📝 Original Info
- Title: 바닥도면을 지식그래프로 변환해 시각장애인 실내 길찾기 지원
- ArXiv ID: 2512.12177
- Date: 2023-10-05
- Authors: : Adin Ayazde and Team Otsu ###
📝 Abstract
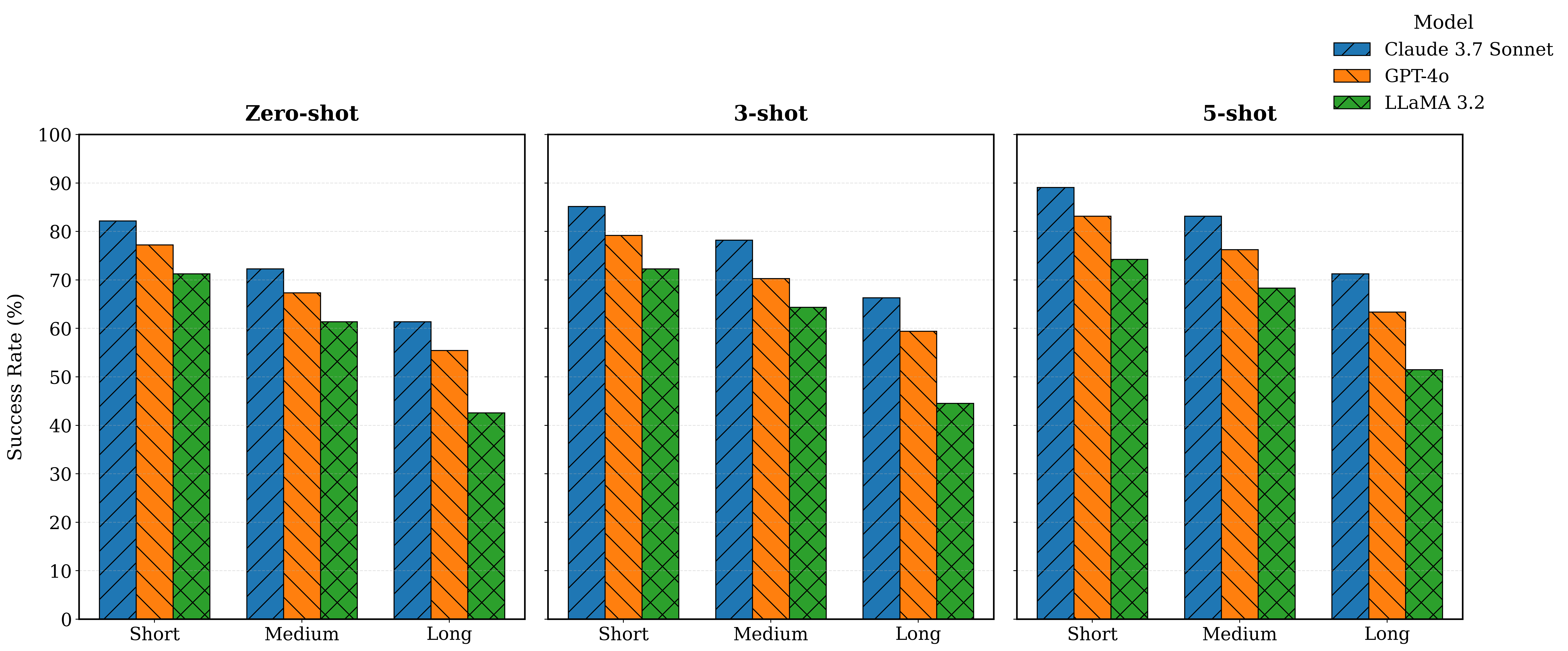
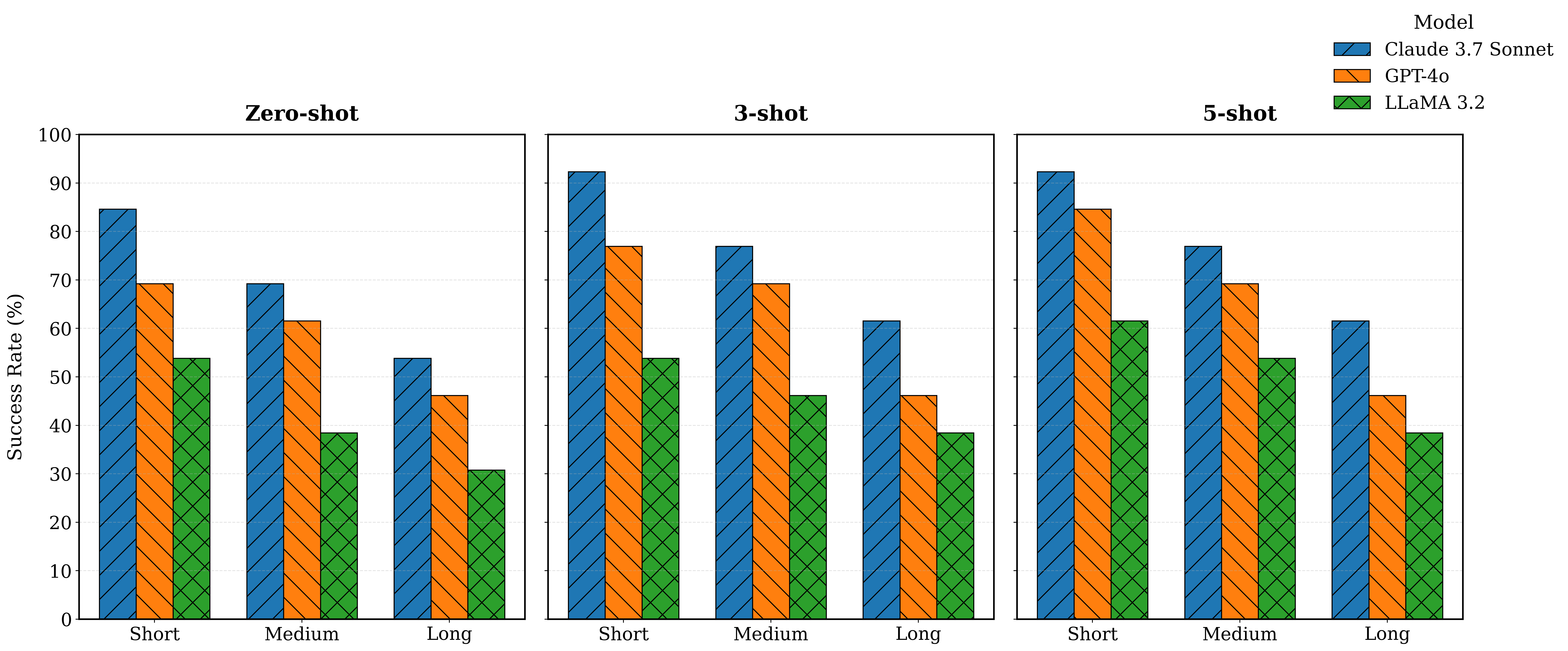
Indoor navigation remains a critical challenge for people with visual impairments. The current solutions mainly rely on infrastructure-based systems, which limit their ability to navigate safely in dynamic environments. We propose a novel navigation approach that utilizes a foundation model to transform floor plans into navigable knowledge graphs and generate humanreadable navigation instructions. Floorplan2Guide integrates a large language model (LLM) to extract spatial information from architectural layouts, reducing the manual preprocessing required by earlier floorplan parsing methods. Experimental results indicate that few-shot learning improves navigation accuracy in comparison to zero-shot learning on simulated and real-world evaluations. Claude 3.7 Sonnet achieves the highest accuracy among the evaluated models, with 92.31%, 76.92%, and 61.54% on the short, medium, and long routes, respectively, under 5-shot prompting of the MP-1 floor plan. The success rate of graph-based spatial structure is 15.4% higher than that of direct visual reasoning among all models, which confirms that graphical representation and in-context learning enhance navigation performance and make our solution more precise for indoor navigation of Blind and Low Vision (BLV) users.
💡 Deep Analysis
Deep Dive into 바닥도면을 지식그래프로 변환해 시각장애인 실내 길찾기 지원.
Indoor navigation remains a critical challenge for people with visual impairments. The current solutions mainly rely on infrastructure-based systems, which limit their ability to navigate safely in dynamic environments. We propose a novel navigation approach that utilizes a foundation model to transform floor plans into navigable knowledge graphs and generate humanreadable navigation instructions. Floorplan2Guide integrates a large language model (LLM) to extract spatial information from architectural layouts, reducing the manual preprocessing required by earlier floorplan parsing methods. Experimental results indicate that few-shot learning improves navigation accuracy in comparison to zero-shot learning on simulated and real-world evaluations. Claude 3.7 Sonnet achieves the highest accuracy among the evaluated models, with 92.31%, 76.92%, and 61.54% on the short, medium, and long routes, respectively, under 5-shot prompting of the MP-1 floor plan. The success rate of graph-based spat
📄 Full Content
Floorplan2Guide: LLM-Guided Floorplan Parsing
for BLV Indoor Navigation
Aydin Ayanzadeh and Tim Oates
University of Maryland, Baltimore County
Baltimore, Maryland, USA
{aydina1, oates}@umbc.edu
Abstract—Indoor navigation remains a critical challenge for
people with visual impairments. The current solutions mainly
rely on infrastructure-based systems, which limit their ability
to navigate safely in dynamic environments. We propose a novel
navigation approach that utilizes a foundation model to transform
floor plans into navigable knowledge graphs and generate human-
readable navigation instructions. Floorplan2Guide integrates a
large language model (LLM) to extract spatial information
from architectural layouts, reducing the manual preprocessing
required by earlier floorplan parsing methods. Experimental
results indicate that few-shot learning improves navigation ac-
curacy in comparison to zero-shot learning on simulated and
real-world evaluations. Claude 3.7 Sonnet achieves the highest
accuracy among the evaluated models, with 92.31%, 76.92%,
and 61.54% on the short, medium, and long routes, respectively,
under 5-shot prompting of the MP-1 floor plan. The success
rate of graph-based spatial structure is 15.4% higher than that
of direct visual reasoning among all models, which confirms
that graphical representation and in-context learning enhance
navigation performance and make our solution more precise for
indoor navigation of Blind and Low Vision (BLV) users.
Index Terms—Indoor Navigation, Large Language Models,
FloorPlan Analysis, Assistive Technology
I. INTRODUCTION
According to a recent report, approximately 2.2 billion
individuals worldwide live with visual impairment [1]. Indi-
viduals with visual impairments encounter significant barriers
to independent mobility, including challenges with travel,
orientation, and acquiring spatial information, necessitating
safe and reliable navigation support. In addition to traditional
mobility aids such as white canes and guide dogs, recent tech-
nological advancements utilizing artificial intelligence provide
individuals with visual impairments enhanced mobility and
independence [2], [3].
Recent progress in Multimodal Large Language Models
(MLLMs) has improved navigation reasoning performance by
integrating visual data with textual information, enabling high-
level path planning [4], [5]. This research builds upon outdoor
navigation systems, where MLLMs can interpret and describe
visual information to assist Blind and Low-Vision (BLV) users
in outdoor environments, demonstrating accurate performance
in open-world scenarios. Outdoor navigation systems function
reliably, as they rely on GPS to determine users’ positions.
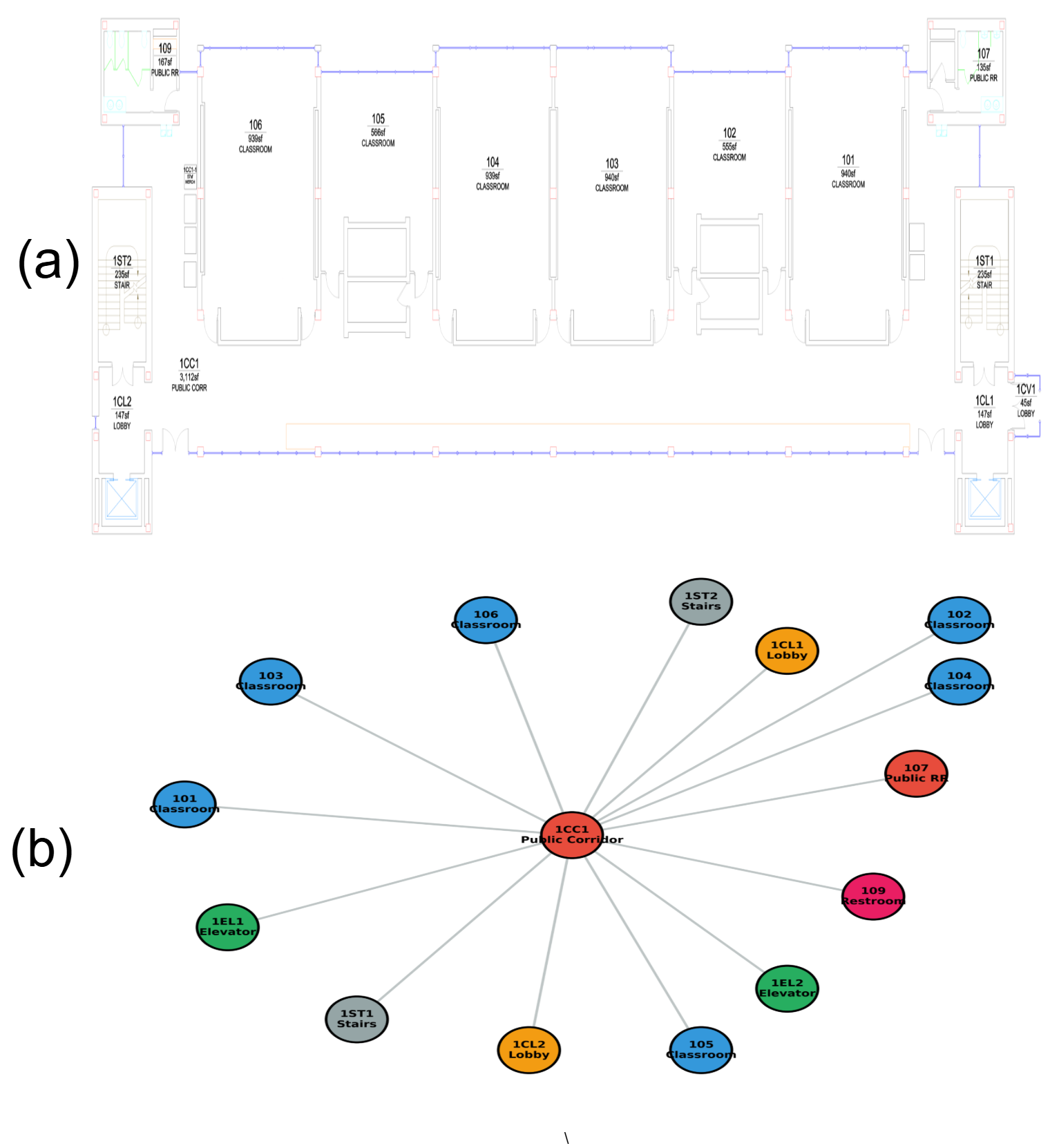
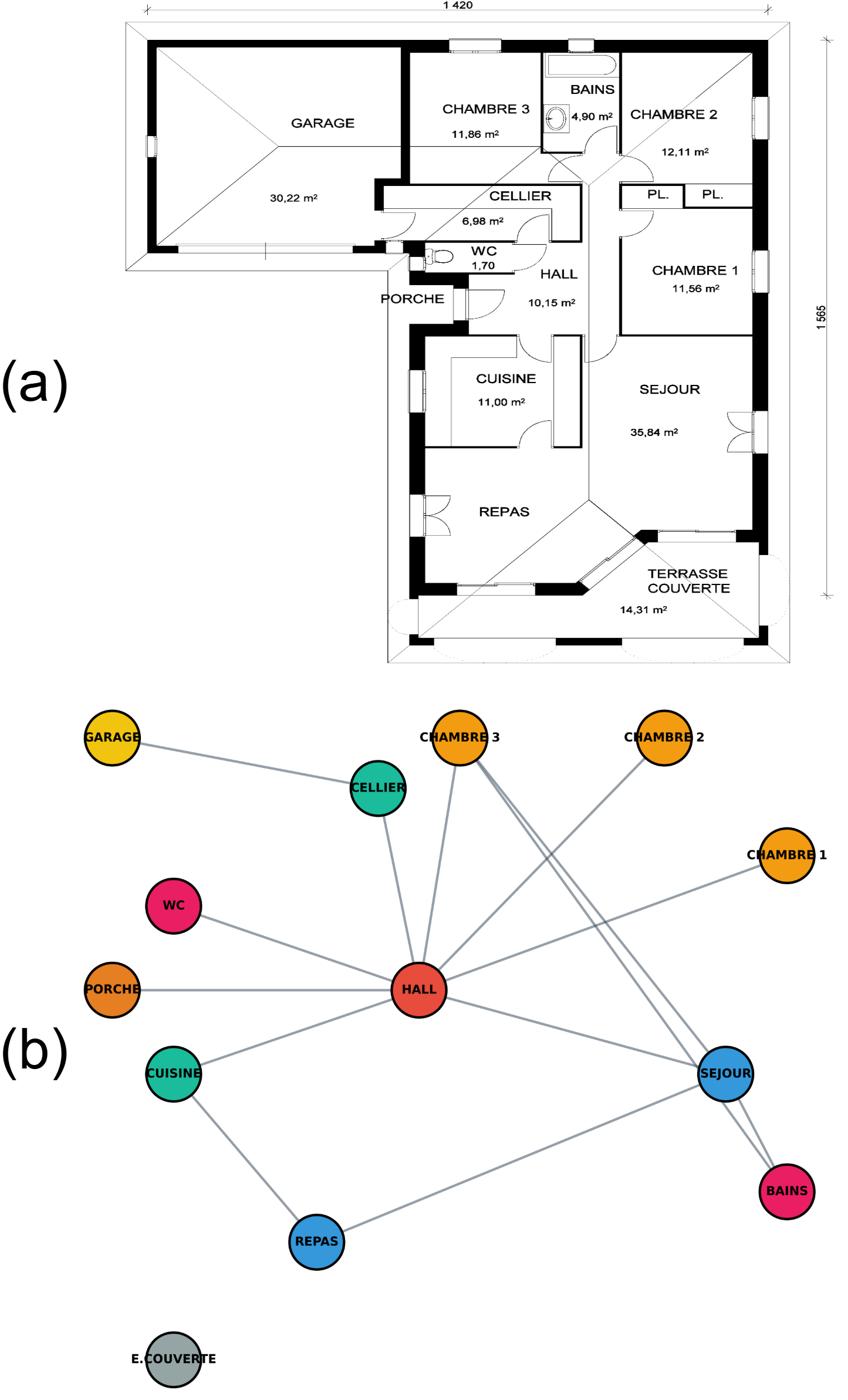
Floorplan analysis is a critical phase in computer vi-
sion for indoor navigation. Traditional methods utilize image
processing and graph-based algorithms to extract the main
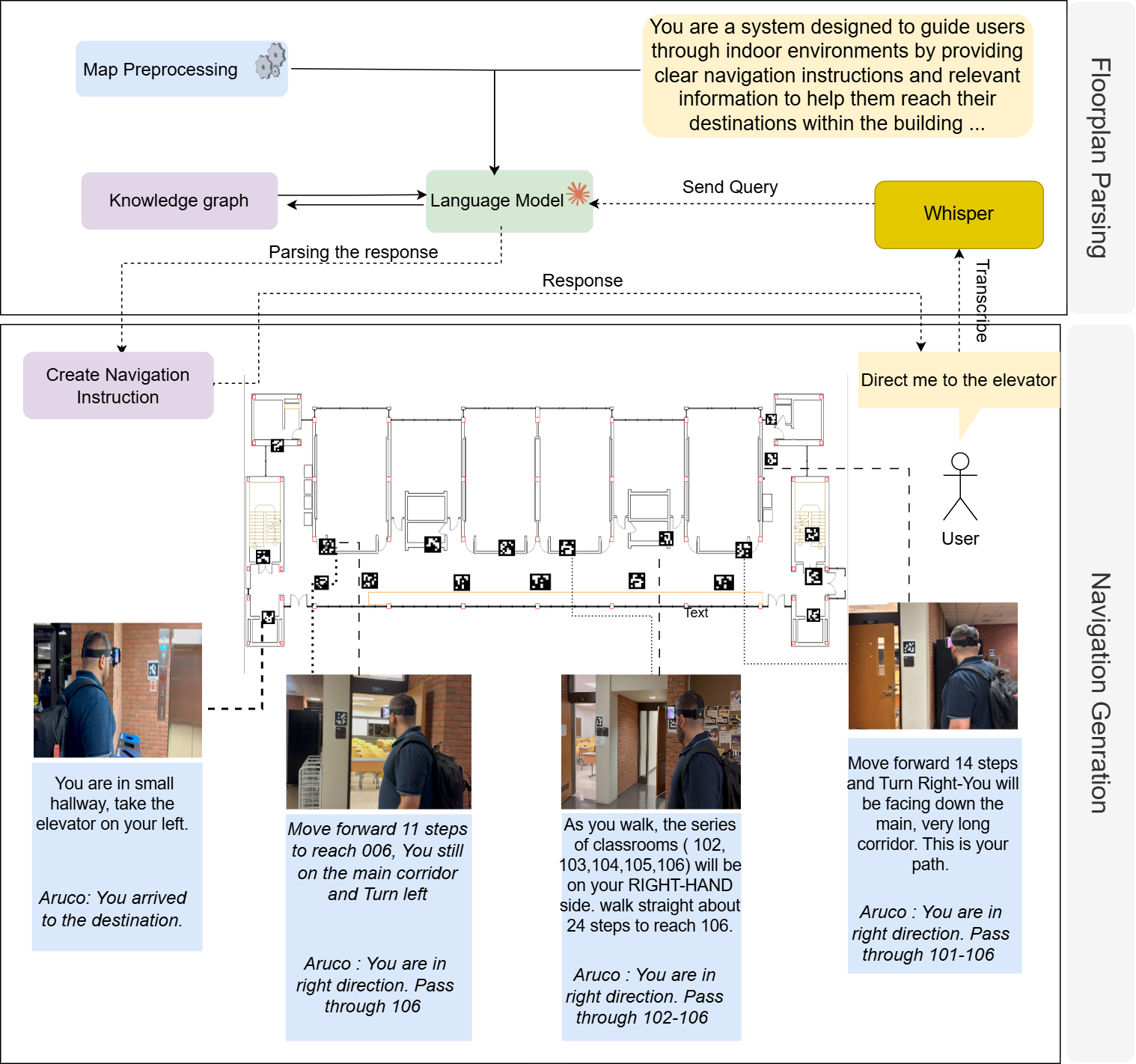
Fig. 1: Architecture of the LLM-based indoor navigation sys-
tem. The framework parses floorplans into a spatial knowledge
graph interpreted by the language model, which generates
navigation instructions from user queries (e.g., ”Direct me to
the elevator”).
components of floorplans, including walls and doors [6]–[9].
While graph embeddings excel on link prediction tasks [29],
[30], node classification, graph visualization, etc. Integrating
language models with knowledge graph systems can enhance
knowledge representation and improve the reasoning capa-
bilities of LLMs [11]. Traditional methods rely on geomet-
ric and structural heuristics, which often require extensive
preprocessing and manual correction. Recent advances have
enabled new deep learning methods and multimodal reasoning
for floorplan analysis, where LLMs can interpret floorplans
to identify entities and relationships [33], [39] directly. In-
door localization serves as the foundation for indoor navi-
gation systems. Infrastructure-based methods, such as BLE
beacons [13]–[17] and RFID tags [18], [22], offer precise
positioning but require costly installation and maintenance. In
arXiv:2512.12177v1 [cs.AI] 13 Dec 2025
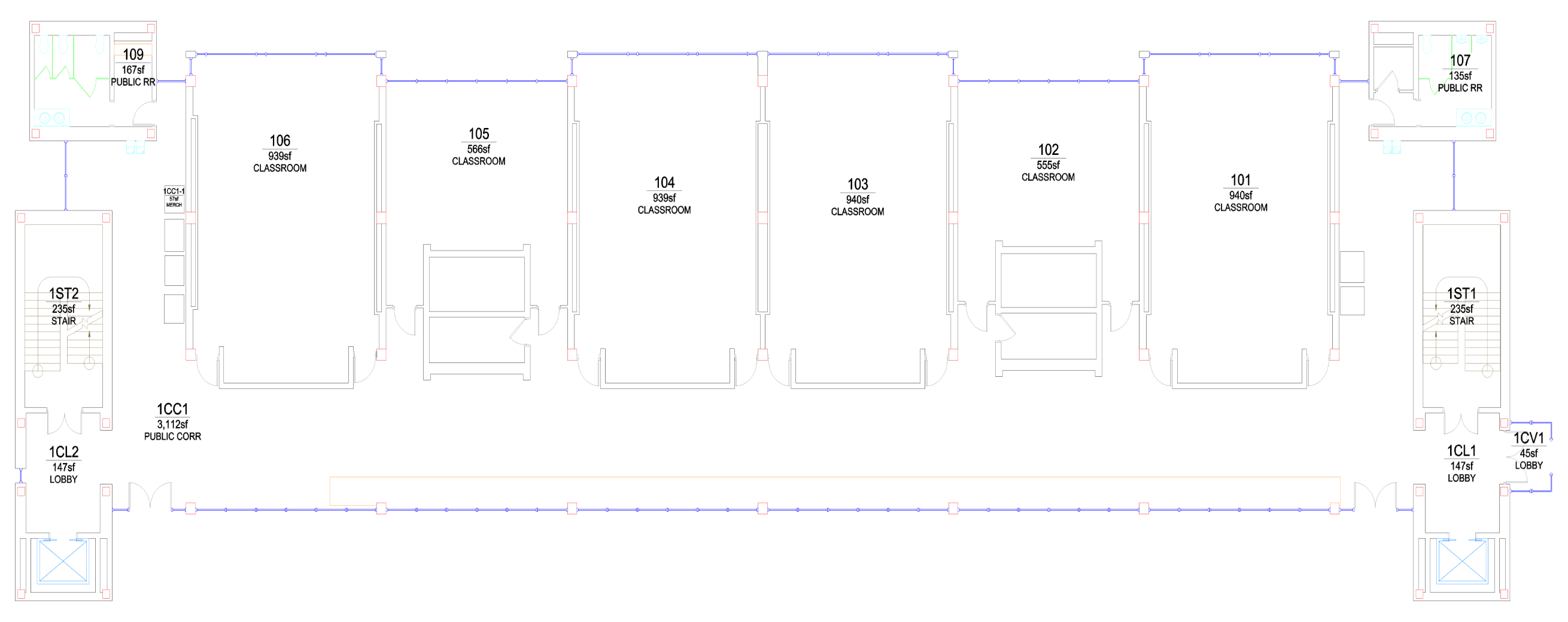
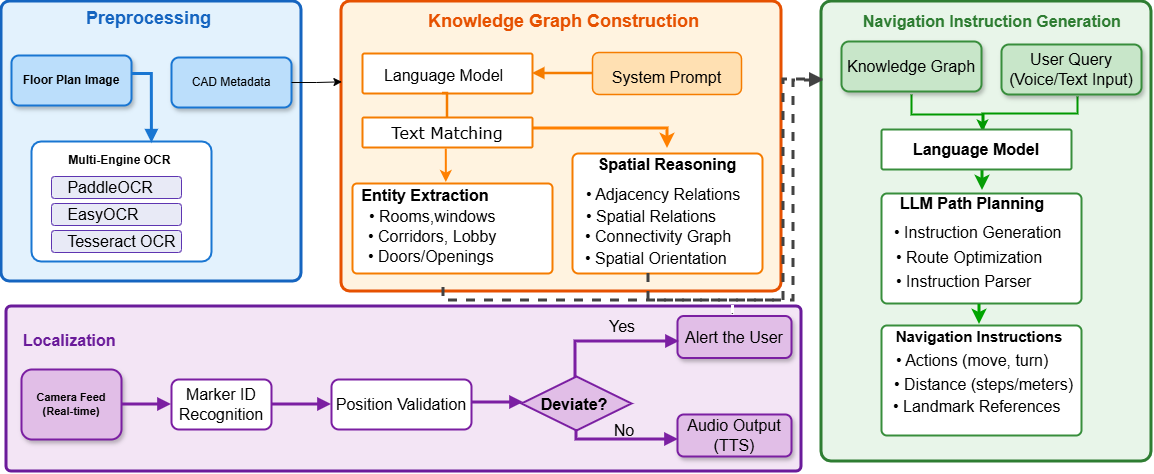
Fig. 2: Overall workflow of the proposed Floorplan2Guide framework. The system takes a floorplan image and a user query
(e.g., “I want to use the restroom”) as input. The preprocessing module extracts textual and geometric features using OCR and
visual analysis, while the LLM constructs and validates a knowledge graph enriched with ArUco marker information. Finally,
the navigation module generates step-by-step, context-aware instructions. During localization, the system alerts the user if they
deviate from the route; otherwise, it repeats the last navigation instruction.
contrast, lightweight localization approaches employ sensors
and cameras with minimal infrastructure requirements, such as
printed fiducial markers [36], [37], and rely on computer vision
and machine learning for localization [34], [35]. However,
these models depend on large, building-specific datasets and
lack generalization to ne
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.