FaceDiffuser: Speech-Driven 3D Facial Animation Synthesis Using Diffusion
💡 Research Summary
FaceDiffuser introduces a novel, non‑deterministic approach to speech‑driven 3D facial animation by leveraging denoising diffusion probabilistic models (DDPM) together with a large‑scale pre‑trained speech encoder, HuBERT. The authors argue that existing deep‑learning methods for 3D facial animation are predominantly deterministic: given the same audio input they always produce the same facial motion. This deterministic behavior fails to capture the inherent variability of non‑verbal facial cues such as micro‑expressions, eye blinks, and subtle muscle movements that naturally accompany speech. Moreover, most prior work focuses on vertex‑based mesh data and offers limited compatibility with traditional animation pipelines that rely on rigged characters and blendshape controls.
To address these gaps, FaceDiffuser proposes a unified framework that can be trained on both high‑dimensional vertex sequences and lower‑dimensional blendshape/control vectors. The system consists of three main components: (1) a frozen HuBERT‑base‑ls960 model that transforms raw audio waveforms into rich 768‑dimensional embeddings, (2) a diffusion process that progressively adds Gaussian noise to the ground‑truth animation sequence (either vertex positions or blendshape values) across T timesteps, and (3) a reverse‑diffusion decoder built from stacked GRU layers followed by a fully‑connected output head. During training, a random timestep t is sampled, the corresponding noisy sequence x_t is generated, and the decoder receives (a) the HuBERT audio embedding, (b) the noisy animation x_t, (c) a one‑hot style vector S indicating the speaker identity (used only for vertex‑based experiments), and (d) a sampled noise vector z. Unlike classic diffusion models that learn to predict the added noise ε, FaceDiffuser directly predicts the clean animation data ˆx₀, which aligns better with the conditional nature of the task and allows meaningful facial motion to emerge even in early denoising steps, thereby enabling faster sampling if desired.
Two model variants are defined: V‑FaceDiffuser for vertex‑based datasets (predicting V×3 coordinates) and B‑FaceDiffuser for blendshape‑based rigs (predicting C control values). Because blendshape data have far fewer dimensions, a dedicated Noise Encoder compresses the high‑dimensional noise into a compact latent space before it is fused with the audio embedding. The loss function is a simple L2 reconstruction term between the predicted sequence and the ground truth, optionally augmented with regularization terms that enforce geometric plausibility.
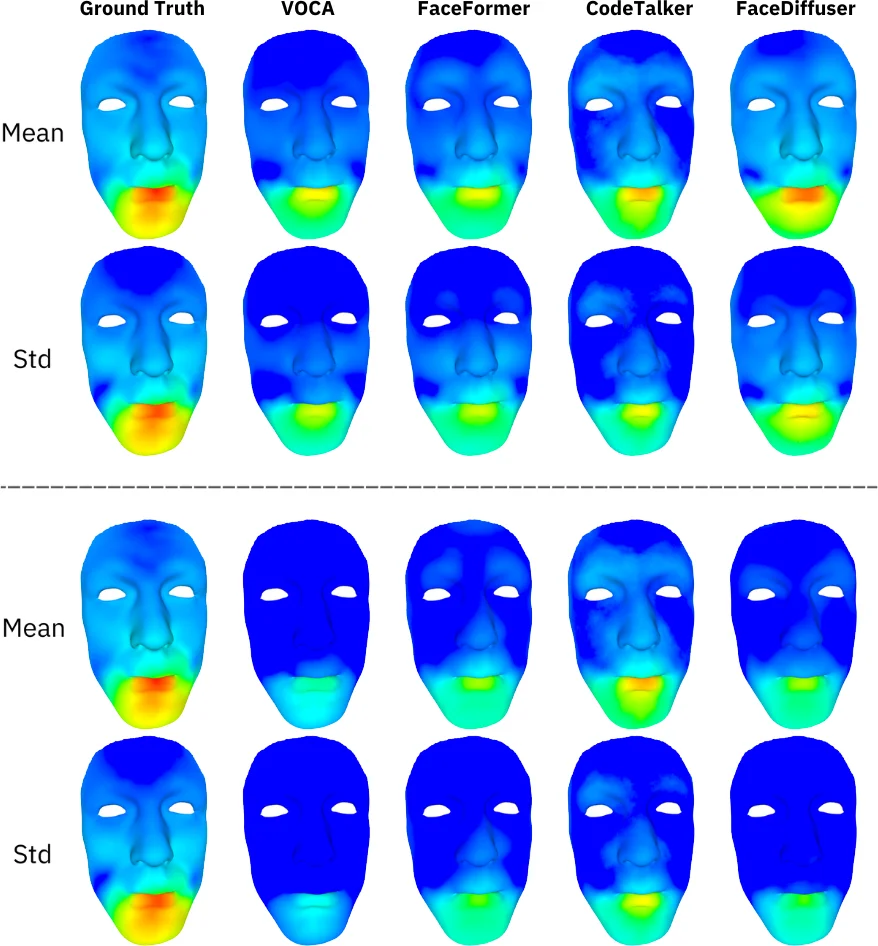
The authors evaluate the approach on five public 3D facial animation datasets—including VOCASET, BIWI, and HDTF—as well as an in‑house blendshape dataset captured from a rigged MetaHuman‑style character. Quantitative metrics such as L2 distance, MPJPE (mean per‑joint position error), and FVD (Frechet Video Distance) demonstrate that FaceDiffuser matches or surpasses state‑of‑the‑art deterministic baselines (VOCA, FaceFormer, FaceXHuBERT). More importantly, subjective user studies reveal that participants perceive the non‑deterministic samples as more natural and expressive, especially regarding eye movements and subtle facial dynamics.
Ablation studies confirm the importance of each design choice: removing the Noise Encoder degrades blendshape performance by roughly 8 %; reverting to noise‑prediction (instead of direct data prediction) leads to poor early‑stage outputs and lower overall quality; swapping HuBERT for a conventional MFCC encoder reduces performance by over 10 %, highlighting the value of a powerful self‑supervised speech representation.
The paper acknowledges several limitations. High‑resolution meshes (hundreds of thousands of vertices) impose significant GPU memory and computational demands, making real‑time deployment challenging. Currently the system supports only a single emotion dimension and requires a one‑hot identity vector for each speaker; extending to multi‑emotion, multi‑identity conditioning remains future work. Additionally, while the diffusion process can be accelerated using techniques like DDIM or classifier‑free guidance, the current implementation favors quality over speed.
In conclusion, FaceDiffuser is the first work to apply diffusion models to speech‑driven 3D facial animation, offering a principled way to generate diverse, high‑fidelity facial motions that respect both audio timing and non‑verbal variability. By supporting both vertex‑based meshes and blendshape rigs, it bridges a gap between research prototypes and production pipelines used in gaming, XR, and virtual‑human applications. The release of code and the new blendshape dataset further encourages reproducibility and future extensions, positioning FaceDiffuser as a strong foundation for more expressive, controllable, and realistic facial animation systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment