Where you go is who you are -- A study on machine learning based semantic privacy attacks
Concerns about data privacy are omnipresent, given the increasing usage of digital applications and their underlying business model that includes selling user data. Location data is particularly sensitive since they allow us to infer activity patterns and interests of users, e.g., by categorizing visited locations based on nearby points of interest (POI). On top of that, machine learning methods provide new powerful tools to interpret big data. In light of these considerations, we raise the following question: What is the actual risk that realistic, machine learning based privacy attacks can obtain meaningful semantic information from raw location data, subject to inaccuracies in the data? In response, we present a systematic analysis of two attack scenarios, namely location categorization and user profiling. Experiments on the Foursquare dataset and tracking data demonstrate the potential for abuse of high-quality spatial information, leading to a significant privacy loss even with location inaccuracy of up to 200m. With location obfuscation of more than 1 km, spatial information hardly adds any value, but a high privacy risk solely from temporal information remains. The availability of public context data such as POIs plays a key role in inference based on spatial information. Our findings point out the risks of ever-growing databases of tracking data and spatial context data, which policymakers should consider for privacy regulations, and which could guide individuals in their personal location protection measures.
💡 Research Summary
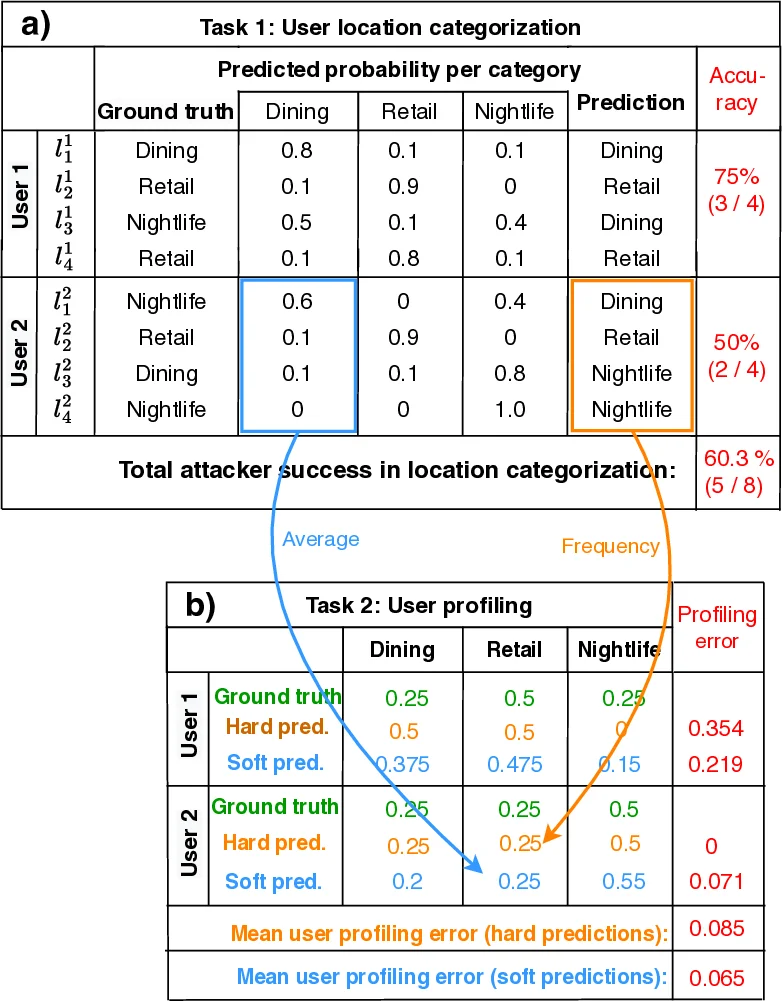
This paper investigates a novel class of privacy threats—semantic privacy attacks—where an adversary seeks to infer a user’s activities and behavioral profile solely from raw location traces (coordinates and timestamps). Unlike traditional location‑privacy work that focuses on re‑identification or trajectory linking, the authors define two concrete attack tasks: (1) location categorization, i.e., assigning each visited point to a semantic category such as “Dining”, “Shopping”, or “Nightlife”; and (2) user profiling, i.e., aggregating the inferred categories to produce a frequency distribution that characterises the user’s lifestyle.
To evaluate these attacks, the authors use the publicly available Foursquare check‑in dataset, which provides both precise geographic coordinates and ground‑truth venue categories. The dataset covers two dense urban areas (New York City and Tokyo) and contains 90,790 and 211,834 check‑ins respectively, spanning twelve venue categories defined by the Foursquare taxonomy. The same Foursquare POI database is treated as external contextual information that an attacker could exploit.
Four attack configurations are examined: (a) a naïve spatial nearest‑neighbor join that simply assigns the category of the closest POI; (b) an XGBoost model trained on temporal features only (visit start/end times, duration, hour‑of‑day, day‑of‑week distributions); (c) an XGBoost model trained on spatial features only (raw coordinates, distance to nearest POI, POI density within 100 m/500 m/1 km, etc.); and (d) a combined spatio‑temporal XGBoost model that uses both sets of features. An uninformed baseline draws predictions at random according to the training‑set class frequencies.
To simulate realistic GPS errors and deliberate privacy‑preserving perturbations, the authors add uniform random noise to each coordinate within a radius r = 0, 50, 100, 200, 500, or 1000 m. The r = 0 case is unrealistic but serves as an upper bound because the check‑in locations and POI data are perfectly aligned, yielding 100 % accuracy for the spatial join. The authors then perform 10‑fold cross‑validation, splitting either by user (to emulate attacks on unseen individuals) or by spatial region (to emulate transfer to new geographic areas).
Key findings:
- Rapid decay of spatial accuracy with noise: When r ≤ 200 m, the combined spatio‑temporal XGBoost model still achieves 70‑80 % correct classification, indicating that modest GPS errors do not substantially hinder semantic inference. At r = 500 m the accuracy drops below 50 %, and at r ≥ 1 km spatial‑only models approach random performance (≈12 % for twelve classes).
- Temporal information remains powerful: The temporal‑only XGBoost model is unaffected by spatial noise and consistently reaches 30 % (NYC) to 40 % (Tokyo) accuracy—far above the random baseline—demonstrating that “when” a user visits a place can be as revealing as “where”.
- User profiling inherits the location‑categorization performance: Profiling accuracy (measured as the similarity between inferred and true category frequency vectors) follows the same trend: high for low‑noise scenarios, moderate for r ≈ 200 m, and poor for strong obfuscation. High‑frequency categories such as Dining or Shopping retain relatively stable proportions even under larger noise, whereas less common categories become indistinguishable.
- Public POI data is a critical enabler: The spatial join baseline shows that if an attacker has access to a high‑quality, up‑to‑date POI database, simply matching coordinates can fully reveal semantics when the raw data are precise.
Implications:
- Simple coordinate obfuscation (e.g., adding a few hundred meters of noise) is insufficient to protect against semantic attacks that exploit both spatial context and temporal patterns.
- Time stamps themselves constitute a privacy liability; protecting them (through aggregation, random shifts, or removal) is necessary alongside spatial masking.
- Policymakers should consider “semantic privacy” as a distinct dimension when drafting regulations, extending principles of data minimisation and purpose limitation to cover derived activity information.
- End‑users can mitigate risk by deliberately degrading GPS precision (e.g., using location‑fuzzing apps) and by limiting the granularity of time data shared with services.
Limitations and future work: The study focuses on single‑user static datasets; multi‑user correlation attacks, adversarial learning, and deep‑learning sequence models (e.g., LSTMs, Transformers) could further improve inference. Real‑world deployment would also need to balance utility (e.g., navigation, location‑based services) against the privacy loss quantified here.
In summary, the paper provides a rigorous, machine‑learning‑centric quantification of how much semantic information can be extracted from noisy location traces, highlighting that both spatial context and temporal behaviour remain potent privacy threats even under modest protection measures.
Comments & Academic Discussion
Loading comments...
Leave a Comment