An Evaluation and Comparison of GPU Hardware and Solver Libraries for Accelerating the OPM Flow Reservoir Simulator
💡 Research Summary
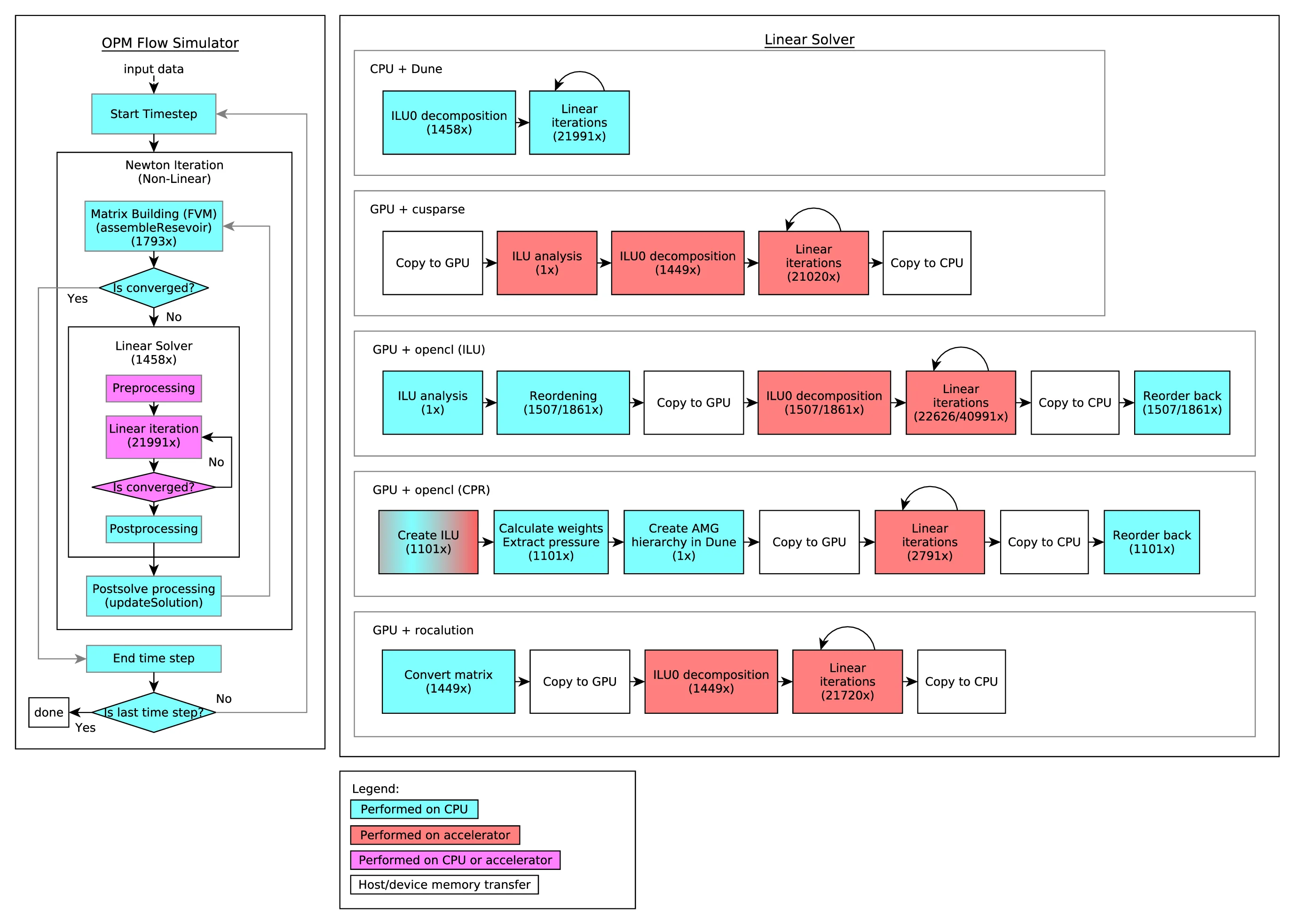
This paper investigates the acceleration of the Open Porous Media (OPM) Flow reservoir simulator by targeting its most time‑consuming component: the ILU0‑preconditioned BiCGStab linear solver. The authors develop both hand‑written OpenCL kernels and a set of GPU‑oriented third‑party libraries—including NVIDIA’s cuSparse, AMD’s rocSparse, and the multi‑platform amgcl—and integrate them into OPM Flow through a custom bridging layer. The study evaluates three realistic use cases ranging from the public NORNE benchmark (≈50 k active cells) to a large industrial model (≈1 million cells), running on both NVIDIA (RTX 3090) and AMD (Radeon Instinct MI100) hardware.
Key contributions are: (1) a fully open‑source OpenCL implementation of the ILU0‑preconditioned BiCGStab algorithm, carefully partitioned into work‑groups to exploit SIMD parallelism while minimizing global memory traffic; (2) a generic integration framework that converts OPM’s BCRSMatrix format to the CSR/COO formats required by cuSparse, rocSparse, and amgcl, allowing direct comparison of library overheads; (3) a comprehensive performance benchmark that measures wall‑clock time, speed‑up relative to the baseline DUNE‑ISTL CPU solver, and scalability against increasing numbers of dual‑threaded MPI processes.
Results show that for the smallest test case the GPU speed‑up is modest (≈2×) due to data‑transfer overheads. For the medium‑size model (≈200 k cells) the OpenCL kernel achieves a 3.8× speed‑up, cuSparse 4.2×, and rocSparse 4.5×. The large‑scale model (≈1 M cells) yields the highest acceleration: a single GPU delivers up to 5.6× faster execution than a single dual‑threaded MPI process, and its throughput is comparable to that of eight dual‑threaded MPI processes on the same CPU cluster. Notably, the AMD‑rocSparse combination slightly outperforms the NVIDIA‑cuSparse stack on the largest problem, indicating that library‑specific optimizations for sparse triangular solves and memory bandwidth are critical.
The paper also analyses the algorithmic challenges of porting ILU0 to GPUs. ILU0’s triangular factorization exhibits strong data dependencies, making naïve parallelization ineffective. The authors adopt a block‑wise approach: the matrix is divided into block rows, each processed sequentially within the block but independently across blocks, allowing concurrent execution of forward and backward substitution steps. This strategy reduces ILU0 preprocessing time by roughly 30‑40 % compared with a naïve GPU port.
Limitations are identified: GPU memory capacity becomes a bottleneck for the largest models on cards with ≤12 GB, leading to out‑of‑memory failures or severe performance degradation. Consequently, future work should explore memory‑compression schemes, multi‑GPU distribution, and out‑of‑core algorithms. Additionally, while ILU0 is the default preconditioner in OPM Flow, other sophisticated preconditioners such as algebraic multigrid (AMG) or CPR could further improve convergence; implementing these on GPUs remains an open research direction.
In conclusion, the study demonstrates that GPU acceleration of OPM Flow is feasible and competitive with traditional CPU‑based MPI scaling. By providing both a hand‑crafted OpenCL solution and an integration pathway for established GPU libraries, the authors enable researchers and industry practitioners to select the most appropriate approach for their hardware. The work represents the first complete GPU performance evaluation on an open‑source reservoir simulator using real‑world field cases, and it lays a solid foundation for subsequent advances in memory‑efficient sparse linear algebra and multi‑GPU reservoir simulation.
Comments & Academic Discussion
Loading comments...
Leave a Comment