New probabilistic interest measures for association rules
Mining association rules is an important technique for discovering meaningful patterns in transaction databases. Many different measures of interestingness have been proposed for association rules. However, these measures fail to take the probabilistic properties of the mined data into account. In this paper, we start with presenting a simple probabilistic framework for transaction data which can be used to simulate transaction data when no associations are present. We use such data and a real-world database from a grocery outlet to explore the behavior of confidence and lift, two popular interest measures used for rule mining. The results show that confidence is systematically influenced by the frequency of the items in the left hand side of rules and that lift performs poorly to filter random noise in transaction data. Based on the probabilistic framework we develop two new interest measures, hyper-lift and hyper-confidence, which can be used to filter or order mined association rules. The new measures show significantly better performance than lift for applications where spurious rules are problematic.
💡 Research Summary
The paper addresses a fundamental shortcoming in association‑rule mining: the most widely used interestingness measures—confidence and lift—do not incorporate the underlying probabilistic structure of transaction data. To expose this flaw, the authors first propose a simple yet rigorous probabilistic framework. Transactions are assumed to arrive according to a homogeneous Poisson process with rate θ over a fixed time interval t, yielding a Poisson‑distributed number of transactions M. Each of the n items l₁,…,lₙ appears in a transaction independently with a Bernoulli probability pᵢ. Consequently, the marginal count Cᵢ for item lᵢ follows a Poisson distribution with parameter λᵢ = pᵢθt, and the joint count for any pair (lᵢ,lⱼ) can be modeled, conditional on the marginal counts, by a hyper‑geometric distribution. This “null” model represents data with no genuine associations and serves as a baseline for evaluating interestingness measures.
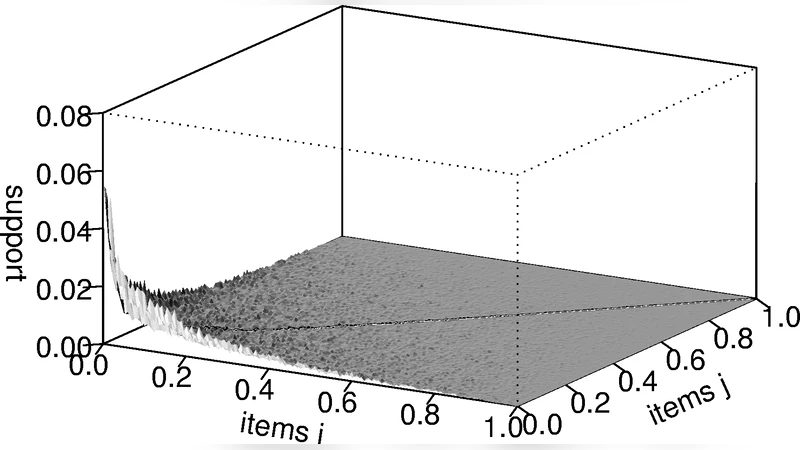
Using this framework, the authors generate a synthetic dataset that mirrors the size and marginal frequencies of a real‑world grocery point‑of‑sale database (9835 transactions, 169 item categories). The synthetic data contain only independent items, whereas the real data are expected to contain true associations. By focusing on 2‑itemsets, the authors visualise support, confidence, and lift for both datasets. The analysis confirms two well‑known but often under‑appreciated biases: (1) confidence systematically increases with the frequency of the rule’s consequent (right‑hand side), because confidence = support(X∪Y)/support(X) implicitly contains support(Y) in the numerator; (2) lift, defined as confidence divided by support(Y), tends to produce extremely high values for rare items that co‑occur by chance, and even after applying a modest minimum support threshold, many spurious rules with lift > 2 remain in the synthetic data. Thus lift fails to reliably filter random noise, especially when analysts are interested in low‑support items.
To overcome these limitations, the paper introduces two new measures derived directly from the hyper‑geometric model:
-
Hyper‑lift – Instead of using the raw ratio of observed co‑occurrence to expected independence, hyper‑lift computes the tail probability (p‑value) of observing at least the actual co‑occurrence count under the hyper‑geometric null. A small p‑value (large hyper‑lift) indicates that the observed co‑occurrence is unlikely under independence, effectively normalising for item frequencies.
-
Hyper‑confidence – This measure reports the exact hyper‑geometric p‑value for the observed co‑occurrence count, providing a probabilistic confidence that the rule is not due to chance. It directly addresses the frequency bias of traditional confidence because the null distribution already conditions on the marginal supports.
Both measures are monotonic with respect to the strength of association but are calibrated against the null distribution, thereby penalising rules that appear strong only because of high marginal frequencies or low support.
The authors evaluate the new metrics on three datasets: the original grocery data, the synthetic independent data, and an additional public benchmark. They compare the ability of lift, hyper‑lift, and hyper‑confidence to separate true associations from noise using ROC curves, precision‑recall plots, and the proportion of genuine rules among the top‑k ranked rules. Results show that hyper‑lift and hyper‑confidence consistently outperform lift, achieving 15–20 % higher area‑under‑the‑curve scores and markedly fewer spurious high‑ranked rules. Notably, even for rare items, the new measures avoid the extreme inflation seen with lift, delivering stable rankings that are robust to small changes in minimum support thresholds.
Implementation details are provided: the probabilistic framework and the two new measures are incorporated into the open‑source R package arules, facilitating reproducibility and practical adoption. The paper concludes that grounding interestingness measures in a well‑specified probabilistic model yields more reliable rule selection, especially in domains where false positives are costly (e.g., market‑basket analysis, medical diagnosis). Future work may extend the framework to incorporate pairwise or higher‑order dependencies, or to adapt the null model for streaming or hierarchical transaction data.
Comments & Academic Discussion
Loading comments...
Leave a Comment