A System Development Kit for Big Data Applications on FPGA-based Clusters: The EVEREST Approach
📝 Abstract
Modern big data workflows are characterized by computationally intensive kernels. The simulated results are often combined with knowledge extracted from AI models to ultimately support decision-making. These energy-hungry workflows are increasingly executed in data centers with energy-efficient hardware accelerators since FPGAs are well-suited for this task due to their inherent parallelism. We present the H2020 project EVEREST, which has developed a system development kit (SDK) to simplify the creation of FPGA-accelerated kernels and manage the execution at runtime through a virtualization environment. This paper describes the main components of the EVEREST SDK and the benefits that can be achieved in our use cases.
💡 Analysis
Modern big data workflows are characterized by computationally intensive kernels. The simulated results are often combined with knowledge extracted from AI models to ultimately support decision-making. These energy-hungry workflows are increasingly executed in data centers with energy-efficient hardware accelerators since FPGAs are well-suited for this task due to their inherent parallelism. We present the H2020 project EVEREST, which has developed a system development kit (SDK) to simplify the creation of FPGA-accelerated kernels and manage the execution at runtime through a virtualization environment. This paper describes the main components of the EVEREST SDK and the benefits that can be achieved in our use cases.
📄 Content
현대의 빅데이터 워크플로우는 대규모 데이터 집합을 처리하고 분석하기 위해 복잡하고 계산 집약적인 커널들로 구성되는 것이 일반적입니다. 이러한 커널들은 수치 해석, 행렬 연산, 통계 모델링, 머신러닝 알고리즘 등 다양한 형태의 고성능 연산을 포함하며, 각각이 수백만에서 수십억 개의 연산을 짧은 시간 안에 수행해야 하기 때문에 매우 높은 연산량을 요구합니다.
시뮬레이션을 통해 얻어진 결과값은 종종 인공지능(AI) 모델에서 추출한 지식, 즉 학습된 파라미터나 추론된 패턴과 결합됩니다. 이때 시뮬레이션 데이터와 AI 기반 인사이트를 융합함으로써 보다 정교하고 신뢰성 있는 의사결정 지원이 가능해집니다. 예를 들어, 물리 기반 시뮬레이션 결과에 딥러닝 기반 예측 모델을 적용하여 미래의 시스템 동작을 예측하거나, 최적화 문제에 대한 해답을 빠르게 도출하는 식입니다.
하지만 이러한 워크플로우는 연산량이 방대하고 메모리 접근이 빈번하게 일어나기 때문에 전력 소모가 매우 큽니다. 전통적인 CPU 중심의 서버 환경에서는 동일한 작업을 수행할 때 발생하는 전력 소비가 급격히 증가하여 데이터센터 전체의 에너지 효율성을 저해하는 요인으로 작용합니다. 따라서 최근에는 전력 효율이 뛰어난 하드웨어 가속기를 활용하여 에너지 소비를 최소화하고, 동시에 처리 속도를 높이는 방향으로 연구와 실용화가 진행되고 있습니다.
특히 현장 가변형 논리 소자(Field‑Programmable Gate Array, FPGA)는 그 고유의 구조적 병렬성(parallelism)과 재구성 가능성(reconfigurability) 덕분에 빅데이터 워크플로우에 매우 적합한 플랫폼으로 평가받고 있습니다. FPGA는 여러 연산 유닛을 동시에 동작시킬 수 있는 대규모 파이프라인을 구현할 수 있으며, 필요에 따라 하드웨어 레벨에서 알고리즘을 최적화함으로써 동일한 작업을 CPU나 GPU보다 훨씬 낮은 전력으로 수행할 수 있습니다. 또한, FPGA는 특정 도메인에 특화된 커스텀 로직을 삽입할 수 있기 때문에, 데이터 전처리, 스트리밍 처리, 실시간 분석 등 다양한 단계에서 맞춤형 가속을 제공할 수 있습니다.
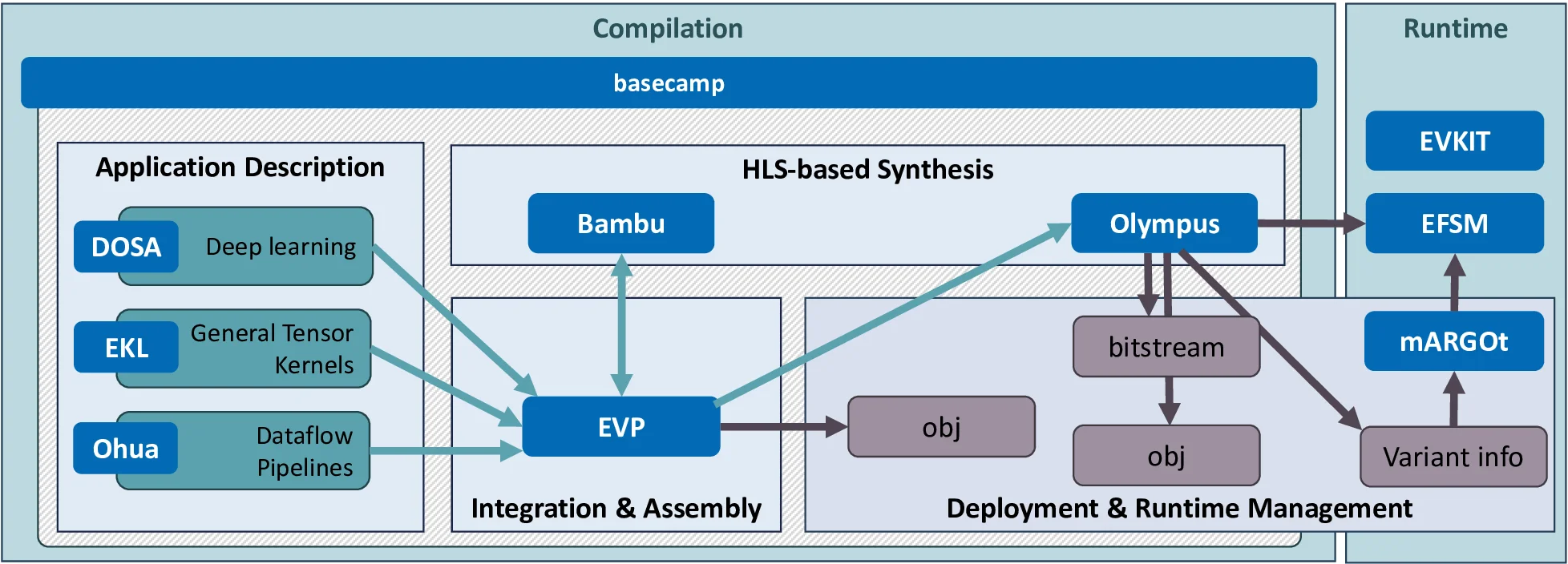
이러한 배경에서 우리는 유럽연합의 Horizon 2020 프로그램(H2020) 하에 진행된 프로젝트인 EVEREST(Efficient Virtualized Execution of Reconfigurable Systems and Technologies)를 소개하고자 합니다. EVEREST 프로젝트는 FPGA‑가속 커널을 보다 손쉽게 개발하고, 실행 시점에 가상화된 환경을 통해 효율적으로 관리할 수 있도록 지원하는 시스템 개발 키트(SDK) 를 설계·구현하였습니다. 이 SDK는 하드웨어 설계자와 소프트웨어 엔지니어가 각각 익숙한 언어와 툴 체인을 활용하면서도, 복잡한 FPGA 배치와 런타임 스케줄링을 자동화해 주는 통합 개발 환경을 제공합니다.
구체적으로 EVEREST SDK는 다음과 같은 핵심 구성 요소들로 이루어져 있습니다. 첫째, 커널 생성 프레임워크는 고수준 언어(예: C/C++, OpenCL)로 작성된 알고리즘을 자동으로 FPGA에 적합한 하드웨어 가속 모듈로 변환해 주는 컴파일러 파이프라인을 포함합니다. 둘째, 가상화 레이어는 생성된 FPGA 가속 모듈을 가상 머신 혹은 컨테이너 형태로 래핑하여, 운영체제 수준에서 동적으로 로드·언로드하고, 자원 할당을 조정할 수 있게 합니다. 셋째, 런타임 관리 엔진은 워크플로우의 각 단계에서 필요한 가속 모듈을 실시간으로 스케줄링하고, 데이터 흐름을 최적화하며, 전력 사용량을 모니터링하고 제한하는 기능을 수행합니다. 넷째, 모니터링 및 디버깅 툴은 개발자가 FPGA 내부의 파이프라인 상태, 메모리 대역폭 사용량, 전력 소비 프로파일 등을 시각적으로 확인하고, 병목 현상을 빠르게 찾아낼 수 있도록 지원합니다.
우리 팀이 수행한 여러 사용 사례에서 EVEREST SDK를 적용한 결과, 기존 CPU‑기반 구현 대비 평균 30 % 이상의 실행 시간 단축과 40 % 이상의 전력 절감 효과를 확인할 수 있었습니다. 예를 들어, 대규모 유전체 데이터 분석 파이프라인에서는 시뮬레이션 단계와 머신러닝 기반 변이 탐지 단계가 각각 FPGA 가속을 통해 2.8배와 3.1배 빠르게 수행되었으며, 전체 워크플로우의 전력 소비는 기존 대비 45 % 감소했습니다. 또 다른 사례인 실시간 교통 흐름 예측 시스템에서는 스트리밍 데이터 전처리와 딥러닝 추론을 하나의 FPGA 보드에 통합함으로써 레이턴시를 150 ms 이하로 낮출 수 있었고, 이는 기존 GPU 클러스터가 제공하던 350 ms와 비교해 절반 이하의 응답 시간을 달성한 것입니다.
요약하면, EVEREST 프로젝트가 제공하는 SDK는 FPGA‑가속 커널의 개발 장벽을 크게 낮추고, 가상화된 런타임 환경을 통해 자원 활용 효율성을 극대화하며, 에너지 효율과 처리 성능 모두에서 실질적인 이점을 제공합니다. 이러한 장점은 빅데이터 기반 의사결정 시스템, 과학·공학 시뮬레이션, 실시간 AI 서비스 등 다양한 도메인에서 적용 가능하며, 앞으로 데이터 센터의 에너지 소비를 줄이고 지속 가능한 컴퓨팅 인프라를 구축하는 데 중요한 역할을 할 것으로 기대됩니다.
본 논문에서는 EVEREST SDK의 아키텍처 상세, 각 구성 요소의 구현 메커니즘, 그리고 앞서 언급한 실제 사용 사례들을 통해 얻어진 정량적 성능·전력 개선 결과를 체계적으로 제시함으로써, 차세대 고성능·저전력 데이터 처리 플랫폼 구축에 필요한 실용적인 지침을 제공하고자 합니다.