ClimateSet: A Large-Scale Climate Model Dataset for Machine Learning
💡 Research Summary
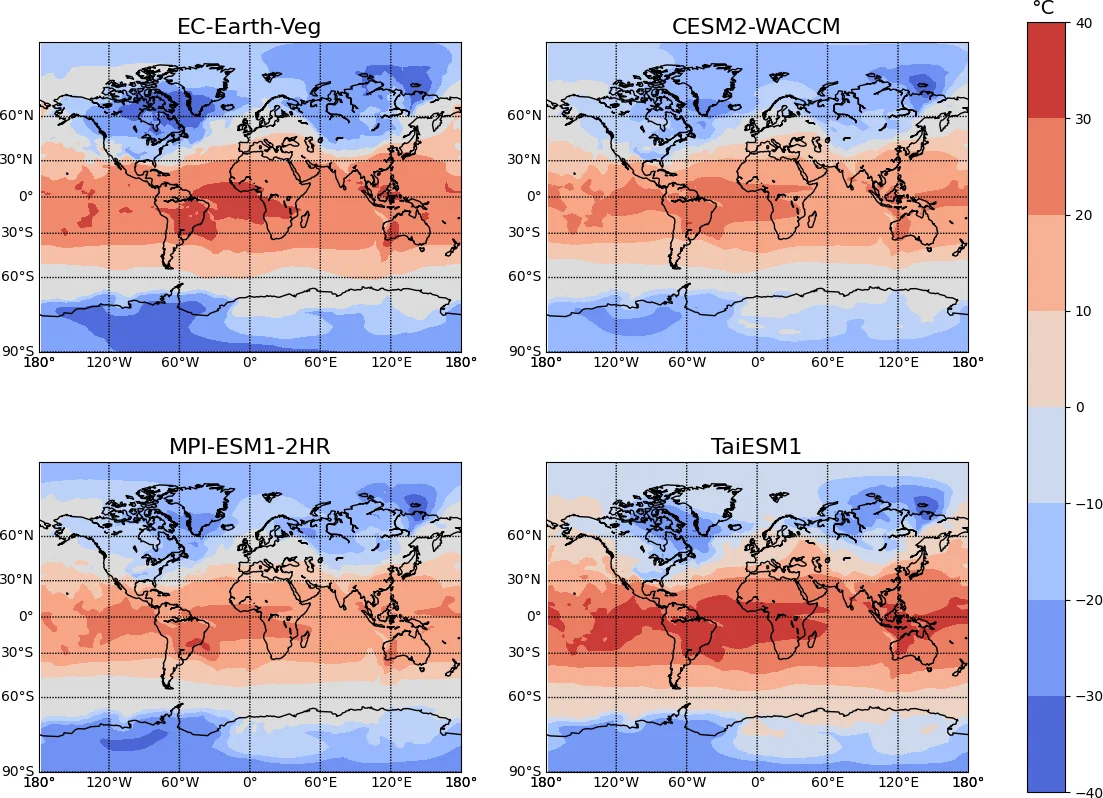
ClimateSet addresses a critical gap in climate‑machine‑learning research by providing a large‑scale, consistent, and ML‑ready dataset that combines inputs from Input4MIPs with outputs from CMIP6 for 36 Earth system models. The authors first motivate the need for such a resource: traditional climate simulations are computationally expensive, and most existing ML studies rely on a single climate model, limiting training data volume and the ability to capture inter‑model uncertainty. While datasets such as ClimateBench, WeatherBench, and EarthNet2021 have advanced ML for weather or single‑model climate emulation, none offer a multi‑model, scenario‑rich climate archive suitable for policy‑relevant projections.
The core contribution is a modular data pipeline that automatically downloads, harmonizes, and preprocesses CMIP6 ScenarioMIP outputs (temperature and precipitation at the surface) and Input4MIPs forcing fields (CO₂, CH₄, SO₂, black carbon). The pipeline aligns spatial resolution (≥250 km), temporal frequency (monthly), calendar conventions, and units across all models, producing a ready‑to‑use tensor format. The resulting core dataset includes five scenarios (historical plus SSP1‑2.6, SSP2‑4.5, SSP3‑7.0, SSP5‑8.5) for the period 2015‑2100, with up to the maximum number of ensemble members available per model.
To demonstrate utility, the authors benchmark several state‑of‑the‑art ML architectures (e.g., ConvLSTM, U‑Net, Transformer‑based models) on a climate‑emulation task. They compare two training regimes: (i) model‑specific emulators trained on a single climate model, and (ii) a “super‑emulator” trained jointly on all 36 models. Results show that the super‑emulator achieves lower root‑mean‑square error (10‑15 % improvement) and better generalization to unseen SSP scenarios, especially for precipitation where variability is high. Moreover, the multi‑model training captures inter‑model variability, enabling uncertainty quantification that is essential for policy makers.
The paper also outlines a broad set of downstream applications: downscaling to higher spatial resolution, extreme‑event prediction under different warming pathways, training large climate‑focused AI models, and rapid scenario testing for decision support. The authors emphasize the extensibility of ClimateSet: users can add more models, variables, vertical levels, finer spatial/temporal grids, or additional forcing agents as long as the data exist on the ESGF repository. The pipeline and code are publicly released on GitHub, and the core dataset is hosted via the Digital Research Alliance of Canada.
Limitations are candidly discussed. Currently only surface temperature and precipitation are provided, and forcing fields are limited to four agents. The 250 km resolution may be insufficient for regional impact studies, and the exclusion of the low‑forcing SSP1‑1.9 scenario reduces coverage of optimistic pathways. Not all models contain every scenario or ensemble member, leading to some data imbalance. The authors suggest future work to incorporate more variables (e.g., wind, humidity), higher resolutions, additional aerosol species, and integration with observational or satellite datasets.
In conclusion, ClimateSet delivers a much‑needed infrastructure that bridges climate science and machine learning, offering a scalable training corpus, a reproducible preprocessing workflow, and a benchmark for multi‑model emulation. By enabling “super‑emulators” that learn from many climate models simultaneously, it opens the door to faster, uncertainty‑aware climate projections that can directly inform policy and societal decision‑making.
Comments & Academic Discussion
Loading comments...
Leave a Comment