cuRobo: Parallelized Collision-Free Minimum-Jerk Robot Motion Generation
This paper explores the problem of collision-free motion generation for manipulators by formulating it as a global motion optimization problem. We develop a parallel optimization technique to solve this problem and demonstrate its effectiveness on massively parallel GPUs. We show that combining simple optimization techniques with many parallel seeds leads to solving difficult motion generation problems within 50ms on average, 60x faster than state-of-the-art (SOTA) trajectory optimization methods. We achieve SOTA performance by combining L-BFGS step direction estimation with a novel parallel noisy line search scheme and a particle-based optimization solver. To further aid trajectory optimization, we develop a parallel geometric planner that plans within 20ms and also introduce a collision-free IK solver that can solve over 7000 queries/s. We package our contributions into a state of the art GPU accelerated motion generation library, cuRobo and release it to enrich the robotics community. Additional details are available at https://curobo.org
💡 Research Summary
The paper “cuRobo: Parallelized Collision‑Free Minimum‑Jerk Robot Motion Generation” presents a comprehensive GPU‑accelerated framework for generating collision‑free, minimum‑jerk trajectories for high‑dimensional manipulators. The authors formulate motion generation as a global trajectory optimization problem that must satisfy joint limits, velocity/acceleration/jerk constraints, and collision avoidance with both the robot itself and the environment. To solve this problem efficiently, they exploit massive parallelism on modern GPUs, combining three key algorithmic components: (1) a batched L‑BFGS optimizer with a novel parallel noisy line‑search, (2) a particle‑based global optimizer that provides robust exploration of the non‑convex cost landscape, and (3) a parallel geometric planner that quickly produces feasible seed trajectories.
The core of the system is a set of high‑performance CUDA kernels for forward and inverse kinematics, self‑collision checking, and signed‑distance computation against arbitrary world representations (primitives, meshes, depth maps, occupancy grids). These kernels are up to 10 000× faster than traditional CPU implementations and are fully differentiable, allowing seamless integration with gradient‑based optimization in PyTorch. Continuous collision checking is achieved by sweeping signed‑distance fields, requiring only point‑distance and closest‑point queries, which makes the method agnostic to the underlying world model.
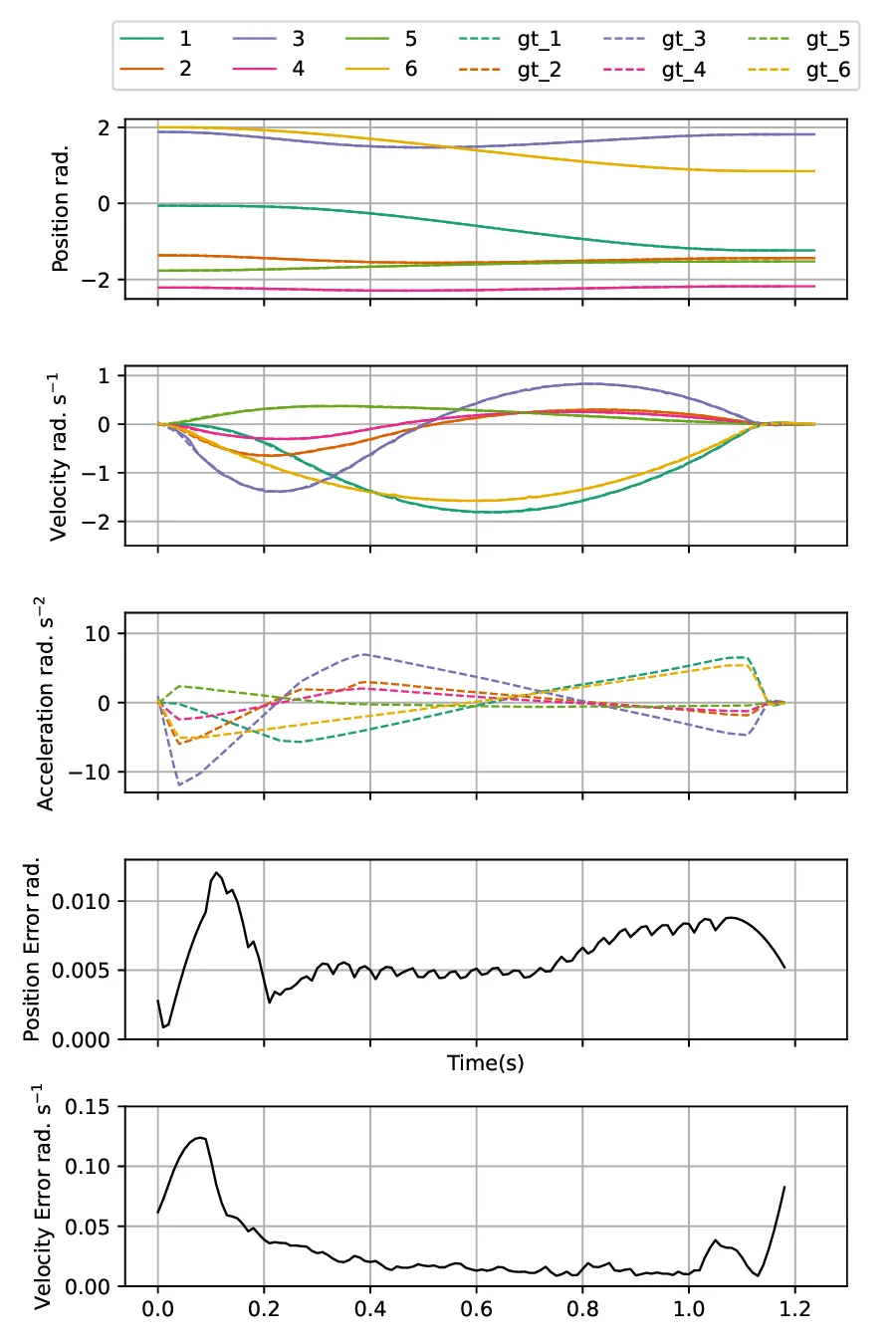
The motion generation pipeline proceeds as follows: (i) many instances of collision‑free inverse kinematics (IK) are solved in parallel, yielding thousands of candidate end‑effector poses per second (≈37 k Hz for plain IK, ≈7.6 k Hz for collision‑free IK). (ii) Seed trajectories are constructed by linear interpolation between the start configuration and each IK solution, optionally passing through a retract configuration or a path generated by the parallel geometric planner. (iii) All seeds are fed simultaneously into the batched L‑BFGS optimizer; the parallel noisy line‑search evaluates multiple step sizes across GPU threads, dramatically reducing line‑search overhead. (iv) The particle‑based optimizer runs concurrently, providing a global search layer that helps escape poor local minima. (v) The best trajectory is selected, optionally refined with a final time‑step optimization.
Experimental results on a variety of robots (Franka Panda, Kuka iiwa, etc.) and complex environments demonstrate average planning times of 30–50 ms, a 60× speed‑up over state‑of‑the‑art CPU‑based trajectory optimizers such as Tesseract. The geometric planner alone produces collision‑free paths within 20 ms on a desktop equipped with an RTX 4090. On an NVIDIA Jetson AGX Orin, the system remains real‑time, achieving 21–28× speed‑ups under 15 W and 60 W power budgets.
The authors acknowledge limitations: the particle‑based component can become memory‑intensive for very high‑DOF robots, and continuous collision checking may introduce approximation errors for highly detailed meshes. Future work includes memory‑efficient particle management and hybrid collision models that blend primitive‑based and mesh‑based distance fields.
Finally, the authors release the cuRobo library as open source, providing GPU‑accelerated implementations of kinematics, signed‑distance functions, L‑BFGS and particle optimizers, a geometric planner, trajectory optimization, and model‑predictive control. The library integrates with PyTorch, enabling researchers and practitioners to tackle large‑scale motion‑planning problems and deploy real‑time planners on both high‑end workstations and low‑power edge devices.
Comments & Academic Discussion
Loading comments...
Leave a Comment