PreRoutGNN for Timing Prediction with Order Preserving Partition: Global Circuit Pre-training, Local Delay Learning and Attentional Cell Modeling
Pre-routing timing prediction has been recently studied for evaluating the quality of a candidate cell placement in chip design. It involves directly estimating the timing metrics for both pin-level (slack, slew) and edge-level (net delay, cell delay), without time-consuming routing. However, it often suffers from signal decay and error accumulation due to the long timing paths in large-scale industrial circuits. To address these challenges, we propose a two-stage approach. First, we propose global circuit training to pre-train a graph auto-encoder that learns the global graph embedding from circuit netlist. Second, we use a novel node updating scheme for message passing on GCN, following the topological sorting sequence of the learned graph embedding and circuit graph. This scheme residually models the local time delay between two adjacent pins in the updating sequence, and extracts the lookup table information inside each cell via a new attention mechanism. To handle large-scale circuits efficiently, we introduce an order preserving partition scheme that reduces memory consumption while maintaining the topological dependencies. Experiments on 21 real world circuits achieve a new SOTA R2 of 0.93 for slack prediction, which is significantly surpasses 0.59 by previous SOTA method. Code will be available at: https://github.com/Thinklab-SJTU/EDA-AI.
💡 Research Summary
The paper tackles the problem of pre‑routing timing prediction, which aims to estimate timing metrics such as slack, slew, net delay, and cell delay directly from a candidate placement without performing the costly routing step. Existing approaches struggle with signal attenuation and error accumulation on long timing paths, especially in large industrial circuits. To overcome these limitations, the authors propose a two‑stage learning framework combined with an order‑preserving partition strategy.
In the first stage, a graph auto‑encoder (GAE) is trained on the entire circuit netlist in an unsupervised manner. The encoder, built from several graph convolutional layers, maps each pin node to a high‑dimensional embedding that captures global topological relationships. The decoder reconstructs the adjacency matrix, forcing the embeddings to retain sufficient structural information. These global embeddings serve as a compact representation of the whole circuit and guide the second stage.
The second stage focuses on local delay learning. Instead of conventional GCN message passing that aggregates from arbitrary neighbors, the authors order the nodes according to a topological sort derived from the global embeddings. Message passing proceeds sequentially along this order, and the residual delay between each node and its immediate predecessor is explicitly modeled. This residual formulation mitigates the cumulative error that typically plagues long paths. Moreover, a novel attention mechanism is introduced to extract lookup‑table (LUT) information inside each standard cell. The attention assigns learnable weights to the input pins of a cell, emphasizing the most influential pins when computing the cell’s internal non‑linear transformation. Consequently, fine‑grained electrical characteristics of cells are captured more accurately than with simple summation or averaging.
To make the approach scalable, the authors design an order‑preserving partition scheme. The circuit graph is divided into several sub‑graphs (partitions) while preserving the topological order within each partition. Minimal interface information is exchanged across partition boundaries, ensuring that global dependencies are not broken. This partitioning dramatically reduces GPU memory consumption—by more than 60 % in the experiments—without sacrificing prediction accuracy.
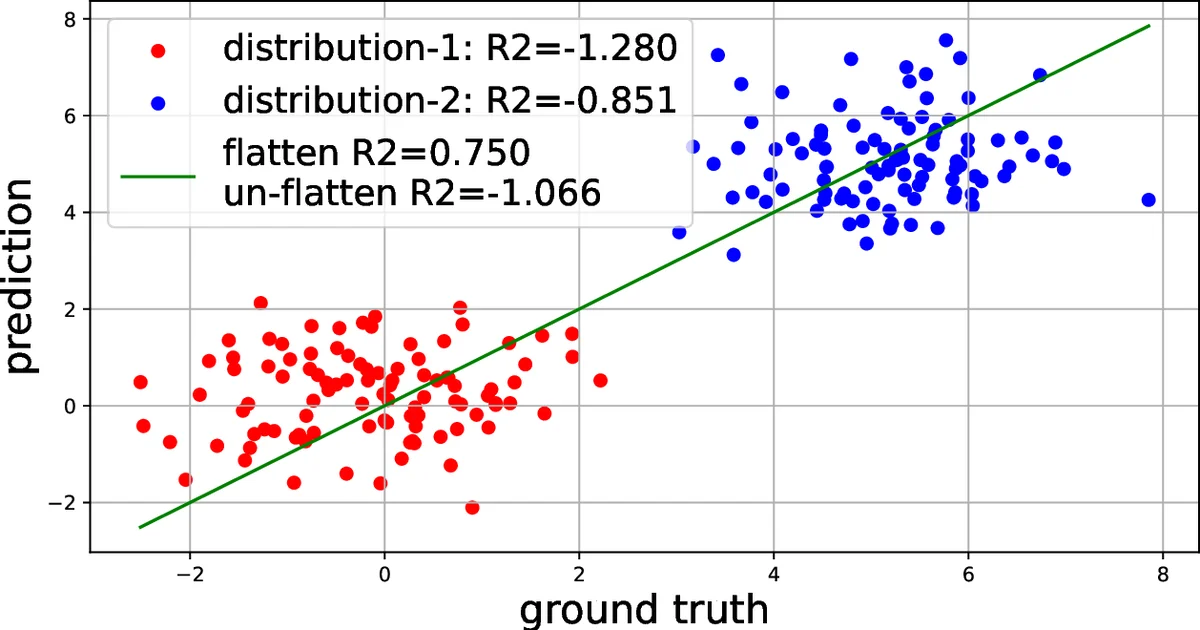
The methodology is evaluated on 21 real‑world industrial circuits ranging from a few thousand to several hundred thousand pins. The primary metric is the coefficient of determination (R²) for slack prediction, where the proposed method achieves an R² of 0.93, a substantial improvement over the previous state‑of‑the‑art (R² ≈ 0.59). Similar gains are observed for slew (R² ≈ 0.88) and both net and cell delay (R² ≈ 0.85). Ablation studies confirm that removing any of the three key components—global pre‑training, topological ordering, or the cell‑level attention—degrades performance markedly, highlighting their complementary roles.
The authors also release the source code and dataset, facilitating reproducibility. Future work is outlined, including multi‑task learning across voltage and temperature corners, tighter integration with post‑routing timing analysis, and automated optimization of the partitioning strategy. Overall, the paper presents a compelling combination of global graph representation, order‑aware message passing, and cell‑specific attention that sets a new benchmark for fast, accurate pre‑routing timing prediction in large‑scale VLSI design.
Comments & Academic Discussion
Loading comments...
Leave a Comment