimal ordering is employed in order to av oid failure in decoding. Let us define the Euclidean distance between y and the i th lattice point in the skewed lattice, i.e., Hs i , as r i ≜ y − Hs i , i = 1 , 2 , · · · , | D | m , (6) where | D | is the cardinality of the constellation D . Further , by ordering r i as follows, r i 1 < r i 2 < · · · < r i q < r i q +1 < · · · < r i | D | m , (7) the desired q × 1 radius vector r is giv en as r ≜ [ r i 1 r i 2 · · · r i q ] T . (8) In the proposed DL-based sphere decoding algorithm, the DNN, Φ( x ; θ ) , reconstructs the radius vector r at its output layer as ˆ r = Φ( x ; θ ) , (9) where x ≜ h ¯ y ˜ y ¯ h 11 ˜ h 11 · · · ¯ h nm ˜ h nm i T , (10) ¯ y = ℜ{ y T } , ˜ y = ℑ{ y T } , h uv ≜ ¯ h uv + i ˜ h uv , and θ ≜ [ θ 1 , θ 2 , · · · , θ K ] T . The vector x represents the input vector of the DNN, and θ is the vector of all parameters of the DNN. The proposed DL-based sphere decoding is composed of an off-line training phase, where the parameters of the DNN is obtained by employing training examples, and a decoding phase where the transmit vector is decoded through sphere decoding or a suboptimal detector . In the following subsection, these two phases are explained in details. THIS P APER PUBLISHED IN IEEE TRANSA CTIONS ON WIRELESS COMMUNICA TIONS (DOI: 10.1109/TWC.2019.2924220). 4 Algorithm 1 DL-based sphere decoding algorithm Input: y , H , Φ( · , θ ) , q Output: ˆ s 1: Stack y and H as in ( 10 ) to obtain x ; 2: Obtain the q radiuses through the trained DNN as ˆ r = Φ( x , θ ) = [ ˆ r i 1 ˆ r i 2 · · · ˆ r i q ] T ; 3: c = 1 ; 4: Implement sphere decoding for radius ˆ r i c ; 5: if D sp ( y , ˆ r i c ) = null 6: ˆ s = D sp ( y , ˆ r i c ) ; 7: else if c < q 8: c = c + 1 and go to 4; 9: else 10: ˆ s = D sb ( y ) ; 11: end 12: end T able I: Layout of the employed DNN. Layer Output Dimension Parameters Input 220 0 Dense + CRelu 128 28,288 Dense q 129 × q A. T raining Phase A three layers DNN with one hidden layer is considered for a 10 × 10 spatial multiplexing MIMO system using 16 - QAM and 64 -QAM in the training phase, 2 where the numbers of neurons in each layers are 220 , 128 , and q , respectiv ely . Clipped rectified linear unit with the following mathematical operation is used as the activ ation function in the hidden layers: f ( u ) = 0 , u < 0 . u, 0 ⩽ u < 1 1 , u ⩾ 1 . (11) T able I summarizes the architecture of the employed DNN for the 10 × 10 spatial multiplexing MIMO system in this paper . It should be mentioned that an SNR dependent DNN, in which the structure of the DNN is designed to be adaptiv e to the SNR v alue, can also be employed to further reduce computational complexity . For the sake of simplicity , a fixed DNN is used for all SNR v alues in this paper . Howe v er , the network is independently trained for each SNR value. In the training phase, the designed DNN is trained with independent input vectors, given as x ( i ) ≜ h ¯ y ( i ) ˜ y ( i ) ¯ h ( i ) 11 ˜ h ( i ) 11 · · · ¯ h ( i ) nm ˜ h ( i ) nm i T (12) for i = 1 , 2 , · · · , N to obtain the parameter vector θ of the DNN by minimizing the following mean-squared error (MSE) loss function [ 28 ]: Loss ( θ ) ≜ 1 N N X i =1 r ( i ) − Φ( x ( i ) ; θ ) 2 , (13) 2 Based on the MIMO configuration and modulation type, different DNN architecture can be selected. where r ( i ) is the desired radius vector when x ( i ) is used as input vector . T o achieve faster con ver gence and decrease computational complexity , an approximation of the MSE loss function in ( 13 ) is computed for random mini-batches of training examples at each iteration t as f t ( θ ) ≜ 1 M M X i =1 r ( M ( t − 1)+ i ) − Φ( x ( M ( t − 1)+ i ) ; θ ) 2 , (14) where M is the mini-batch size, and B = N / M is the number of batches. The training data is randomly shuffled before every epoch. 3 By choosing M to be considerably small compared to N , the complexity of the gradient computation for one epoch, i.e., ∇ θ f t ( θ t − 1 ) , t = 1 , 2 , · · · , B , remarkably decreases when compared to ∇ θ Loss ( θ ) , while the variance of the parameter update still decreases. During the training phase, for each SNR value, elements of the transmitted vector s ( i ) , elements of the fading channel matrix H ( i ) , and elements of the noise vector w ( i ) , i = 1 , · · · , N , are independently and uniformly drawn from D , f h ( h ) , and C N 0 , σ 2 w , respectively , where f h ( h ) denotes the distribution of the fading channel. Then, the real and imaginary parts of the observ ation vectors during training, i.e., y ( i ) = H ( i ) s ( i ) + w ( i ) , along with H ( i ) are stacked as in ( 12 ) and fed to the DNN to minimize the MSE loss function in ( 14 ). For each input training vector x ( i ) , the corresponding desired radius vector r ( i ) is obtained by employing SD-IRS with a set of heuristic radiuses. Finally , the parameter vector of the DNN is updated according to the input-output vector pairs ( x ( i ) , r ( i ) ) by employing the adapti ve moment estimation stochastic optimization algorithm, which is also referred to as Adam algorithm [ 37 ]. Since the DNN in our algorithm is used as a function approximator , the DNN does not need to see all possible codew ords in the training phase. The DNN only approximates the region in which the optimal solution exists. Hence, the number of training samples, and thus, the computational complexity of the training can be linearly scaled up by the cardinality of constellation. B. Decoding Procedur e In the decoding phase, first, the recei ved v ector y and fading channel matrix H are fed to the trained DNN in the form of ( 10 ) to produce the radius vector ˆ r ≜ [ ˆ r i 1 ˆ r i 2 · · · ˆ r i q ] T ; then, the transmitted signal vector is decoded by Algorithm 1 , where sphere decoding is conducted recursively with the learned radiuses by the DNN, followed by a suboptimal detection if the sphere decoding fails to find the solution. Sphere decoding implementation with decoding radius ˆ r i c fails to find a solution when C ( y , ˆ r i c ) ≜ n s ∈ D m y − Hs 2 ≤ ˆ r 2 i c o = ∅ (17) 3 Each epoch is one forward pass and one backward pass of all the training examples. THIS P APER PUBLISHED IN IEEE TRANSA CTIONS ON WIRELESS COMMUNICA TIONS (DOI: 10.1109/TWC.2019.2924220). 5 that is, there is no lattice point inside the hypersphere with radius ˆ r i c . T o help the presentation, define D sp ( y , ˆ r i c ) ≜ min s ∈ D m ⊂ CZ m ∥ y − Hs ∥ 2 ⩽ ˆ r 2 i c y − Hs 2 , if C ( y , ˆ r i c ) = ∅ null , if C ( y , ˆ r i c ) = ∅ . (18) On the other hand, if no point is found by the q rounds of sphere decoding, MMSE is employed as the suboptimal detector , in which the solution is obtained as D sb ( y ) = j ( H H H + ¯ γ − 1 I ) − 1 H H y m , (19) where ¯ γ is the average SNR. Simulation result show that due to the intelligent production of the radiuses via a DNN, the probability of decoding through suboptimal detector is very close to zero. C. Intuition behind DL-based Spher e Decoding Since the complexity of sphere decoding algorithm is data dependent (depends on y and H ), data dependent hypersphere radius selection can lead to lower computational complexity [ 3 ], [ 38 ]. The proposed DL-based sphere decoding algorithm selects the hypersphere radiuses dependent on y and H to reduce computational complexity . The NN in the proposed DL-based sphere decoding behav es as a function approximator . In the mathematical theory of artificial neural networks, the uni versal approximation theorem states [ 34 ] that a feed-forward network with a single hidden layer containing a finite number of neurons can provide an arbitrarily close approximation to a continuous function f ( x ) , on compact subsets of R n , under mild assumptions on the activ ation function. A formal description of this theorem is provided below . Theorem IV .1. (Universal Approximation Theorem): Let φ ( · ) R → R be a nonconstant, bounded and continuous function. Then, given any ϵ > 0 and any function f : I m → R , wher e I m is a compact subset of R m , ther e exist an inte ger N , r eal constants v i , b i ∈ R , and real vectors w i ∈ R m for i = 1 , · · · , N , suc h that | F ( x ) − f ( x ) | < ϵ, (20) wher e F ( x ) = N X i =1 v i φ w T i x + b i . (21) F ( x ) is an appr oximate realization of the function f . This r esult holds even if the function has many outputs. A visual pr oof that NN can approximates any continues function is pr ovided in [ 36 ], [ 39 ]. Based on this theorem, the employed NN in our algorithm approximates the function r = g ( y , H ) , R 2 n ( m +1) → R q , where g ( y , H ) ≜ [ g 1 ( x , H ) g 2 ( x , H ) · · · g q ( x , H )] T and g i ( x , H ) is the distance of the i closest lattice points to vector y , i.e., g i ( y , H ) = y − H ˆ s i 2 , i = 1 , 2 , · · · , q , (22) where g 1 ( y , H ) ⩽ g 2 ( y , H ) ⩽ · · · ⩽ g q ( y , H ) and ˆ s i = min s ∈ D m ⊂ CZ m s ∈{ ˆ s 1 , ··· , ˆ s i − 1 } y − Hs 2 . (23) The reason that non-linear function g is learned is to gradually and in a controlled manner increase the hypersphere radius to a void too many lattices inside the search hyperspheres. The learned NN makes data dependent radius selection, and thus, reduces the number of lattice points that fall in the hyperspheres. It is worth noting that the complexity of sphere decoding is proportional to the number of lattice points that lies inside the hypersphere [ 3 ]. V . E X P E C T E D C O M P L E X I T Y O F T H E D L - B A S E D S P H E R E D E C O D I N G In this section, the expected complexity of the proposed DL-based sphere decoding algorithm in the decoding pahse is analytically deriv ed. Since the DNN is trained once and is used for the entire decoding phase, the expected complexity of the training phase is not considered. Lemma 1. The expected complexity of the pr oposed DL-based spher e decoding algorithm is obtained as C DL ( m, σ 2 ) = q X c =1 m X k =1 ∞ X v =0 F sp ( k )Ψ 2 k ( v ) (24) × E ( γ ˆ r 2 i c σ 2 w + v , n − m + k γ ˆ r 2 i c σ 2 w , n − γ ˆ r 2 i c − 1 σ 2 w , n ) + 1 − E γ ˆ r 2 i q σ 2 w , n F sb + F dn , wher e ˆ r i 0 = 0 , γ ( · , · ) is the lower incomplete gamma function, Ψ 2 k ( v ) is the number of ways that v can be r epr esented as the sum of 2 k squar ed inte gers, F sb = m 3 + 5 m 2 2 + nm 2 + 3 mn − m 2 , (25) F dn = L − 1 X i =0 2 n i +1 n i , (26) and F sp ( k ) is the number of elementary operations includ- ing complex additions, subtractions, and multiplications per visited point in complex dimension k in sphere decoding. Pr oof. See the appendix. As seen from the proof in the appendix, F sb and F dn represents the number of elementary operations employed by the MMSE suboptimal detector in ( 19 ) and DNN, respectively . Also, the term γ ( ˆ r 2 i c / σ 2 w , n ) in ( 24 ) is the probability of finding at least a lattice point inside the hypersphere with the learned radius ˆ r i c , which is written as ˆ p i c ≜ γ ˆ r 2 i c σ 2 w , n = Z ˆ r 2 i c σ 2 w 0 t n − 1 Γ( n ) exp( − t ) dt, (27) where ˆ p i 0 = 0 . By replacing the statistical expectation with sample mean based on Monte Carlo sampling, one can write the expected THIS P APER PUBLISHED IN IEEE TRANSA CTIONS ON WIRELESS COMMUNICA TIONS (DOI: 10.1109/TWC.2019.2924220). 6 C DL ( m, σ 2 ) = lim U →∞ 1 U U X u =1 q X c =1 m X k =1 ∞ X v =0 F sp ( k )Ψ 2 k ( v ) × γ ˆ r 2 i c ,u σ 2 w + v , n − m + k γ ˆ r 2 i c ,u σ 2 w , n − γ ˆ r 2 i c − 1 ,u σ 2 w , n + m 3 + 5 m 2 2 + nm 2 + 3 mn − m 2 1 − 1 U U X u =1 γ ˆ r 2 i q ,u σ 2 w , n + F dn . (28) complexity of the DL-based algorithm as in ( 28 ), where the subscript u represents the index of sample in importance sampling. For M 2 -QAM constellation, F sp ( k ) = 8 k + 20 + 4 M , and Ψ 2 k ( v ) for 4-QAM, 16-QAM, and 64-QAM is respectively giv en as [ 40 ] Ψ 2 k ( v ) = ( 2 k v , if 0 ⩽ v ⩽ 2 k 0 otherwise , (29) Ψ 2 k ( v ) = 2 k P j =0 1 2 2 k 2 k j Ω 2 k,j ( v ) , if v ∈ Ξ 0 otherwise , (30) and Ψ 2 k ( v ) = P ξ 0 ,ξ 1 ,ξ 2 ,ξ 3 1 4 2 k Ω 2 k,ξ 0 ,ξ 1 ,ξ 2 ,ξ 3 ( v ) , if v ∈ Q 0 , otherwise (31) where Ω 2 k,j ( v ) is the coefficient of λ v in the polynomial (1 + λ + λ 4 + λ 9 ) j (1 + 2 λ + λ 4 ) 2 k − j , (32) the set Ξ contains the coefficients of the polynomial in ( 32 ) for k = 1 , · · · , m and j = 0 , · · · , 2 k , Ω 2 k,ξ 0 ,ξ 1 ,xi 2 ,xi 3 ( v ) is the coefficient of λ v in the polynomial 2 k ξ 0 , ξ 1 , ξ 2 , ξ 3 7 X e 0 =0 λ e 2 0 ξ 0 λ + 6 X e 1 =0 λ e 2 1 ξ 1 (33) × λ + λ 4 + 5 X e 2 =0 λ e 2 2 ξ 2 − 1 − λ 16 + 4 X e 3 =0 2 λ e 2 3 ξ 3 , where ξ 0 + ξ 1 + ξ 2 + ξ 3 = 2 k , 2 k ξ 0 ,ξ 1 ,ξ 2 ,ξ 3 = (2 k )! / ( ξ 0 ! ξ 1 ! ξ 2 ! ξ 3 !) , and the set Q contains the coefficients of the polynomial in ( 33 ) for k = 1 , · · · , m . A. Asymptotic Complexity Analysis As the SNR approaches + ∞ , the A WGN noise can be ignored. In this case, the expected complexity of the proposed DL-based sphere decoding algorithm in ( 24 ) is simplified as C DL ( m, 0) (34) = m 3 + 5 m 2 2 + nm 2 + 3 mn − m 2 + L − 1 X i =0 2 n i +1 n i . Since the number of neurons in the hidden layer is linearly scaled up the size of the input layer 2( m ( n + 1)) , the complexity order of the proposed algorithm for large MIMO systems ( n ⩾ m >> 1) , is O ( m 2 n 2 ) . T able II: Training phase parameters. Parameter 16-QAM 64-QAM Number of batches 90 90 Size of batches 200 200 Number of epoches 20 23 Number of iterations 1800 2070 V I . S I M U L AT I O N R E S U LT S In this section, we ev aluate the performance of the proposed DL-based sphere decoding algorithm through se veral simula- tion experiments. A. Simulation Setup W e consider a 10 × 10 spatial multiplexing MIMO system in Rayleigh block-fading channel where 16 -QAM and 64 − QAM are employed. These configurations result in skewed lattices with 4 20 and 4 30 lattice points, respectiv ely . The elements of the fading channel matrix are modeled as independent and identically distributed (i.i.d.) zero-mean circularly symmetric complex Gaussian random variables with unit v ariance. The additiv e white noise is modeled as a circularly symmetric complex-v alued Gaussian random v ariable with zero-mean and variance σ 2 w for each recei ve antennas. W ithout loss of general- ity , the av erage SNR in dB is defined as γ ≜ 10 log mσ 2 s / σ 2 w , where σ 2 s is the average signal power , and m is the number of transmit antennas. The NN is implemented using Deep learning T oolbox of MA TLAB 2019a. The learning rate of the Adam optimization algorithm is set to 0.001, and the parameters of the employed NN in the training phase are given in T able II : Unless otherwise mentioned, q = 3 is considered, and MMSE is employed as the suboptimal detector . The perfor- mance of the proposed DL-based sphere decoding algorithm in terms of bit error rate (BER) and computational complexity is obtained from 10 6 Monte Carlo trials for each SNR value. The performance comparison of the DL-based sphere de- coding algorithm with SD-IRS algorithm in [ 40 ] and its Schnorr-Euchner (SE) variate with SE-SD-IRS in [ 15 ] are performed with the same sets of fading channel matrixes, transmit vectors, and noise vectors. For fair comparison, it is considered that SE-SD-IRS uses q radiuses, and then switches to MMSE decoding after q times radius increasing. The decoding hypersphere radiuses for SD-IRS and SE-SD-IRS were obtained for p c ( i ) = 1 − 0 . 01 i at the i th sphere decoding implementation as suggested in [ 40 ]. B. Simulation Results Fig. 2 shows the underlaying empirical PDF of the radiuses learnt by the designed NN at γ = 24 dB for 64 -QAM. As THIS P APER PUBLISHED IN IEEE TRANSA CTIONS ON WIRELESS COMMUNICA TIONS (DOI: 10.1109/TWC.2019.2924220). 7 (a) EPDF of ˆ r 1 (b) EPDF of ˆ r 2 (c) EPDF of ˆ r 3 Fig. 2: The empirical probability density function (PDF) of the radiuses learnt by the designed NN at γ = 24 dB for 64 -QAM. expected, the radiuses vary based on the inputs of the NN. This implies that the radiuses are intelligently adjusted to the channel state information and receiv ed signals. Fig. 3 illustrates the BER of the proposed DL-based sphere decoding algorithm and its SE variate versus the average 20 22 24 26 28 10 -5 10 -4 10 -3 10 -2 10 -1 10 0 (a) 64-QAM 14 16 18 20 22 10 -5 10 -4 10 -3 10 -2 10 -1 10 0 (b) 16-QAM Fig. 3: Performance comparison of the proposed DL-based sphere decoding algorithm and its SE variate ( q = 3 ), the SD-IRS [ 40 ], and SE-SD-IRS in [ 15 ]. SNR. As seen, the proposed DL-based algorithm exhibits BER performance close to that in SD-IRS (MLD) ov er a wide range of SNRs. This behaviour shows that sequential sphere decoding implementation with the learned radiuses reaches the optimal solution. Fig. 4 illustrates the average decoding time of the pro- posed DL-based sphere decoding algorithm and its SE variate versus BER. As seen, the average decoding time in DL- based algorithm is significantly lower than SD-IRS [ 40 ] when BER > 73 × 10 − 5 for 64 -QAM, and when BER > 10 − 3 for 16 -QAM. Also, as seen, the SE variate of the proposed DL- based algorithm outperforms SE-SD-IRS [ 15 ] when BER > 18 × 10 − 4 for 64 -QAM, and when BER > 16 × 10 − 4 for 16 - QAM. The reason for this reduction in comple xity is that the number of lattice points inside the decoding hypersphere, and thus the size of the search tree decreases in the av erage sense THIS P APER PUBLISHED IN IEEE TRANSA CTIONS ON WIRELESS COMMUNICA TIONS (DOI: 10.1109/TWC.2019.2924220). 8 10 -5 10 -4 10 -3 10 -2 10 -1 10 0 10 -3 10 -2 10 -1 10 0 10 1 (a) 64-QAM 10 -6 10 -5 10 -4 10 -3 10 -2 10 -1 10 0 10 -3 10 -2 10 -1 (b) 16-QAM Fig. 4: A verage decoding time versus BER. The corresponding SNR of markers (left to right) for 64-QAM and 16-QAM are { 28 , 26 , 24 , 22 , 20 } dB and { 22 , 20 , 18 , 16 , 14 } dB, respectively . 10 -6 10 -5 10 -4 10 -3 10 -2 10 -1 10 0 10 -1 10 0 10 1 10 2 10 3 (a) 10 -6 10 -5 10 -4 10 -3 10 -2 10 -1 10 0 10 -2 10 -1 10 0 10 1 10 2 (b) Fig. 5: Maximum decoding time versus BER. The corresponding SNR of markers (left to right) for 64-QAM and 16-QAM are { 28 , 26 , 24 , 22 , 20 } dB and { 22 , 20 , 18 , 16 , 14 } dB, respectively . when the radiuses of the hyperspheres are intelligently learnt by a DNN. On the other hand, the SD-IRS [ 40 ] and SE-SD- IRS [ 15 ] exhibit a lower computational complexity compared to the proposed DL-based algorithm and its SE variate at very low BER regions (high SNRs). The reason is that at high SNR values, it is unlikely for the lattice to collapse in one or more dimension, an ev ent that significantly increases the number of points in the hypersphere for the scheme in [ 40 ] and [ 15 ]. One possible way to improve the proposed method is to consider SNR-based DNN, especially at high SNR values. Fig. 5 shows the maximum decoding time in the proposed DL-based algorithm and its SE v ariate versus BER to that in the SD-IRS algorithm [ 40 ] and SE-SD-IRS [ 15 ]. As seen, the DL-based sphere decoding algorithms outperform the algo- rithm in [ 40 ] and [ 15 ] for some regions, i.e., BER > 2 × 10 − 3 for DL-SD and BER > 17 × 10 − 4 for DL-SE-SD when using 64 -QAM. These regions for 16 -QAM are BER > 15 × 10 − 4 and BER > 4 × 10 − 3 , respectiv ely . This shows that the size of the search tree in the DL-based sphere decoding is much smaller than the one in the algorithm in [ 40 ] and [ 15 ] in the worst-case sense. While at lo wer BERs (higher SNRs) SD-IRS and SE- THIS P APER PUBLISHED IN IEEE TRANSA CTIONS ON WIRELESS COMMUNICA TIONS (DOI: 10.1109/TWC.2019.2924220). 9 14 16 18 20 22 10 -5 10 -4 10 -3 10 -2 10 -1 10 0 Fig. 6: Performance of the proposed DL-based sphere decoding algorithm for 16 -QAM and q = 3 in the presence of spatial correlation mismatch in the training and decoding phases. 14 16 18 20 22 10 -5 10 -4 10 -3 10 -2 10 -1 10 0 Fig. 7: Performance of the proposed DL-based sphere decoding algorithm for 16 -QAM and q = 3 in the presence of channel estimation error . SD-IRS of fer a lower complexity compared to our proposed solutions, one should note that the presented figures represents BER in the absence of channel coding. In practice, when lower BERs are needed, channel coding is used. Hence, for the practical range of moderate BER before channel coding, our proposed solution offers a better complexity . Fig. 6 shows the BER of the proposed DL-based algorithm for 16 -QAM and q = 3 in the presence of distribution mis- match. It is assumed that the DNN is trained for independent fading channel; ho wev er , it is ev aluated in the presence of correlated fading channel. As seen, the proposed algorithm is robust to spatial correlation fading for ρ = 0 . 1 and ρ = 0 . 2 , where ρ is the complex correlation coefficient of neighboring transmit and receive antennas. Fig. 7 shows the BER of the proposed DL-based algorithm for 16 -QAM and q = 3 in the presence of channel estimation error . It is assumed that the real and imaginary parts of the estimated fading channel ˆ h ij are randomly drawn form uniform distribution as ℜ{ ˆ h ij } ∈ U (1 − α ) ℜ{ h ij } , (1 + α ) ℜ{ h ij } ℑ{ ˆ h ij } ∈ U (1 − α ) ℑ{ h ij } , (1 + α ) ℑ{ h ij } , where h ij is the true value of channel, and α is a param- eter used to control channel estimation error . The effect of channel estimation error on the BER for three values of α ∈ { 0 . 05 , 0 . 1 , 0 . 2 } is sho wn in Fig. 7 . As expected, the performance of sphere decoding (DL and IRS) depends on the accuracy of channel estimation. Thus, a lo wer α results in a lower performance degradation. In addition, as seen, the performance of the proposed DL-based algorithm is robust to the channel estimation error when α < 0 . 1 . In Fig. 8 , the average number of lattice points (in the logarithmic scale) falling inside the decoding hypersphere in the DL-based sphere decoding algorithm is compared with the one in the SD-IRS algorithm in [ 40 ]. As seen, the average number of lattice points in the DL-based algorithms is belo w 0 . 545 (in the non logarithmic scale, bello w 3 . 51 ), while this is much higher in the SD-IRS algorithm. V I I . C O N C L U S I O N A low-comple xity solution for integer LS problems based on the capabilities of DL and sphere decoding algorithm was proposed in this paper . The proposed solution leads to efficient implementation of sphere decoding for a small set of intelligently learned radiuses. The BER performance of the DL-based sphere decoding algorithm is very close to that in MLD for high-dimensional integer LS problems with significantly lower computational complexity . The expected complexity of the proposed algorithm based on the elementary operations was derived, and its effecti veness in term of BER and computational comple xity for high-dimensional MIMO communication systems, using higher-order modulations, was shown through simulation. While the integer LS problem in this paper was formulated for MIMO communication systems, it is a promising solution for other situations when integer LS problems are encountered, such as multi-user communications, relay communications, global positioning system, and more. A C K N OW L E D G E M E N T S The authors are grateful to the anonymous revie wers and the Editor , Dr . Xiangyun Zhou, for their constructi ve comments. A P P E N D I X A The expected complexity of sphere decoding implementa- tion for radius d is gi ven as [ 40 ] C ( m, σ 2 w , d ) = m X k =1 F sp ( k ) ∞ X v =0 γ d 2 σ 2 w + v , n − m + k Ψ 2 k ( v ) . (35) THIS P APER PUBLISHED IN IEEE TRANSA CTIONS ON WIRELESS COMMUNICA TIONS (DOI: 10.1109/TWC.2019.2924220). 10 20 22 24 26 28 0 1 2 3 4 5 (a) 64-QAM 14 16 18 20 22 0 0.5 1 1.5 2 2.5 3 3.5 4 (b) 16-QAM Fig. 8: The average number of lattice points (in the logarithmic scale) falling inside the search hypersphere in the DL-based sphere decoding algorithm and the SD-IRS algorithm in [ 40 ]. By employing ( 35 ) and followi ng the same procedure as in [ 40 ], the expected complexity of the SD-IRS algorithm for r 1 < r 2 < · · · < r q is obtained as C ( m, σ 2 w , r 1 , · · · , r q ) = q X c =1 ( p c − p c − 1 ) m X k =1 F sp ( k ) (36) × ∞ X v =0 γ r 2 c σ 2 w + v , n − m + k Ψ 2 k ( v ) , where p 0 = 0 , and p c , 0 < c ⩽ q , is the probability of finding at least a lattice point inside the hypersphere with radius r c , which is obtained by replacing r c with ˆ r i c in ( 27 ). The probability that a solution is not found during the sphere decoding implementation for the hypeespheres with radiuses r 1 , r 2 , · · · , r q equals (1 − p q ) . Hence, the proposed DL-based sphere decoding algorithm obtains the solution through a suboptimal detector with probability (1 − p q ) . This leads to (1 − p q ) F sb additional av erage complexity giv en a suboptimal detector with F sb elementary operations. For the MMSE detector in ( 19 ), the number of elementary operations of ( H H H + ¯ γ − 1 I ) is nm 2 + m ( n − m 2 )+ m 2 , the matrix in version in ( 19 ) requires m 3 + m 2 + m elementary operations, H H y requires m (2 n − 1) elementary operations, and the product of ( H H H + ¯ γ − 1 I ) − 1 and H H y requires 2 m 2 − m elementary operations [ 41 ]. Thus, the total elementary operations in the MMSE detection is giv en as in ( 25 ). Moreov er , there is F dn elementary operations due to the DNN computations. The number of multiplication and addition in the ℓ th layer of a DNN with n ℓ neurons is 2 n ℓ n ℓ − 1 , where n ℓ − 1 is the number of neurons in the ( ℓ − 1) th layer . Hence, for a L -layer DNN with n 0 , · · · n L neurons in each layer , F dn is giv en as in ( 26 ). By employing ( 36 ) and including (1 − p q ) F sb and F dn , the e xpected comple xity of the proposed DL-based sphere decoding algorithm gi ven the learned radiuses ˆ r i 1 , · · · , ˆ r i q is obtained as C DL ( m, σ 2 w , ˆ r i 1 , · · · , ˆ r i q ) = q X c =1 ( ˆ p i c − ˆ p i c − 1 ) m X k =1 F sp ( k ) × ∞ X v =0 γ ˆ r 2 i c σ 2 w + v , n − m + k Ψ 2 k ( v ) + (1 − ˆ p i q ) F sb + F dn , (37) where ˆ p i c is gi ven in ( 27 ). Finally , since ˆ r i 1 , · · · , ˆ r i q and thus ˆ p i 1 , · · · , ˆ p i q are random variables, one can write the expected complexity of the DL-based sphere decoding as in ( 24 ). R E F E R E N C E S [1] J. Jalden and P . Elia, “Sphere decoding complexity exponent for decod- ing full-rate codes over the quasi-static MIMO channel, ” IEEE Tr ans. Inf. Theory , vol. 58, no. 9, pp. 5785–5803, Sep. 2012. [2] J. Mietzner , R. Schober , L. Lampe, W . H. Gerstacker , and P . A. Hoeher , “Multiple-antenna techniques for wireless communications-a comprehensiv e literature survey , ” IEEE Commun. Surveys T uts. , vol. 11, no. 2, Sencond quarter 2009. [3] B. Hassibi and H. V ikalo, “On the sphere-decoding algorithm I. expected complexity , ” IEEE T rans. Signal Pr ocess. , vol. 53, no. 8, pp. 2806–2818, Aug. 2005. [4] B. Hassibi, “ An ef ficient square-root algorithm for BLAST, ” in Proc. ICASSP , vol. 2. IEEE, Aug. 2000, pp. 737–740. [5] E. V iterbo and J. Boutros, “ A universal lattice code decoder for fading channels, ” IEEE T rans. Inf. Theory , vol. 45, no. 5, pp. 1639–1642, Jul. 1999. [6] F . Zhao and S. Qiao, “Radius selection algorithms for sphere decoding, ” in in Pr oc. CSSE , Montreal, Canada, May 2009, pp. 169–174. [7] B. M. Hochwald and S. T en Brink, “ Achieving near-capacity on a multiple-antenna channel, ” IEEE Tr ans. Commun. , vol. 51, no. 3, pp. 389–399, 2003. [8] E. Agrell, T . Eriksson, A. V ardy , and K. Zeger, “Closest point search in lattices, ” IEEE T rans. Inf. Theory , vol. 48, no. 8, pp. 2201–2214, Aug. 2002. [9] A. M. Chan and I. Lee, “ A new reduced-complexity sphere decoder for multiple antenna systems, ” in proc. ICC , New Y ork, USA, Apr . 2002, pp. 460–464. THIS P APER PUBLISHED IN IEEE TRANSA CTIONS ON WIRELESS COMMUNICA TIONS (DOI: 10.1109/TWC.2019.2924220). 11 [10] L. G. Barbero and J. S. Thompson, “Fixing the complexity of the sphere decoder for MIMO detection, ” IEEE T rans. Wir eless Commun. , vol. 7, no. 6, Jun. 2008. [11] B. Shim and I. Kang, “Sphere decoding with a probabilistic tree pruning, ” IEEE Tr ans. Signal Pr ocess. , vol. 56, no. 10, pp. 4867–4878, Oct. 2008. [12] R. Gow aikar and B. Hassibi, “Statistical pruning for near-maximum likelihood decoding, ” IEEE T rans. Signal Pr ocess. , vol. 55, no. 6, pp. 2661–2675, May 2007. [13] B. Shim and I. Kang, “Radius-adaptive sphere decoding via probabilistic tree pruning, ” in pr oc. SP A WC , Helsinki, Finland, Jun. 2007, pp. 1–5. [14] X.-W . Chang, J. W en, and X. Xie, “Effects of the LLL reduction on the success probability of the babai point and on the complexity of sphere decoding, ” IEEE T rans. Inf. Theory , vol. 59, no. 8, pp. 4915–4926, Jun. 2013. [15] W . Zhao and G. B. Giannakis, “Sphere decoding algorithms with improved radius search, ” IEEE T rans. Commun. , vol. 53, no. 7, pp. 1104–1109, Jul. 2005. [16] H. V ikalo, B. Hassibi, and T . Kailath, “Iterative decoding for MIMO channels via modified sphere decoding, ” IEEE T rans. W ireless Commun. , vol. 3, no. 6, pp. 2299–2311, Nov . 2004. [17] Z. Y ang, C. Liu, and J. He, “ A new approach for fast generalized sphere decoding in MIMO systems, ” IEEE Signal Pr ocess. Lett. , vol. 12, no. 1, pp. 41–44, Jan. 2005. [18] Q. W ang and Y . Jing, “Performance analysis and scaling law of MRC/MR T relaying with CSI error in multi-pair massiv e MIMO sys- tems, ” IEEE Tr ans. W ir eless Commun. , vol. 16, no. 9, pp. 5882–5896, Sep. 2017. [19] K. Mahdaviani, M. Ardakani, and C. T ellambura, “On raptor code design for inactiv ation decoding, ” IEEE T rans. Commun. , vol. 60, no. 9, pp. 2377–2381, Sep. 2012. [20] S. Sun and Y . Jing, “Training and decodings for cooperative network with multiple relays and receive antennas, ” IEEE T rans. Commun. , vol. 60, no. 6, pp. 1534–1544, Jun. 2012. [21] H. Y e, G. Y . Li, and B.-H. Juang, “Power of deep learning for channel estimation and signal detection in OFDM systems, ” IEEE Wir eless Communications Letters , v ol. 7, no. 1, pp. 114–117, Feb . 2018. [22] E. Nachmani, E. Marciano, L. Lugosch, W . J. Gross, D. Burshtein, and Y . Be’ery , “Deep learning methods for improved decoding of linear codes, ” IEEE J. Sel. Ar eas Commun. , vol. 12, no. 1, pp. 119–131, Feb . 2018. [23] N. Farsad and A. Goldsmith, “Detection algorithms for communication systems using deep learning, ” arXiv pr eprint arXiv:1705.08044 , 2017. [24] M. Kim, N.-I. Kim, W . Lee, and D.-H. Cho, “Deep learning aided SCMA, ” IEEE Commun. Lett. , vol. 22, no. 7, pp. 720–723, Apr . 2018. [25] T . W ang, C.-K. W en, H. W ang, F . Gao, T . Jiang, and S. Jin, “Deep learning for wireless physical layer: Opportunities and challenges, ” China Communications , vol. 14, no. 11, pp. 92–111, Oct. 2017. [26] N. Samuel, T . Diskin, and A. Wiesel, “Deep MIMO detection, ” in pr oc. SP A WC , July . 2017, pp. 1–5. [27] ——, “Learning to detect, ” IEEE T rans. Signal Process. , vol. 67, no. 10, pp. 2554–2564, May . 2019. [28] T . J. O’Shea, T . Erpek, and T . C. Clancy , “Deep learning based MIMO communications, ” arXiv preprint , 2017. [29] H. He, C.-K. W en, S. Jin, and G. Y . Li, “ A model-dri ven deep learning network for MIMO detection, ” arXiv pr eprint arXiv:1809.09336 , 2018. [30] T . O’Shea and J. Hoydis, “ An introduction to deep learning for the physical layer, ” IEEE T rans. on Cogn. Commun. Netw . , vol. 3, no. 4, pp. 563–575, Dec. 2017. [31] S. D ¨ orner , S. Cammerer , J. Hoydis, and S. ten Brink, “Deep learning based communication ov er the air , ” IEEE J. Sel. T opics Signal Process. , vol. 12, no. 1, pp. 132–143, Feb. 2018. [32] A. Felix, S. Cammerer, S. D ¨ orner , J. Hoydis, and S. T en Brink, “OFDM- Autoencoder for end-to-end learning of communications systems, ” in pr oc. SP A WC , July 2018, pp. 1–5. [33] F . A. Aoudia and J. Hoydis, “End-to-End learning of communications systems without a channel model, ” in proc. ACSSC , Oct. 2018, pp. 1–5. [34] S. Haykin, Neural Networks: a Comprehensive F oundation . Prentice Hall PTR, 1994. [35] I. Goodfellow , Y . Bengio, A. Courville, and Y . Bengio, Deep learning . MIT press Cambridge, 2016, vol. 1. [36] G. Gybenko, “ Approximation by superposition of sigmoidal functions, ” Mathematics of Contr ol, Signals and Systems , v ol. 2, no. 4, pp. 303–314, 1989. [37] D. P . Kingma and J. Ba, “ Adam: A method for stochastic optimization, ” arXiv pr eprint arXiv:1412.6980 , 2014. [38] G. B. Giannakis, Z. Liu, X. Ma, and S. Zhou, Space-time coding for br oadband wir eless communications . John Wile y & Sons, 2007. [39] “ A visual proof that neural nets can compute any function, ” http:// neuralnetworksanddeeplearning.com/chap4.html , accessed: 2010-09-30. [40] H. V ikalo and B. Hassibi, “On the sphere-decoding algorithm II. gener- alizations, second-order statistics, and applications to communications, ” IEEE T rans. Signal Pr ocess. , vol. 53, no. 8, pp. 2819–2834, Aug. 2005. [41] G. H. Golub and C. F . V an Loan, Matrix computations . JHU Press, 2012, vol. 3.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment