GME: GPU-based Microarchitectural Extensions to Accelerate Homomorphic Encryption
Fully Homomorphic Encryption (FHE) enables the processing of encrypted data without decrypting it. FHE has garnered significant attention over the past decade as it supports secure outsourcing of data processing to remote cloud services. Despite its promise of strong data privacy and security guarantees, FHE introduces a slowdown of up to five orders of magnitude as compared to the same computation using plaintext data. This overhead is presently a major barrier to the commercial adoption of FHE.In this work, we leverage GPUs to accelerate FHE, capitalizing on a well-established GPU ecosystem available in the cloud. We propose GME, which combines three key microarchitectural extensions along with a compile-time optimization to the current AMD CDNA GPU architecture. First, GME integrates a lightweight on-chip compute unit (CU)-side hierarchical interconnect to retain ciphertext in cache across FHE kernels, thus eliminating redundant memory transactions. Second, to tackle compute bottlenecks, GME introduces special MOD-units that provide native custom hardware support for modular reduction operations, one of the most commonly executed sets of operations in FHE. Third, by integrating the MOD-unit with our novel pipelined 64-bit integer arithmetic cores (WMAC-units), GME further accelerates FHE workloads by 19%. Finally, we propose a Locality-Aware Block Scheduler (LABS) that exploits the temporal locality available in FHE primitive blocks. Incorporating these microarchitectural features and compiler optimizations, we create a synergistic approach achieving average speedups of 796×, 14.2×, and 2.3× over Intel Xeon CPU, NVIDIA V100 GPU, and Xilinx FPGA implementations, respectively.
💡 Research Summary
The paper “GME: GPU-based Microarchitectural Extensions to Accelerate Homomorphic Encryption” tackles the severe performance gap that Fully Homomorphic Encryption (FHE) suffers when executed on conventional hardware. While FHE enables computation on encrypted data, its runtime can be up to five orders of magnitude slower than plaintext processing, hindering commercial adoption. The authors focus on the CKKS scheme, which supports approximate arithmetic on encrypted floating‑point data, and target AMD’s CDNA GPU family (specifically the MI100) because GPUs are widely available in cloud environments and provide massive parallelism.
The core contribution is a hardware‑software co‑design called GME that introduces four tightly coupled innovations:
-
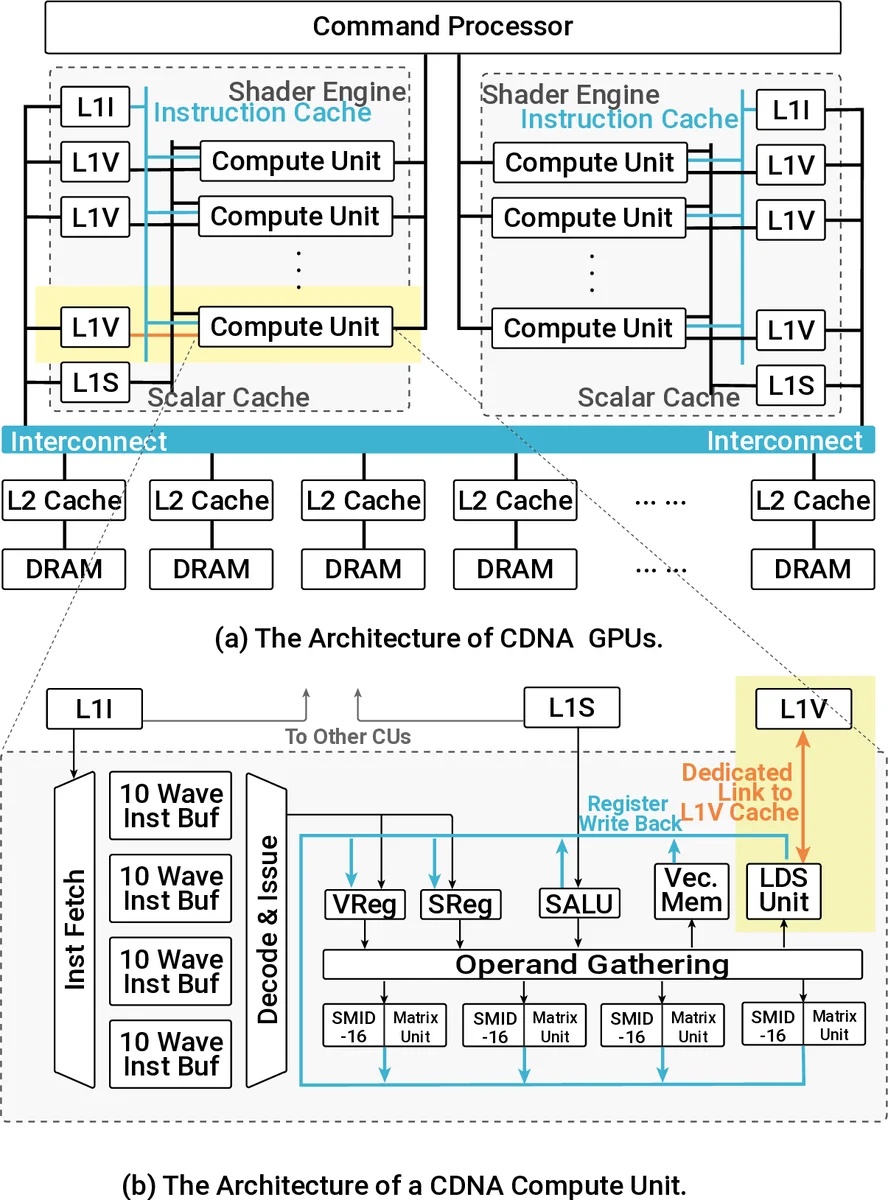
CU‑side hierarchical interconnect (cNoC) – a lightweight on‑chip network that connects the local data share (LDS) and L1 caches of each Compute Unit (CU). By retaining ciphertext fragments in this on‑chip fabric across kernel launches, redundant DRAM accesses are eliminated, dramatically reducing memory pressure.
-
Dedicated MOD‑units – custom arithmetic blocks that perform 64‑bit modular reduction (the most frequent operation in CKKS) using a pipelined Montgomery algorithm. These units replace the generic 32‑bit SIMD ALUs for reduction, cutting latency to a few cycles and providing a 10–12× speedup for reduction‑heavy kernels.
-
WMAC‑units – wide‑multiply‑accumulate pipelines that natively handle 64‑bit integer operations. Existing GPU pipelines are limited to 32‑bit, forcing two‑step sequences for 64‑bit work. WMAC‑units deliver a single‑cycle 64‑bit MAC, contributing an overall 19 % performance gain on top of the MOD‑units.
-
Locality‑Aware Block Scheduler (LABS) – a compile‑time scheduler that analyses the block‑level directed acyclic graph (DAG) of FHE primitives. LABS orders block execution to maximize temporal locality on the cNoC, ensuring that data needed by successive blocks stays within the same CU. This reduces L2 cache misses and DRAM traffic by 38 %.
To evaluate these ideas, the authors extend the cycle‑accurate AMD GPU simulator NaviSim with a new component called BlockSim, which models block‑level DAG execution and the added hardware features. Ablation studies isolate each microarchitectural addition, confirming that cNoC and LABS primarily alleviate memory bandwidth bottlenecks, while MOD‑ and WMAC‑units address compute bottlenecks.
Experimental results on CKKS‑based workloads (HE‑LR and encrypted ResNet‑20 inference) show that GME achieves an average 14.6× speedup over the prior state‑of‑the‑art GPU implementation, 796× over a high‑end Intel Xeon CPU, 14.2× over an NVIDIA V100, and 2.3× over a custom FPGA design. The authors also discuss the portability of their extensions: while the design is tuned for AMD CDNA, the concepts (on‑chip interconnect, modular reduction units, wide MAC pipelines, and locality‑aware scheduling) could be adapted to other GPU families with appropriate ISA and microarchitectural modifications.
The paper acknowledges limitations: the proposed hardware blocks increase silicon area and power consumption, and the current evaluation is simulation‑based rather than on silicon. Moreover, the extensions are specific to CKKS; other FHE schemes (e.g., BFV, TFHE) may require different optimizations. Future work includes prototyping the MOD‑ and WMAC‑units in ASIC/FPGA, extending the scheduler to handle dynamic workload variations, and exploring integration with emerging cloud GPU offerings.
In summary, GME demonstrates that targeted microarchitectural enhancements to commodity GPUs can close a substantial portion of the performance gap for homomorphic encryption, making privacy‑preserving cloud computation far more practical.
Comments & Academic Discussion
Loading comments...
Leave a Comment