Momentum-Net: Fast and convergent iterative neural network for inverse problems
Iterative neural networks (INN) are rapidly gaining attention for solving inverse problems in imaging, image processing, and computer vision. INNs combine regression NNs and an iterative model-based image reconstruction (MBIR) algorithm, often leadin…
Authors: Il Yong Chun, Zhengyu Huang, Hongki Lim
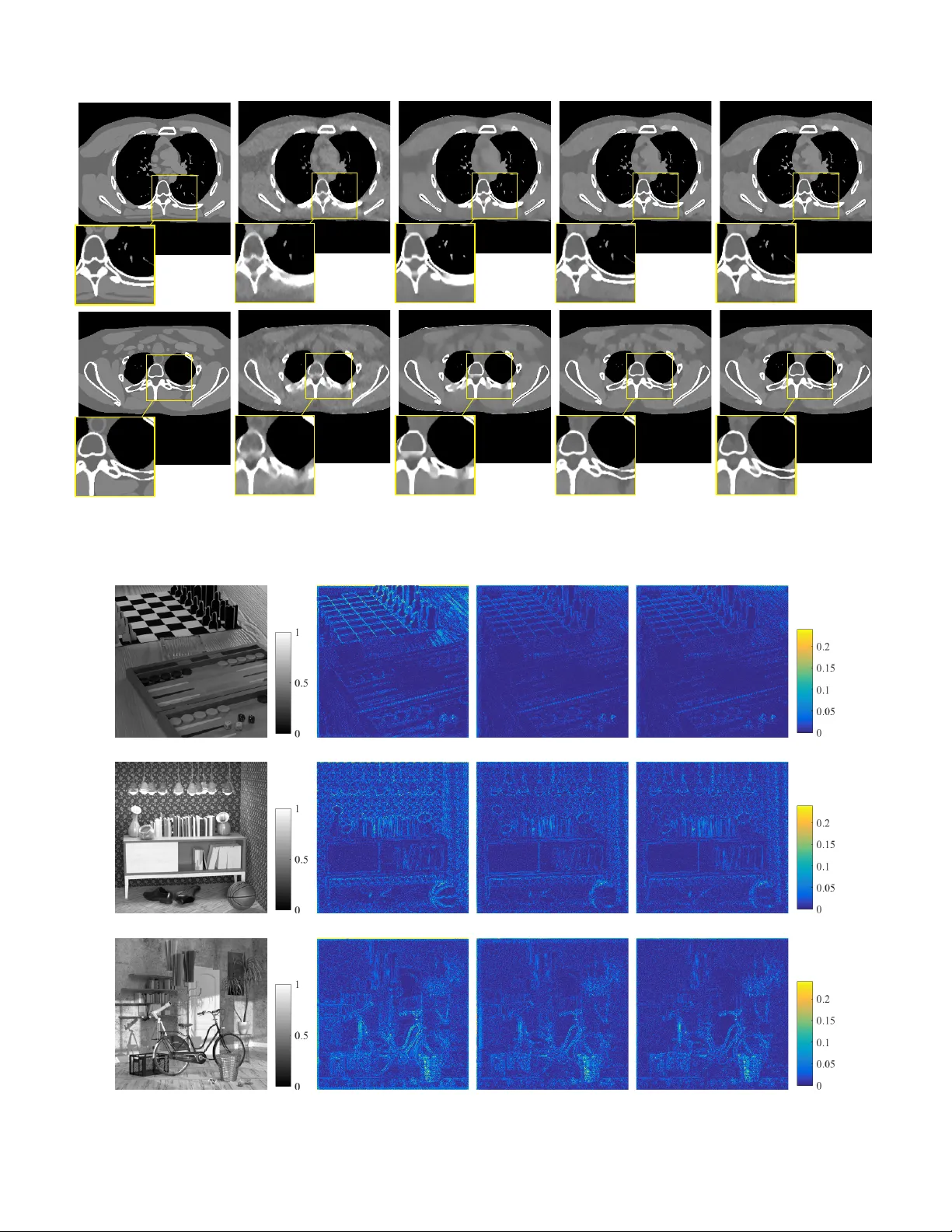
1 Momentum-Net: F ast and con v ergent iterativ e neural netw or k f or in v erse prob lems Il Y ong Chun, Member , IEEE, Zhengyu Huang ∗ , Hongki Lim ∗ , Student Member , IEEE, and Jeffrey A. F essler , Fello w , IEEE Abstract —Iterativ e neural networks (INN) are rapidly gaining attention for solving in verse problems in imaging, image processing, and computer vision. INNs combine regression NNs and an iterativ e model-based image reconstruction (MBIR) algor ithm, often leading to both good generalization capability and outperf or ming reconstruction quality over e xisting MBIR optimization models. This paper proposes the first fast and con vergent INN architecture, Momentum-Net , b y generalizing a bloc k-wise MBIR algor ithm that uses momentum and majorizers with regression NNs. F or fast MBIR, Momentum-Net uses momentum terms in extrapolation modules, and noniterativ e MBIR modules at each iteration by using majorizers , where each iteration of Momentum-Net consists of three core modules: image refining, extr apolation, and MBIR. Momentum-Net guarantees conv ergence to a fixed-point f or general differentiab le (non)conv ex MBIR functions (or data-fit terms) and conv ex f easible sets, under two asymptomatic conditions . T o consider data-fit variations across training and testing samples , we also propose a regularization parameter selection scheme based on the “spectral spread” of majorization matrices. Numerical experiments for light-field photogr aphy using a f ocal stack and sparse-view computational tomograph y demonstrate that, given identical reg ression NN architectures, Momentum-Net significantly improves MBIR speed and accuracy ov er sev eral existing INNs; it significantly impro ves reconstruction quality compared to a state-of-the-ar t MBIR method in each application. Index T erms —Iterative neural network, deep learning, model-based image reconstruction, inverse prob lems, block pro ximal extr apolated gradient method, bloc k coordinate descent method, light-field photography , X-ray computational tomogr aphy . F 1 I N T R O D U C T I O N D E E P regr ession neural network (NN) methods have been actively studied for solving diverse inverse prob- lems, due to their effectiveness at mapping noisy signals into clean signals. Examples include image denoising [1]– [4], image deconvolution [5], [6], image super-r esolution [7], [8], magnetic resonance imaging (MRI) [9], [10], X- ray computational tomography (CT) [11]–[13], and light- field (LF) photography [14], [15]. However , regression NNs with a gr eater mapping capability have increased overfit- ting/hallucination risks [16]–[19]. An alternative approach to solving inverse problems is an iterative NN (INN) that combines regr ession NNs – called “r efiners” or denoisers – with an unrolled iterative model-based image reconstruc- tion (MBIR) algorithm [20]–[27]. This alternative approach can regulate overfitting of regr ession NNs, by balancing physical data-fit of MBIR and prior information estimated by refining NNs [16], [18]. This “soft-refiner ” approach • The authors indicated by asterisks ( ∗ ) contributed equally to this work. • This work is supported in part by the Keck Foundation, NIH U01 EB018753, NIH R01 EB023618, NIH R01 EB022075, and NSF IIS 1838179. • Il Y ong Chun was with the Department of Electrical Engineering and Computer Science, The University of Michigan, Ann Arbor , MI 48019 USA, and is now with the Department of Electrical Engineering, the University of Hawai’i at M ¯ anoa, Honolulu, HI 96822 USA (email: iychun@hawaii.edu). Zhengyu Huang, Hongki Lim, and Jeffr ey A. Fessler are with the Department of Electrical Engineering and Computer Sci- ence, The University of Michigan, Ann Arbor , MI 48019 USA (email: zyhuang@umich.edu; hongki@umich.edu; fessler@umich.edu). • This paper has appendices. The pr efix “A ” indicate the numbers in section, theorem, equation, figure, table, and footnote in the appendices. • This paper was presented in part at the Allerton Conference on Commu- nication, Control, and Computing, Monticello, IL, USA, in Oct. 2018. has been successfully applied to several extr eme imaging systems, e.g., highly undersampled MRI [20], [25], [28]–[30], low-dose or sparse-view CT [16], [19], [24], [27], [31], and low-count emission tomography [18], [32]–[34]. 1.1 Notation This section provides mathematical notations. W e use f ( x ; y ) to denote a function f of x given y . W e use k·k p to denote the ` p -norm and write h· , ·i for the standard inner product on C N . The weighted ` 2 -norm with a Hermitian positive definite matrix A is denoted by k · k A = k A 1 2 ( · ) k 2 . The Fr obenius norm of a matrix is denoted by k · k F . ( · ) T , ( · ) H , and ( · ) ∗ indicate the transpose, complex conjugate transpose (Hermitian transpose), and complex conjugate, respectively . diag ( · ) denotes the conversion of a vector into a diagonal matrix or diagonal elements of a matrix into a vector . For (self-adjoint) matrices A, B ∈ C N × N , the notation B A denotes that A − B is a positive semi- definite matrix. 1.2 Fr om block-wise optimization to INN T o recover signals x ∈ C N from measurements y ∈ C m , consider the following MBIR optimization problem: argmin x ∈X F ( x ; y , z ) , F ( x ; y , z ) , f ( x ; y ) + γ 2 k x − z k 2 2 , (P0) where X is a set of feasible points, f ( x ; y ) is data-fit func- tion, γ is a regularization parameter , and z ∈ C N is some high-quality approximation to the true unknown signal x . 2 The data-fit f ( x ; y ) measures deviations of model-based predictions of x from data y , considering models of imaging physics (or image formation) and noise statistics in y . In (P0), the signal r ecovery accuracy incr eases as the quality of z improves [17, Prop. 3]; however , it is difficult to obtain such z in practice. Alternatively , there has been a growing trend in learning sparsifying regularizers (e.g., convolu- tional r egularizers [24], [35]–[38]) fr om training datasets and applying the trained regularizers to the following block- wise MBIR pr oblem: argmin x ∈X f ( x ; y ) + min ζ r ( x, ζ ; O ) . Here, a learned regularizer min ζ r ( x, ζ ; O ) quantifies con- sistency between x and r efined sparse signal ζ via some learned operators O . Recently , we have constructed INNs by generalizing the corr esponding block-wise MBIR updates with regression NNs without convergence analysis [25], [27]. In existing INNs, two major challenges exist: conver- gence and acceleration. 1.3 Challenges in existing INNs: Con vergence Existing convergence analysis has some practical limita- tions. The original form of plug-and-play (PnP [23], [39]– [41]) is motivated by the alternating direction method of multipliers (ADMM [42]), and its fixed-point convergence has been analyzed with consensus equilibrium perspectives [23]. However , similar to ADMM, its practical convergence depends on how one selects ADMM penalty parameters. For example, [22] reported unstable convergence behaviors of PnP-ADMM with fixed ADMM parameters. T o moder - ate this problem, [41] pr oposed a scheme that adaptively controls the ADMM parameters based on relative residuals. Similar to the residual balancing technique [42, § 3.4.1], the scheme in [41] requir es tuning initial parameters. Regu- larization by Denoising (RED [22]) is an alternative that moderates some such limitations. In particular , RED aims to make a clear connection between optimization and a de- noiser D , by defining its prior term by (scaled) x T ( x −D ( x )) . Nonetheless, [43] showed that many practical denoisers do not satisfy the Jacobian symmetry in [22], and proposed a less restrictive method, score-matching by denoising. The convergence analysis of the INN inspired by the re- laxed projected gradient descent (RPGD) method in [31] has the least restrictive conditions on the regr ession NN among the existing INNs. This method replaces the projector of a projected gradient descent method with an image refining NN. However , the RPGD-inspir ed INN directly applies an image refining NN to gradient descent updates of data-fit; thus, this INN r elies heavily on the mapping performance of a refining NN and can have overfitting risks, similar to non- MBIR regr ession NNs, e.g., FBPConvNet [12]. In addition, it exploits the data-fit term only for the first few iterations [31, Fig. 5(c)]. W e refer the perspective used in RPGD-inspir ed INN and its related works [26], [44] as “hard-r efiner ”: differ ent from soft-refiners, these methods do not use a refining NN as a regularizer . More r ecently , [26] pr esented convergence analysis for an INN inspir ed by a pr oximal gradient descent method. However , their analysis is based on noiseless measurements, which is typically impractical. Broadly speaking, existing convergence analysis largely depends on the (firmly) nonexpansive property of image refining NNs [22], [23], [43], [31, PGD], [26]. However , ex- cept for a single-hidden layer convolutional NN (CNN), it is yet unclear which analytical conditions guarantee the non- expansiveness of general refining NNs [27]. T o guarantee convergence of INNs even when using possibly expansive image refining NNs, we pr oposed a method that normalizes the output signal of image refining NNs by their Lipschitz constants [27]. However , if one uses expansive NNs that are identical acr oss iterations, it is dif ficult to obtain “best” image r ecovery with that normalization scheme. The spec- tral normalization based training [45], [46] can ensure the non-expansiveness of r efining NNs by single-step power iteration. However , similar to the normalization method in [27], r efining NNs trained with the spectral normalization method [46] degraded the image r econstruction accuracy for an INN using iteration-wise refining NNs [19]. In addition, there does not yet exist theor etical convergence results when refining NNs change across iterations, yet iteration-wise refining NNs are widely studied [20], [21], [25], [28]. Finally , existing analysis considers only a narrow class of data-fit terms: most analyses consider a quadratic function with a linear imaging model [26], [31] or more generally , a convex cost function [23], [43], [46] that can be minimized with a practical closed-form solution. No theoretical convergence results exist for general (non)convex data-fit terms, iteration- wise NN denoisers, and a general set of feasible points. 1.4 Challenges in existing INNs: Acceleration Compared to non-MBIR regr ession NNs that do not exploit the data-fit f ( x ; y ) in (P0), INNs requir e more computation because they consider the imaging physics. Computation increases as the imaging system or image formation model becomes larger -scale, e.g., LF photography from a focal stack, 3D CT , parallel MRI using many receive coils, and image super -resolution. Thus, acceleration becomes crucial for INNs. First, consider the existing methods motivated by ADMM or block coordinate descent (BCD) method: ex- amples include PnP-ADMM [23], [41], RED-ADMM [22], [43], MoDL [30], BCD-Net [16], [18], [25], etc. These meth- ods can require multiple inner iterations to balance data- fit and prior information estimated by trained refining NNs, increasing total MBIR time. For example, in solv- ing such problems, each outer iteration involves x ( i +1) = argmin x F ( x ; y , z ( i +1) ) , where F is given as in (P0) and z ( i +1) is the output from the i th image refining NN. For LF imaging system using a focal stack data [47], solving the above pr oblem requir es multiple iterations, and the total computational cost scale with the numbers of photosensors and sub-aperture images. In addition, nonconvexity of the data-fit term f ( x ; y ) can br eak conver gence guarantees of these methods, because in general, the proximal mapping argmin x f ( x ; y ) + γ k x − z ( i +1) k 2 2 is no longer nonexpansive. Second, consider the existing works motivated by gra- dient descent methods [21], [26], [28], [31]. These methods resolve the inner iteration issue; however , they lack a sophis- ticated step-size contr ol or backtracking scheme that influ- ences conver gence guarantee and acceleration. Accelerated proximal gradient (APG) methods using momentum terms can significantly accelerate convergence rates for solving composite convex pr oblems [48], [49], so we expect that INN methods in the second class have yet to be maximally accel- erated. The work in [44] applied PnP to the APG method 3 [49]; [50] applied PnP to the primal-dual splitting (PDS) algorithm [51]. However , similar to RPGD [31], these are hard-r efiner methods using some state-of-the-art denoisiers (e.g., BM3D [52]) but not trained NNs. Those methods lack convergence analyses and guarantees may be limited to convex data-fit function. 1.5 Contrib utions and organization of the paper This paper proposes Momentum-Net , the first INN ar chitec- ture that aims for fast and convergent MBIR. The architec- ture of Momentum-Net is motivated by applying the Block Proximal Extrapolated Gradient method using a Majorizer (BPEG-M) [24], [35] to MBIR using trainable convolutional autoencoders [24], [25], [37]. Specifically , each iteration of Momentum-Net consists of thr ee core modules: image re- fining, extrapolation, and MBIR. At each Momentum-Net iteration, an extrapolation module uses momentum from previous updates to amplify the changes in subsequent iterations and accelerate convergence, and an MBIR module is noniterative . In addition, Momentum-Net resolves the con- vergence issues mentioned in § 1.3: for general differentiable (non)convex data-fit terms and convex feasible sets, it guar- antees convergence to a point that satisfies fixed-point and critical point conditions, under some mild conditions and two asymptotic conditions, i.e., asymptotically nonexpansive paired refining NNs and asymptotically block-coordinate mini- mizer . The remainder of this paper is organized as follows. § 2 constructs the Momentum-Net architecture motivated by BPEG-M algorithm that solves MBIR problem using a learn- able convolutional regularizer , describes its relation to ex- isting works, analyzes its convergence, and summarizes the benefits of Momentum-Net over existing INNs. § 3 provides details of training INNs, including image refining NN ar chi- tectures, single-hidden layer or “shallow” CNN (sCNN) and multi-hidden layer or “deep” CNN (dCNN), and training loss function, and proposes a regularization parameter se- lection scheme to consider data-fit variations across training and testing samples. § 4 considers two extreme imaging applications: sparse-view CT and LF photography using a focal stack. § 4 reports numerical experiments of applications where the proposed Momentum-Net using extrapolation significantly improves MBIR speed and accuracy , over the existing INNs, BCD-Net [22], [25], [30], Momentum-Net us- ing no extrapolation [21], [28], ADMM-Net [20], [23], [41], and PnP-PDS [50] using refining NNs. Furthermore, § 4 reports numerical experiments where Momentum-Net significantly improves reconstruction quality compared to a state-of-the- art MBIR method in each application. 2 M O M E N T U M - N E T : W H E R E B P E G - M M E E T S N N S F O R I N V E R S E P R O B L E M S 2.1 Motiv ation: BPEG-M algorithm for MBIR using learnable con v olutional regulariz er This section motivates the proposed Momentum-Net archi- tecture, based on our pr evious works [24], [37]. Consider the following approach for recovering signal x from measure- ments y (see the setup of block multi-(non)convex problems in § A.1.1): argmin x ∈X f ( x ; y ) + γ min { ζ k } r ( x, { ζ k } ; { h k } ) , r ( x, { ζ k } ; { h k } ) , K X k =1 1 2 k h k ∗ x − ζ k k 2 2 + β k k ζ k k 1 , (1) where X is a closed set, f ( x ; y ) + γ r ( x, { ζ k } ; { h k } ) is a (continuosly) differentiable (non)convex function in x , min { ζ k } r ( x, { ζ k } ; { h k } ) is a learnable convolutional r egu- larizer [24], [36], { ζ k : k = 1 , . . . , K } is a set of sparse featur es that correspond to { h k ∗ x } , { h k ∈ C R : k = 1 , . . . , K } is a set of trainable filters, and R and K denote the size and number of trained filters, respectively . Problem (1) can be viewed as a two-block optimization problem in terms of the image x and the features { ζ k } . W e solve (1) using the recent BPEG-M optimization framework [24], [35] that has attractive convergence guarantee and rapidly solved several block optimization problems [24], [35], [53]–[55]. BPEG-M has the following key ideas for each block optimization problem (see details in § A.1): • M b -Lipschitz continuity for the gradient of the b th block optimization problem, ∀ b : Definition 1 ( M -Lipschitz continuity [24]) . A function g : R n → R n is M -Lipschitz continuous on R n if there exists a (symmetric) positive definite matrix M such that k g ( u ) − g ( v ) k M − 1 ≤ k u − v k M , ∀ u, v ∈ R n . Definition 1 is a more general concept than the classical Lipschitz continuity . • A sharper majorization matrix M that gives a tighter bound in Definition 1 leads to a tighter quadratic ma- jorization bound in the following lemma: Lemma 2 (Quadratic majorization via M -Lipschitz con- tinuous gradients [24]) . Let f ( u ) : R n → R . If ∇ f is M -Lipschitz continuous, then f ( u ) ≤ f ( v ) + h∇ u f ( v ) , u − v i + 1 2 k u − v k 2 M , ∀ u, v ∈ R n . Having tighter majorization bounds, sharper majoriza- tion matrices tend to accelerate BPEG-M convergence. • The majorized block problems are “proximable”, i.e., proximal mapping of majorized function is “easily” computable depending on the pr operties of b th block majorizer and r egularizer , M b and r b , where the proxi- mal mapping operator is defined by Pro x M b r b ( z ) , argmin u 1 2 k u − z k 2 M b + r b ( u ) , ∀ b. (2) • Block-wise extrapolation and momentum terms to accel- erate convergence. Suppose that 1) gradient of f ( x ; y ) + γ r ( x, { ζ k } ; { h k } ) is M -Lipschitz continuous at an extrapolated point ´ x ( i +1) , ∀ i ; 2) filters in (1) satisfy the tight-frame (TF) condition, P K k =1 k h k ∗ u k 2 2 = k u k 2 2 , ∀ u , for some boundary conditions 4 !!𝑥 ($) !𝑥 ($& ') arg min .∈𝒳 𝑥 − !𝑥 2 $ &' + 𝑀 5 $&' 6' 𝛻𝐹(!𝑥 2 $ &' ; 𝑦 , 𝑧 ($ &') ) = 5 >? @ A Meas ur ement 1 − 𝜌 ( D ) + 𝜌ℛ F (>?@) ( D ) ! !!𝑧 ($& ') !𝑦 Ref ining MBIR !!𝑥 ($6 ') 𝑥 ($) + 𝐸 $& ' (𝑥 ($) − 𝑥 ($6 ') ) Ext r apo lat i o n !𝑥 2 ($& ') “Momentum” (a) Momentum-Net !!" #$% !" #$& '% !!()*+,- ./0 1 #" 2 3 4 5 # $&'% % ! Meas ur ement 6 7 #89: % #;% !!5 #$& '% !3 Ref ining MBIR (b) BCD-Net [25] Fig. 1. Architectures of diff erent INNs f or MBIR. (a–b) The architectures of Momentum-Net and BCD-Net [25] are constructed by generalizing BPEG- M and BCD algorithms that solve MBIR prob lem using a conv olutional regular izer trained via con volutional analysis operator lear ning (CAOL) [24], [36], respectively . (a) Removing extr apolation modules (i.e., setting the extrapolation matr ices { E ( i +1) : ∀ i } as a z ero matrix), Momentum-Net specializes to the existing gradient-descent-inspired INNs [21], [28]. When the MBIR cost function F ( x ; y , z ( i +1) ) in (P1) has a shar p major izer f M ( i +1) , ∀ i , Momentum-Net (using ρ ≈ 1 ) specializes to BCD-Net; see Examples 5–6. (b) BCD-Net is a general v ersion of the existing INNs in [20], [22], [23], [30], [39]–[41] by using iteration-wise image refining NNs , i.e., {R θ ( i +1) : ∀ i } , or considering general conv ex data-fit f ( x ; y ) . [24]. Applying the BPEG-M framework (see Algorithm A.1) to solving (1) leads to the following block updates: z ( i +1) = K X k =1 flip( h ∗ k ) ∗ T β k ( h k ∗ x ( i ) ) , (3) ´ x ( i +1) = x ( i ) + E ( i +1) x ( i ) − x ( i − 1) , (4) x ( i +1) = Prox f M ( i +1) I X ´ x ( i +1) − f M ( i +1) − 1 ∇ F ( ´ x ( i +1) ; y , z ( i +1) ) , (5) where E ( i +1) is an extrapolation matrix that is given in (8) or (9) below , f M ( i +1) is a (scaled) majorization matrix for ∇ F ( x ; y , z ( i +1) ) that is given in (7) below , ∀ i , the proximal operator Prox f M ( i +1) I X ( · ) in (5) is given by (2), and I X ( x ) is the characteristic function of set X (i.e., I X equals to 0 if x ∈ X , and ∞ otherwise). Proximal mapping update (3) has a single-hidden layer convolutional autoencoder architecture that consists of en- coding convolution, nonlinear thresholding, and decoding convolution, wher e flip( · ) flips a filter along each dimension, and the soft-thr esholding operator T α ( u ) : C N → C N is defined by ( T α ( u )) n , u n − α · sign( u n ) , | u n | > α, 0 , otherwise , (6) for n = 1 , . . . , N , in which sign( · ) is the sign function. See details of deriving BPEG-M updates (3)–(5) in § A.1.4. The BPEG-M updates in (3)–(5) guarantee convergence to a critical point, when MBIR problem (1) satisfies some mild conditions, e.g., lower-boundedness and existence of critical points; see Assumption S.1 in § A.1.3. The following section generalizes the BPEG-M updates in (3)–(5) and constructs the Momentum-Net architecture. 2.2 Ar chitecture This section establishes the INN architecture of Momentum- Net by generalizing BPEG-M updates (3)–(5) that solve (1). Specifically , we replace the pr oximal mapping in (3) with Algorithm 1 Momentum-Net Require: {R θ ( i ) : i = 1 , . . . , N iter } , ρ ∈ (0 , 1) , γ > 0 , x (0) = x ( − 1) , y for i = 0 , . . . , N iter − 1 do Calculate f M ( i +1) by (7), and E ( i +1) by (8) or (9) Image refining : z ( i +1) = (1 − ρ ) x ( i ) + ρ R θ ( i +1) x ( i ) (Alg.1.1) Extrapolation : ´ x ( i +1) = x ( i ) + E ( i +1) x ( i ) − x ( i − 1) (Alg.1.2) MBIR : x ( i +1) = Pro x f M ( i +1) I X ´ x ( i +1) − f M ( i +1) − 1 ∇ F ( ´ x ( i +1) ; y , z ( i +1) ) (Alg.1.3) end for a general image refining NN R θ ( · ) , where θ denotes the trainable parameters. T o ef fectively remove iteration-wise artifacts and give “best” signal estimates at each iteration, we further generalize a refining NN R θ ( · ) to iteration-wise image refining NNs {R θ ( i +1) ( · ) : i = 0 , . . . , N iter − 1 } , wher e θ ( i +1) denotes the parameters for the i th iteration r efining NN R θ ( i +1) , and N iter is the number of Momentum-Net iterations. The iteration-wise NNs are particularly useful for reducing overfitting risks in regression, because R θ ( i +1) is responsible for removing noise features only at the i th iteration, and thus one does not need to greatly increase dimensions of its parameter θ ( i +1) [16], [18]. In low-dose CT reconstruction, for example, the refining NNs at the early and later iterations remove streak artifacts and Gaussian- like noise, respectively [16]. Each iteration of Momentum-Net consists of 1) image r e- fining, 2) extrapolation, and 3) MBIR modules, correspond- ing to the BPEG-M updates (3), (4), and (5), respectively . See the architecture of Momentum-Net in Fig. 1(a) and Algorithm 1. At the i th iteration, Momentum-Net performs the following three processes: 5 • Refining : The i th image r efining module gives the “re- fined” image z ( i +1) , by applying the i th r efining NN, R θ ( i +1) , to an input image at the i th iteration, x ( i ) (i.e., image estimate fr om the ( i − 1)th iteration). Differ ent from existing INNs, e.g., ADMM-Net [20], PnP-ADMM [23], [41], RED [22], MoDL [30], BCD-Net [25] (see Fig. 1(b)), TNRD [21], [28], we apply ρ -relaxation with ρ ∈ (0 , 1) ; see (Alg.1.1). The parameter ρ controls the strength of inference from refining NNs, but does not affect the convergence guarantee of Momentum-Net. Proper selection of ρ can improve MBIR accuracy (see § A.10). • Extrapolation : The i th extrapolation module gives the extrapolated point ´ x ( i +1) , based on momentum terms x ( i ) − x ( i − 1) ; see (Alg.1.2). Intuitively speaking, momen- tum is information from previous updates to amplify the changes in subsequent iterations. Its effectiveness has been shown in diverse optimization literature, e.g., convex optimization [48], [49] and block optimization [24], [35]. • MBIR : Given a refined image z ( i +1) and a measurement vector y , the i th MBIR module (Alg.1.3) applies the proximal operator Prox f M ( i +1) I X ( · ) to the extrapolated gra- dient update using a quadratic majorizer of F ( x ; y , z ( i +1) ) , where F is defined in (P0). Intuitively speaking, this step solves a majorized version of the following MBIR problem at the extrapolated point ´ x ( i +1) : min x ∈X F ( x ; y , z ( i +1) ) , (P1) and gives a reconstructed image x ( i +1) . In Momentum- Net, we consider (non)convex differentiable MBIR cost functions F with M -Lipschitz continuous gradients, and a convex and closed set X . For a wide range of large- scale inverse imaging problems, the majorized MBIR problem (Alg.1.3) has a practical closed-form solution and thus, does not r equire an iterative solver , depending on the pr operties of practically invertible majorization matrices M ( i +1) and constraints. Examples of M ( i +1) - X combinations that give a noniterative solution for (Alg.1.3) include scaled identity and diagonal matrices with a box constraint and the non-negativity constraint, and matrices decomposable by unitary transforms, e.g., a circulant matrix [56], [57], with X = C N . The updated image x ( i +1) is the input to the next Momentum-Net iteration. The followings are details of Momentum-Net in Algo- rithm 1. A scaled majorization matrix is f M ( i +1) = λ · M ( i +1) 0 , λ ≥ 1 , (7) where M ( i +1) ∈ R N × N is a symmetric positive definite majorization matrix of ∇ F ( x ; y , z ( i +1) ) in the sense of M - Lipschitz continuity (see Definition 1). In (7), λ = 1 and λ > 1 for convex and nonconvex F ( x ; y , z ( i +1) ) (or convex and nonconvex f ( x ; y ) ), respectively . W e design the extrap- olation matrices as follows: for convex F , E ( i +1) = δ 2 m ( i ) · M ( i +1) − 1 2 M ( i ) 1 2 ; (8) for nonconvex F , E ( i +1) = δ 2 m ( i ) · λ − 1 2( λ + 1) · M ( i +1) − 1 2 M ( i ) 1 2 , (9) for some δ < 1 and { 0 ≤ m ( i ) ≤ 1 : ∀ i } . W e update the momentum coef ficients { m ( i +1) : ∀ i } by the following formula [24], [35]: m ( i +1) = θ ( i ) − 1 θ ( i +1) , θ ( i +1) = 1 + q 1 + 4( θ ( i ) ) 2 2 ; (10) if F ( x ; y , z ( i +1) ) has a sharp majorizer , i.e., ∇ F ( x ; y , z ( i +1) ) has M ( i +1) such that the corresponding bound in Defini- tion 1 is tight, then we set m ( i +1) = 0 , ∀ i . § A.11 lists parameters of Momentum-Net, and summarizes selection guidelines or gives default values. 2.3 Relations to previous w orks Several existing MBIR methods can be viewed as a special case of Momentum-Net: Example 3. (MBIR model (1) using convolutional autoen- coders that satisfy the TF condition [24]). The BPEG- M updates in (3)–(5) ar e special cases of the modules in Momentum-Net (Algorithm 1), with {R θ ( i +1) ( · ) = P K k =1 flip( h ∗ k ) ∗ T β k ( h k ∗ ( · )) : ∀ i } (i.e., single hidden-layer convolutional autoencoder [24]) and ρ ≈ 1 . These give a clear mathematical connection between a denoiser (3) and cost function (1). One can find a similar relation between a multi-hidden layer CNN and a multi-layer convolutional regularizer [24, Appx.]. Example 4. (INNs inspired by gradient descent method, e.g., TNRD [21], [28]). Removing extrapolation modules, i.e., setting { E ( i +1) = 0 : ∀ i } in (Alg.1.2), and setting ρ ≈ 1 , Momentum-Net becomes the existing INN in [21], [28]. Example 5. (BCD-Net for image denoising [25]). T o obtain a clean image x ∈ R N from a noisy image y ∈ R N corrupted by an additive white Gaussian noise (A WGN), MBIR prob- lem (P1) considers the data-fit f ( x ; y ) = 1 2 k y − x k 2 W with the inverse covariance matrix W = 1 σ 2 I , where σ 2 is a variance of A WGN, and the box constraint X = [0 , U ] N with an upper bound U > 0 . For this f ( x ; y ) , the MBIR module (Alg.1.3) can use the exact majorizer { f M ( i +1) = ( 1 σ 2 + γ ) I } and one does not need to use the extrapolation module (Alg.1.2), i.e., { E ( i +1) = 0 } . Thus, Momentum-Net (with ρ ≈ 1 ) becomes BCD-Net. Example 6. (BCD-Net for undersampled single-coil MRI [25]). T o obtain an object magnetization x ∈ R N from a k -space data y ∈ C m obtained by undersampling (e.g., com- pressed sensing [58]) MRI, MBIR problem (P1) considers the data-fit f ( x ; y ) = 1 2 k y − Ax k 2 W with an undersampling Fourier operator A (disregarding relaxation effects and con- sidering Cartesian k -space), the inverse covariance matrix W = 1 σ 2 I , wher e σ 2 is a variance of complex A WGN [59], and X = C N . For this f ( x ; y ) , the MBIR module (Alg.1.3) can use the exact majorizer { f M ( i +1) = F H disc ( 1 σ 2 P + γ I ) F disc } that is practically invertible, where F disc is the discrete Fourier transform and P is a diagonal matrix with either 0 or 1 (their positions correspond to sampling pattern in k - space), and the extrapolation module (Alg.1.2) uses the zero extrapolation matrices { E ( i +1) = 0 } . Thus, Momentum-Net (with ρ ≈ 1 ) becomes BCD-Net. 6 20 40 60 80 100 Ite rat ions ( i ) 0 0.2 0.4 0.6 0.8 1 k θ ( i ) − θ ( i − 1 ) k 2 / k θ ( i ) k 2 LF photo. using fo cal stack Sparse-view CT Fig. 2. Conv ergence behavior of Momentum-Net’ s dCNNs refiners {R θ ( i ) } in different applications ( θ ( i ) denotes the parameter vector of the i th iteration refiner R θ ( i ) , for i = 1 , . . . , N iter ; see details of {R θ ( i ) } in (19) and § 4.2.1; N iter = 100 ). Sparse-view CT (fan-beam geometr y with 12 . 5 % projections views): R θ ( i ) quickly converges , where ma- jorization matrices of training data-fits have similar condition numbers. LF photograph y using a focal stac k (five detectors and reconstructed LFs consists of 9 × 9 sub-aper ture images): R θ ( i ) has slower conver- gence, where majorization matrices of training data-fits have largely different condition n umbers. The following section analyzes the convergence of Momentum-Net. 2.4 Con vergence analysis In practice, INNs, i.e., “unrolled” or PnP methods using refining NNs, ar e trained and used with a specific number of iterations. Nevertheless, similar to optimization algorithms, studying convergence properties of INNs with N iter → ∞ [23], [31], [46] is important; in particular , it is crucial to know if a given INN tends to converge as N iter increases. For INNs using iteration-wise refining NNs, e.g., BCD-Net [25] and proposed Momentum-Net, we expect that refin- ers converge, i.e., their image refining capacity converges, because information provided by data-fit function f ( x ; y ) in MBIR (e.g., likelihood) reaches some “bound” after a certain number of iterations. Fig. 2 illustrates that dCNN parameters of Momentum-Net tend to conver ge for different applications. (The similar behavior was r eported for sCNN refiners in BCD-Net [16].) Although refiners do not com- pletely converge, in practice, one could use a r efining NN at a sufficiently large iteration number , e.g., N iter = 100 in Momentum-Net, for the later iterations. There are two key challenges in analyzing the conver- gence of Momentum-Net in Algorithm 1: both challenges relate to its image r efining modules (Alg.1.1). First, image re- fining NNs R θ ( i +1) change across iterations; even if they are identical across iterations, they are not necessarily nonex- pansive operators [60], [61] in practice. Second, the iteration- wise refining NNs are not necessarily proximal mapping operators, i.e., they are not written explicitly in the form of (2). This section proposes two new asymptotic definitions to overcome these challenges, and then uses those conditions to analyze convergence properties of Momentum-Net in Algorithm 1. 2.4.1 Preliminaries T o resolve the challenge of iteration-wise refining NNs and the practical difficulty in guaranteeing their non- expansiveness, we introduce the following generalized def- inition of the non-expansiveness [60], [61]. Definition 7 (Asymptotically nonexpansive paired opera- tors) . A sequence of paired operators ( R θ ( i ) , R θ ( i +1) ) is asymp- totically nonexpansive if there exist a summable nonnegative sequence { ( i +1) ≥ 0 : P ∞ i =0 ( i +1) < ∞} such that 1 kR θ ( i +1) ( u ) − R θ ( i ) ( v ) k 2 2 ≤ k u − v k 2 2 + ( i +1) , ∀ u, v , i. (11) When R θ ( i +1) = R θ and ( i +1) = 0 , ∀ i , Definition 7 becomes the standard non-expansiveness of a mapping op- erator R θ . If we replace the inequality ( ≤ ) with the strict in- equality ( < ) in (11), then we say that the sequence of paired operators ( R θ ( i +1) , R θ ( i +1) ) is asymptotically contractive. (This str onger assumption is used to prove convergence of BCD-Net in Proposition A.5.) Definition 7 also implies that mapping operators R θ ( i +1) converge to some nonexpansive operator , if the corresponding parameters θ ( i +1) converge. Definition 7 incorporates a pairing property because Momentum-Net uses iteration-wise image refining NNs. Specifically , the pairing property helps prove convergence of Momentum-Net, by connecting image r efining NNs at adjacent iterations. Furthermore, the asymptotic property in Definition 7 allows Momentum-Net to use expansive r efining NNs (i.e., mapping operators having a Lipschitz constant larger than 1 ) for some iterations, while guaranteeing con- vergence; see Figs. 3(a3) and 3(b3). Suppose that refining NNs ar e identical across iterations, i.e., R θ ( i +1) = R θ , ∀ i , similar to some existing INNs, e.g., PnP [23], RED [22], and other methods in § 1.3. In such cases, if R θ is expansive, Momentum-Net may diverge; this property corresponds to the limitation of existing methods described in § 1.3. Momentum-Net moderates this issue by using iteration- wise refining NNs that satisfy the asymptotic paired non- expansiveness in Definition 7. Because the sequence { z ( i +1) : ∀ i } in (Alg.1.1) is not necessarily updated with a proximal mapping, we intr oduce a generalized definition of block-coordinate minimizers [53, (2.3)] for z ( i +1) -updates: Definition 8 (Asymptotic block-coordinate minimizer) . The update z ( i +1) is an asymptotic block-coordinate minimizer if there exists a summable nonnegative sequence { ∆ ( i +1) ≥ 0 : P ∞ i =0 ∆ ( i +1) < ∞} such that z ( i +1) − x ( i ) 2 2 ≤ z ( i ) − x ( i ) 2 2 + ∆ ( i +1) , ∀ i. (12) Definition 8 implies that as i → ∞ , the updates { z ( i +1) : i ≥ 0 } approach a block-coordinate minimizer trajectory that satisfies (12) with { ∆ ( i +1) = 0 : i ≥ 0 } . In particular , ∆ ( i +1) quantifies how much the update z ( i +1) in (Alg.1.1) perturbs a block-coor dinate minimizer trajectory . The bound k z ( i +1) − x ( i ) k 2 2 ≤ k z ( i ) − x ( i ) k 2 2 always holds, ∀ i , when one uses the proximal mapping in (3) within the BPEG-M framework. Note that while applying trained Momentum- Net, (12) is easy to examine empirically , whereas (11) is harder to check. 2.4.2 Assumptions This section introduces and interprets the assumptions for convergence analysis of Momentum-Net in Algorithm 1: 1. One could replace the bound in (11) with kR θ ( i +1) ( u ) − R θ ( i ) ( v ) k 2 2 ≤ (1 + ( i +1) ) k u − v k 2 2 (and summable { ( i +1) : ∀ i } ), and the proofs for our main arguments go through. 7 (a) Sparse-view CT : Condition numbers of data-fit majorizers have mild variations. (a1) { ∆ ( i ) : i ≥ 2 } (a2) { ( i ) : i ≥ 2 } (a3) { κ ( i ) : i ≥ 1 } 20 40 60 80 100 Ite rati ons ( i ) 0 0.2 0.4 0.6 0.8 1 No rma lize d ∆ ( i ) 20 40 60 80 100 Ite rati ons ( i ) 0 0.2 0.4 0.6 0.8 1 No rma lize d ǫ ( i ) 20 40 60 80 100 Ite rati ons ( i ) 0.9 1 1.1 1.2 Lip schitz c onst ., κ ( i ) (b) LF photography using a focal stack: Condition numbers of data-fit majorizers have large variations. (b1) { ∆ ( i ) : i ≥ 2 } (b2) { ( i ) : i ≥ 2 } (b3) { κ ( i ) : i ≥ 1 } 20 40 60 80 100 Ite rati ons ( i ) 0 0.2 0.4 0.6 0.8 1 No rma lize d ∆ ( i ) 20 40 60 80 100 Ite rati ons ( i ) 0 0.2 0.4 0.6 0.8 1 No rma lize d ǫ ( i ) 20 40 60 80 100 Ite rati ons ( i ) 0.9 1 1.1 1.2 Lip schitz c onst ., κ ( i ) Fig. 3. Empirical measures related to Assumption 4 for guaranteeing con vergence of Momentum-Net using dCNNs refiners (for details, see (19) and § 4.2.1), in different applications. See estimation procedures in § A.2. (a) The sparse-view CT reconstr uction experiment used fan-beam geometry with 12 . 5 % projections views. (b) The LF photograph y experiment used five detectors and reconstructed LFs consisting of 9 × 9 sub- aper ture images . (a1, b1) For both the applications , we obser ved that ∆ ( i ) → 0 . This implies that the z ( i +1) -updates in (Alg.1.1) satisfy the asymptotic block-coordinate minimizer condition in Assumption 4. (Magenta dots denote the mean values and b lack ver tical error bars denote standard deviations.) (a2) Momentum-Net trained from training data-fits, where their majorization matr ices have mild condition number variations, shows that ( i ) → 0 . This implies that paired NNs ( R θ ( i +1) , R θ ( i ) ) in (Alg.1.1) are asymptotically nonexpansive . (b2) Momentum-Net trained from training training data-fits, where their majorization matr ices have mild condition number variations, shows that ( i ) becomes close to zero , b ut does not conv erge to zero in one hundred iterations. (a3, b3) The NNs, R θ ( i +1) in (Alg.1.1), become nonexpansiv e, i.e., its Lipschitz constant κ ( i ) becomes less than 1 , as i increases. • Assumption 1) In MBIR problems (P1), (non)convex F ( x ; y , z ( i +1) ) is (continuously) differentiable, proper , and lower-bounded in dom( F ) , 2 ∀ i , and X is convex and closed. Algorithm 1 has a fixed-point. • Assumption 2) ∇ F ( x ; y , z ( i +1) ) is M ( i +1) -Lipschitz con- tinuous with respect to x (see Definition 1), where M ( i +1) is a iteration-wise majorization matrix that satis- fies m F, min I N M ( i +1) m F, max I N with 0 < m F, min ≤ m F, max < ∞ , ∀ i . • Assumption 3) The extrapolation matrices E ( i +1) 0 in (8)–(9) satisfy the following conditions: for convex F , E ( i +1) T M ( i +1) E ( i +1) δ 2 · M ( i ) , δ < 1; (13) for nonconvex F , E ( i +1) T M ( i +1) E ( i +1) δ 2 ( λ − 1) 2 4( λ + 1) 2 · M ( i ) , δ < 1 . (14) • Assumption 4) The sequence of paired operators ( R θ ( i +1) , R θ ( i ) ) is asymptotically nonexpansive with a summable sequence { ( i + i ) ≥ 0 } ; the update z ( i +1) is an asymptotic block-coordinate minimizer with a summable sequence { ∆ ( i + i ) ≥ 0 } . The mapping func- tions {R θ ( i +1) : ∀ i } are continuous with respect to input points and the corresponding parameters { θ ( i +1) : ∀ i } are bounded. 2. F : R n → ( −∞ , + ∞ ] is proper if dom F 6 = ∅ . F is lower bounded in dom( F ) , { u : F ( u ) < ∞} if inf u ∈ dom( F ) F ( u ) > −∞ . Assumption 1 is a slight modification of Assumption S.1 of BPEG-M, and Assumptions 2–3 are identical to Assump- tions S.2–S.3 of BPEG-M; see Assumptions S.1–S.3 in § A.1.3. The extrapolation matrix designs (8) and (9) satisfy condi- tions (13) and (14) in Assumption 3, respectively . W e provide empirical justifications for the first two conditions in Assumption 4. First, Figs. 3(a2) and A.1(a2) illustrate that paired r efining NNs ( R θ ( i +1) , R θ ( i ) ) of Momentum-Net appear to be asymptotically nonexpansive in an application that has mild condition number variations across training data-fit majorization matrices. Figs. 3(a3), 3(b3), A.1(a3), and A.1(b3) illustrate for differ ent applica- tions that refining NNs {R θ ( i +1) } become nonexpansive: their Lipschitz constants at the first several iterations ar e larger than 1 , and their Lipschitz constants in later iter- ations become less than 1 . Alternatively , the asymptotic non-expansiveness of paired operators ( R θ ( i +1) , R θ ( i ) ) can be satisfied by a stronger assumption that the sequence {R θ ( i +1) } converges to some nonexpansive operator . (Fig. 2 illustrates that dCNN parameters of Momentum-Net appear to converge.) Figs. 3(a3), 3(b3), A.1(a3), and A.1(b3) illustrate for dif- ferent applications that the z ( i +1) -updates are asymptotic block-coordinate minimizers. Lemma A.4 and § A.3 in the appendices pr ovide a probabilistic justification for the asymp- totic block-coordinate minimizer condition. 8 2.4.3 Main conv ergence results This section analyzes fixed-point and critical point conver- gence of Momentum-Net in Algorithm 1, under the assump- tions in the previous section. W e first show that differ ences between two consecutive iterates generated by Momentum- Net converge to zero: Proposition 9 (Convergence properties) . Under Assumptions 1–4, let { x ( i +1) , z ( i +1) : i ≥ 0 } be the sequence generated by Algorithm 1. Then, the sequence satisfies ∞ X i =0 x ( i +1) z ( i +1) − x ( i ) z ( i ) 2 2 < ∞ , (15) and hence x ( i +1) z ( i +1) − x ( i ) z ( i ) 2 → 0 . Proof. See § A.4 in the appendices. Using Proposition 9, our main theorem provides that any limit points of the sequence generated by Momentum-Net satisfy critical point and fixed-point conditions: Theorem 10 (A limit point satisfies both critical point and fixed-point conditions) . Under Assumptions 1–4 above, let { x ( i +1) , z ( i +1) : i ≥ 0 } be the sequence generated by Algo- rithm 1. Consider either a fixed majorization matrix with general structure, i.e., M ( i +1) = M for i ≥ 0 , or a sequence of diagonal majorization matrices, i.e., { M ( i +1) : i ≥ 0 } . Then, any limit point ¯ x of { x ( i +1) } satisfies both the critical point condition: h∇ F ( ¯ x ; y , ¯ z ) , x − ¯ x i ≥ 0 , ∀ x ∈ X , (16) where ¯ z is a limit point of { z ( i +1) } , and the fixed-point condition: ¯ x ¯ x = A ¯ M R ¯ θ ¯ x ¯ x , (17) where h x ( i +1) x ( i ) i = A M ( i +1) R θ ( i +1) h x ( i ) x ( i − 1) i , A M ( i +1) R θ ( i +1) ( · ) denotes per- forming the i th updates in Algorithm 1, and ¯ θ and ¯ M is a limit point of { θ ( i +1) } and { M ( i +1) } , respectively . Proof. See § A.5 in the appendices. Observe that, if X = R N or ¯ x is an interior point of X , (16) reduces to the first-order optimality condition 0 ∈ ∂ F ( ¯ x ; y , ¯ z ) , where ∂ F ( x ) denotes the limiting subdiffer- ential of F at x . W ith additional isolation and boundedness assumptions for the points satisfying (16) and (17), we obtain whole sequence guarantees: Corollary 11 (Whole sequence conver gence) . Consider the construction in Theorem 10. Let S be the set of points satisfying the critical point condition in (16) and the fixed-point condition in (17). If { x ( i +1) : i ≥ 0 } is bounded, then dist( x ( i +1) , S ) → 0 , where dist( u, V ) , inf {k u − v k : v ∈ V } denotes the distance from u to V , for any point u ∈ R N and any subset V ⊂ R N . If S contains uniformly isolated points, i.e., there exists η > 0 such that k u − v k ≥ η for any distinct points u, v ∈ S , then { x ( i +1) } converges to a point in S . Proof. See § A.6 in the appendices. The boundedness assumption for { x ( i +1) } in Corol- lary 11 is standard in block-wise optimization, e.g., [24], [35], [53], [55], [62]. The assumption can be satisfied if the set X is bounded (e.g., box constraints), one chooses appropriate regularization parameters in Algorithm 1 [24], [35], [55], the function F ( x ; y , z ) is coercive [62], or the level set is bounded [53]. However , for general F ( x ; y , z ) , it is hard to verify the isolation condition for the points in S in practice. Instead, one may use Kurdyka-Łojasiewicz property [53], [62] to analyze the whole sequence convergence with some appropriate modifications. For simplicity , we focused our discussion to noniter- ative MBIR module (Alg.1.3). However , Momentum-Net practically converges with any proximable MRIR function (Alg.1.3) that may need an iterative solver , if sufficient inner iterations are used. T o maximize the computational benefit of Momentum-Net, one needs to make sure that majorized MBIR function (Alg.1.3) is better pr oximable over its original form (P1). 2.5 Benefits of Momentum-Net Momentum-Net has several benefits over existing INNs: • Benefits fr om r efining module : The image refining mod- ule (Alg.1.1) can use iteration-wise image refining NNs {R θ ( i +1) : i ≥ 0 } : those are particularly useful to r educe overfitting risks by reducing dimensions of their param- eters θ ( i +1) at each iteration [16], [18], [19]. Iteration- wise refining NNs require less memory for training, compared to methods that use a single refining NN for all iterations, e.g., [63]. Differ ent from the exist- ing methods mentioned in § 1.3, Momentum-Net does not requir e (firmly) nonexpansive mapping operators {R θ ( i +1) } to guarantee convergence. Instead, {R θ ( i +1) } in (Alg.1.1) assumes a generalized notion of the (firm) non-expansiveness condition assumed for convergence of the existing methods that use identical refining NNs across iterations, including PnP [20], [23], [39]–[41], [46], RED [22], [43], etc. The generalized concept is the first practical condition to guarantee convergence of INNs using iteration-wise refining NNs; see Definition 7. • Benefits fr om extrapolation module : The extrapolation mod- ule (Alg.1.2) uses the momentum terms x ( i ) − x ( i − 1) that accelerate the convergence of Momentum-Net. In particular , compared to the existing gradient-descent- inspired INNs, e.g., TNRD [21], [28], Momentum-Net converges faster . (Note that the way the authors of [43] used momentum is less conventional. The correspond- ing method, RED-APG [43, Alg. 6], still can require multiple inner iterations to solve its quadratic MBIR problem, similar to BCD-Net-type methods.) • Benefits from MBIR module : The MBIR module (Alg.1.3) does not r equire multiple inner iterations for a wide range of imaging problems and has both theoretical and practical benefits. Note first that conver gence analysis of INNs (including Momentum-Net) assumes that their MBIR operators are noniterative . In other words, related convergence theory (e.g., Proposition A.5) is inapplica- ble if iterative methods, particularly with insufficient number of iterations, are applied to MBIR modules. Differ ent from the existing BCD-Net-type methods [20], [22], [23], [25], [30], [39]–[41], [43] that can require it- erative solvers for their MBIR modules, MBIR mod- ule (Alg.1.3) of Momentum-Net can have practical close- form solution (see examples in § 2.2), and its correspond- ing convergence analysis (see § 2.4) can hold stably for a 9 wide range of imaging applications. Second, combined with extrapolation module (Alg.1.2), noniterative MBIR modules (Alg.1.3) lead to faster MBIR, compared to the existing BCD-Net-type methods that can requir e multi- ple inner iterations for their MBIR modules for conver- gence. Third, Momentum-Net guarantees convergence even for nonconvex MBIR cost function F ( x ; y , z ) or nonconvex data-fit f ( x ; y ) of which the gradient is M - Lipschitz continuous (see Definition 1), while existing INNs overlooked nonconvex F ( x ; y , z ) or f ( x ; y ) . Furthermore, § A.7 analyzes the sequence convergence of BCD-Net [25], and describes the convergence benefits of Momentum-Net over BCD-Net. 3 T R A I N I N G I N N S This section describes training of all the INNs compared in this paper . 3.1 Ar chitecture of refining NNs and their training For all INNs in this paper , we train the refining NN at each iteration to remove artifacts fr om the input image x ( i ) that is fed from the previous iteration. For the i th iteration NN, we first consider the following sCNN architecture, residual single-hidden layer convolutional autoencoder: R θ ( i +1) ( u ) = K X k =1 d ( i +1) k ∗ T exp( α ( i +1) k ) e ( i +1) k ∗ u + u, (18) where θ ( i +1) = { d ( i +1) k , α ( i +1) k , e ( i +1) k : ∀ k } is the parameter set of the i th image r efining NN, { d ( i +1) k , e ( i +1) k ∈ C R : k = 1 , . . . , K } is a set of K decoding and encoding filters of size R , { exp( α ( i +1) k ) : k = 1 , . . . , K } is a set of K thr esholding values, and T α ( u ) is the soft-thresholding operator with parameter α defined in (6), for i = 0 , . . . , N iter − 1 . W e use the exponential function exp( · ) to prevent the thresholding parameters { α k } from becoming negative during training. W e observed that the residual convolutional autoencoder in (18) gives better results compar ed to the convolutional autoencoder , i.e., (18) without the second term [18], [25]. This corresponds to the empirical result in [64], [65] that having skip connections (e.g., the second term in (18)) can impr ove generalization. The sequence of pair ed sCNN refiners (18) can satisfy the asymptotic non-expansiveness, if its convergent refiner satisfies that σ max ( D H D ) ≤ 1 /R , σ max ( E H E ) ≤ 1 /R, where σ max ( · ) is the largest eigenvalue of a matrix, D , [ ¯ d 1 , . . . , ¯ d K , δ R ] , E , [ ¯ e 1 , . . . , ¯ e K , δ R ] , { ¯ d k , ¯ e k : ∀ k } are limit point filters, and δ R is the Kronecker delta filter of size R . For dCNN refiners, we use the following residual multi- hidden layer CNN architecture, a simplified DnCNN [4] using fewer layers, no pooling, and no batch normalization [46] (we drop superscript indices ( · ) ( i ) for simplicity): R θ ( u ) = u − K X k =1 e [ L ] k ∗ u [ L − 1] k , (19) u [1] k = ReLU e [1] k ∗ u , u [ l ] k = ReLU K X k 0 =1 e [ l ] k,k 0 ∗ z [ l − 1] k 0 ! , for k = 1 , . . . , K and l = 2 , . . . , L − 1 , where θ = { e [ l ] k , e [ l ] k,k 0 : ∀ k , k 0 , l } is the parameter set of each refining NN, K is the number of feature maps, L is the number of layers, { e [ l ] k ∈ R R : k = 1 , . . . , K, l = 1 , L } is a set of filters at the first and last dCNN layer , { e [ l ] k,k 0 ∈ R R : k , k 0 = 1 , . . . , K , l = 2 , . . . , L − 1 } is a set of filters for r emaining dCNN layer , and the r ectified linear unit activation function is defined by ReLU( u ) , max(0 , u ) . The training process of Momentum-Net requires S high- quality training images, { x s : s = 1 , . . . , S } , S training mea- surements simulated via imaging physics, { y s : s = 1 , . . . , S } , and S data-fits { f s ( x ; y s ) : s = 1 , . . . , S } and the corre- sponding majorization matrices { M ( i ) s , f M ( i ) s : s = 1 , . . . , S, i = 1 , . . . , N iter } . Differ ent from [16], [25], [66] that train con- volutional autoencoders from the patch perspective, we train the image refining NNs in (18)–(19) from the convo- lution perspective (that does not store many overlapping patches, e.g., see [24]). From S training pairs ( x s , x ( i ) s ) , where { x ( i ) s : s = 1 , . . . , S } is a set of S reconstructed images at the ( i − 1)th Momentum-Net iteration, we train the i th iteration image refining NN in (18) by solving the following optimization problem: θ ( i +1) = argmin θ 1 2 S S X s =1 x s − R θ ( x ( i ) s ) 2 2 , (P2) where θ ( i +1) is given as in (18), for i = 0 , . . . , N iter − 1 (see some related properties in § A.8). W e solve the training optimization pr oblems (P2) by mini-batch stochastic opti- mization with the subdif ferentials computed by the PyT orch Autograd package. 3.2 Regularization parameter selection based on “spectral spread” When majorization matrices of training data-fits { f s ( x ; y s ) : s = 1 , . . . , S } have similar spectral properties, e.g., condition numbers, the regularization parameter γ in (P1) is trainable by substituting (Alg.1.1) into (Alg.1.3) and modifying the training cost (P2). However , the condition numbers of data- fit majorizers can greatly differ due a variety of imaging geometries or image formation systems, or noise levels in training measurements, etc. See such examples in § 4.1–4.2. T o train Momentum-Net with diverse training data-fits, we propose a parameter selection scheme based on the “spectral spread” of their majorization matrices { M ( i ) f s } . For simplicity , consider majorization matrices of the form f M ( i ) s = f M s = λ ( M f s + γ s I ) ∀ i , where the factor λ is selected by (7) and M f s is a symmetric positive semidefinite majorization matrix for f s ( x ; y s ) , ∀ s . W e select the r egular- ization parameter γ s for the s th training sample as γ s = σ spread ( M f s ) χ , (20) where the spectral spread of a symmetric positive definite matrix is defined by σ spread ( · ) , σ max ( · ) − σ min ( · ) for σ max ( M f s ) > σ min ( M f s ) ≥ 0 , and σ min ( · ) is the smallest eigenvalue of a matrix. For the s th training sample, a tunable factor χ contr ols γ s in (20) accor ding to σ spread ( M f s ) , ∀ s . The proposed parameter selection scheme also applies to testing Momentum-Net, based on the tuned factor χ ? in its 10 training. W e observed that the pr oposed parameter selection scheme (20) gives better MBIR accuracy than the condition number based selection scheme that is similarly used in selecting ADMM parameters [17] (for the two applications in § 4). One may further apply this scheme to iteration- wise majorization matrices f M ( i ) s and select iteration-wise regularization parameters γ ( i ) s accordingly . For comparing differ ent INNs, we apply (20) to all INNs. 4 E X P E R I M E N TA L R E S U LT S A N D D I S C U S S I O N W e investigated two extreme imaging applications: sparse- view CT and LF photography using a focal stack. In par - ticular , these two applications lack a practical closed-form solution for the MBIR modules of BCD-Net and ADMM- Net [20], e.g., solving (Alg.2.2). For these applications, we compared the performances of the following five INNs: BCD-Net [25] (i.e., generalization of RED [22] and MoDL [30]), ADMM-Net [20], i.e., PnP-ADMM [23], [41] using iteration-wise refining NNs, Momentum-Net without extrap- olation (i.e., generalization of TNRD [21], [28]), PDS-Net, i.e., PnP-PDS [50] using iteration-wise refining NNs, and the proposed Momentum-Net using extrapolation. 4.1 Experimental setup: Imaging 4.1.1 Sparse-vie w CT T o reconstruct a linear attenuation coefficient image x ∈ R N from post-log sinogram y ∈ R m in sparse-view CT , the MBIR problem (P1) considers a data-fit f ( x ; y ) = 1 2 k y − Ax k 2 W and the non-negativity constraint X = [0 , ∞ ) N , where A ∈ R m × N is an undersampled CT system matrix, W ∈ R m × m is a diagonal weighting matrix with elements { W m 0 ,m 0 = p 0 2 m / ( p 0 m + σ 2 ) : ∀ m 0 } based on a Poisson- Gaussian model [17], [67] for the pre-log raw measurements p ∈ R m with electronic readout noise variance σ 2 . W e simulated 2D sparse-view sinograms of size m = 888 × 123 – ‘detectors or rays’ × ‘regularly spaced projection views or angles’, where 984 is the number of full views – with GE LightSpeed fan-beam geometry corresponding to a monoenergetic source with 10 5 incident photons per ray and no background events, and electr onic noise variance σ 2 = 5 2 . W e avoided an inverse crime in imaging simulation and r econstructed images of size N = 420 × 420 with a coarser grid ∆ x = ∆ y = 0 . 9766 mm; see details in [37, § V -A2]. 4.1.2 LF photograph y using a focal stack T o r econstruct a LF x = [ x T 1 , . . . , x 0 C ] T ∈ R S N 0 that consists of C 0 sub-aperture images from focal stack measurements y = [ y T 1 , . . . , y T C ] T ∈ R C N 0 that are collected by C photosen- sors, the MBIR problem (P1) considers a data-fit f ( x ; y ) = 1 2 k y − Ax k 2 2 and a box constraint X = [0 , U ] C 0 N 0 with U = 1 (or 255 without rescaling), where A ∈ R C N 0 × C 0 N 0 is a system matrix of LF imaging system using a focal stack that is constructed blockwise with C · C 0 differ ent convolution matrices { τ c A 0 c,c 0 ∈ R N 0 × N 0 : c = 1 , . . . , C , c 0 = 1 , . . . , C 0 } [47], [68], τ c ∈ (0 , 1] is a transparency coefficient for the c th Algorithm 2 BCD-Net [25] Require: {R θ ( i ) : i = 1 , . . . , N iter } , γ > 0 , x (0) = x ( − 1) , y for i = 0 , . . . , N iter − 1 do Image refining : z ( i +1) = R θ ( i +1) x ( i ) (Alg.2.1) MBIR : x ( i +1) = argmin x ∈X F ( x ; y , z ( i +1) ) (Alg.2.2) end for detector , and N 0 is the size of sub-aperture images, x c 0 , ∀ c 0 . 3 In general, a LF photography system using a focal stack is extremely under-determined, because C C 0 . T o avoid an inverse crime, our imaging simulation used higher-r esolution synthetic LF dataset [70] (we converted the original RGB sub-aperture images to grayscale ones by the “ rgb2gray.m ” function in MA TLAB, for simplicity and smaller memory requir ements in training). W e simulated C = 5 focal stack images of size N 0 = 255 × 255 with 40 dB A WGN that models electronic noise at sensors, and setting transparency coef ficients τ c as 1 , for c = 1 , . . . , C . The sensor positions wer e chosen such that five sensors focus at equally spaced depths; specifically , the closest sensor to scenes and farthest sensor from scenes focus at two differ ent depths that correspond to ‘ disp min + 0 . 2 ’ and ‘ disp max − 0 . 2 ’, respec- tively , where disp max and disp min are the approximate maximum and minimum disparity values specified in [70]. W e reconstructed 4D LFs that consist of S = 9 × 9 sub- aperture images of size N 0 = 255 × 255 , with a coarser grid ∆ x = ∆ y = 0 . 13572 mm. 4.2 Experimental setup: INNs 4.2.1 P arameters of INNs The parameters for the INNs compar ed in sparse-view CT experiments were defined as follows. W e considered two BCD-Nets (see Algorithm 2): for one BCD-Net, we applied the APG method [49] with 10 inner iterations to (Alg.2.2), and set N iter = 30 ; for the other BCD-Net, we applied the APG method with 3 inner iterations to (Alg.2.2), and set N iter = 45 . For ADMM-Net, we used the identical configu- rations as BCD-Net and set the ADMM penalty parameter to γ in (P1), similar to [16]. For Momentum-Net without extrapolation, we chose N iter = 100 and ρ = 1 − ε . For the proposed Momentum-Net, we chose N iter = 100 and ρ = 0 . 5 . For PDS-Net, we set the first step size to γ 1 = γ − 1 and the second step size to γ 2 = γ − 1 1 σ − 1 max ( M ) , per [50]. For performance comparisons between different INNs, all the INNs used sCNN refiners (18) with { R, K = 7 2 } to avoid the overfitting/hallucination risks. For Momentum- Net using dCNN refiners, we chose L = 4 layer dCNN (19) using R = 3 2 filters and K = 64 feature maps, following [46]. (The chosen parameters gave lower RMSE values than { L = 6 , R = 3 3 , K = 64 } , for identical regularization parame- ters.) For comparing dif ferent MBIR methods, Momentum 3. T raditionally , one obtains focal stacks by physically moving imag- ing sensors and taking separate exposures across time. T ransparent photodetector arrays [47], [69] allow one to collect focal stack data in a single exposure, making a practical LF camera using a focal stack. If some photodetectors are not perfectly transparent, one can use τ c < 1 , for some c . 11 used extrapolation, i.e., (Alg.1.2) with (8) and (10), and { R = 7 2 , K = 9 2 } for (18). W e designed the majorization matrices as { f M ( i +1) = diag ( A T W A 1) + γ I : i ≥ 0 } , using Lemma A.7 ( A and W have nonnegative entries) and setting λ = 1 by (7). W e set an initial point of INNs, x (0) , to filtered- back pr ojection (FBP) using a Hanning window . The regular- ization parameters of all INNs were selected by the scheme in § 3.2 with χ ? = 167 . 64 . (This factor was estimated from the carefully chosen regularization parameter for sparse- view CT MBIR experiments using learned convolutional regularizers in [24].) The parameters for the INNs compared in experiments of LF photography using a focal stack wer e defined as fol- lows. W e consider ed two BCD-Nets and two ADMM-Nets with the identical parameters listed above. For Momentum- Net without extrapolation and the pr oposed Momentum- Net, we set N iter = 100 and ρ = 1 − ε . For PDS-Net, we used the identical parameter setup described above. For performance comparisons between dif ferent INNs, all the INNs used sCNN refiners (18) with { R = 5 2 , K = 32 } (to avoid the overfitting risks) in the epipolar domain. For Momentum-Net using dCNN refiners, we chose L = 6 layer dCNN (19) using R = 3 2 filters and K = 16 feature maps. (The chosen parameters gave most accurate performances over the following setups, { L = 4 , R = 3 2 , K = 16 , 32 , 64 } , given the identical regularization parameters.) T o generate R θ ( i +1) ( x ( i ) ) in (Alg.1.1), we applied a sCNN (18) with { R = 5 2 , K = 32 } or a dCNN (19) with { L = 6 , R = 3 2 , K = 16 } to two sets of horizontal and vertical epipolar plane images, and took the average of two LFs that wer e permuted back from refined horizontal and vertical epipolar plane image sets, ∀ i . 4 W e designed the majorization matrices as { f M ( i +1) = diag( A T A 1) + γ I : i ≥ 0 } , using Lemma A.7 and setting λ = 1 by (7). W e set an initial point of INNs, x (0) , to A T y rescaled in the interval [0 , 1] (i.e., dividing by its max value). The regularization parameters (i.e., γ in BCD-Net/Momentum-Net, the ADMM penalty parameter in ADMM-Net, and the first step size in PDS-Net) were selected by the proposed scheme in § 3.2 with χ ? = 1 . 5 . (W e tuned the factor to achieve the best performances). For dif ferent combinations of INNs and sCNN refiner (18)/dCNN refiner (19), we use the following naming con- vention: ‘the INN name’-‘sCNN’ or ‘dCNN’. 4.2.2 T raining INNs For sparse-view CT experiments, we trained all the INNs from the chest CT dataset with { x s , y s , f s ( x ; y s ) = 1 2 k y s − Ax k 2 W s , f M s : s = 1 , . . . , S, S = 142 } ; we constructed the dataset by using XCA T phantom slices [71]. The CT ex- periment has mild data-fit variations across training sam- ples: the standard deviation of the condition numbers ( , σ max ( · ) /σ min ( · ) ) of { M f s = diag( A T W s A 1) : ∀ s } is 1 . 1 . For experiments of LF photography using a focal stack, we trained all the INNs from the LF photography dataset with { y s , f s ( x ; y s ) = 1 2 k y s − A s x k 2 2 , f M s : s = 1 , . . . , S, S = 21 } and 4. Epipolar images are 2D slices of a 4D LF L F ( c x , c y , c u , c v ) , where ( c x , c y ) and ( c u , c v ) are spatial and angular coordinates, respectively . Specifically , each horizontal epipolar plane image ar e obtained by fixing c y and c v , and varying c x and c u ; and each vertical epipolar image are obtained by fixing c x and c u , and varying c y and c v . two sets of gr ound truth epipolar images, { x s, epi-h , x s, epi-v : s = 1 , . . . , S, S = 21 · (255 · 9) } ; we constructed the dataset by excluding four unr ealistic “stratified” scenes from the original LF dataset in [70] that consists of 28 LFs with diverse scene parameter and camera settings. The LF ex- periment has lar ge data-fit variations across training sam- ples: the standard deviation of the condition numbers of { M f s = diag( A T s A s 1) : ∀ s } is 2245 . 5 . In training INNs for both the applications, if not spec- ified, we used identical training setups. At each iteration of INNs, we solved (P2) with the mini-batch version of Adam [72] and trained iteration-wise sCNNs (18) or dC- NNs (19). W e selected the batch size and the number of epochs as follows: for sparse-view CT reconstr uction, we chose them as 20 & 300 , and 20 & 200 for sCNN and dCNN refiners, r espectively; for LF photography using a focal stack, we chose them as 200 & 200 , and 200 & 100 , for sCNN and dCNN r efiners, respectively . W e chose the learning rates for filters in sCNNs and dCNNs, and thresh- olding values { α ( i +1) k : ∀ k , i } in sCNNs (18), as 10 − 3 and 10 − 1 , r espectively; we reduced the learning rates by 10 % every 10 epochs. At the first iteration, we initialized filter coefficients with Kaiming uniform initialization [73]; in the later iteration, i.e., at the i th INN iteration, for i ≥ 2 , we initialized filter coefficients from those learned from the previous iteration, i.e., ( i − 1)th iteration (this also applies to initializing thresholding values). 4.2.3 T esting trained INNs In sparse-view CT reconstruction experiments, we tested trained INNs to two samples wher e gr ound tr uth images and the corr esponding inverse covariance matrices (i.e., W in § 4.1.1) sufficiently differ from those in training samples (i.e., they ar e a few cm away fr om training images). W e eval- uated the reconstruction quality by the most conventional error metric in CT application, RMSE (in HU), in a region of interest (ROI), wher e RMSE and HU stand for root-mean- square error and (modified) Hounsfield unit, respectively , and the ROI was a circular region that includes all the phantom tissues. The RMSE is defined by RMSE( x ? , x true ) , ( P N ROI j =1 ( x ? j − x true j ) 2 /N ROI ) 1 / 2 , wher e x ? is a reconstructed image, x true is a gr ound truth image, and N ROI is the number of pixels in a ROI. In addition, we compared the trained Momentum-Net (using extrapolation) to a standard MBIR method using a hand-crafted EP regularizer , and an MBIR model using a learned convolutional r egularizer [24], [37] which is the state-of-the-art MBIR method within an unsu- pervised learning setup. W e finely tuned their regularization parameters to achieve the lowest RMSE. See details of these two MBIR models in § A.9.2. In experiments of LF photography using a focal stack, we tested trained INNs to thr ee samples of which scene parameter and camera settings are differ ent from those in training samples (all training and testing samples have differ ent camera and scene parameters). W e evaluated the reconstruction quality by the most conventional err or metric in LF photography application, PSNR (in dB), where PSNR stands for peak signal-to-noise. In addition, we compared the trained Momentum-Net (using extrapolation) to MBIR method using the state-of-the-art non-trained r egularizer , 4D EP introduced in [47]. (The low-rank plus sparse tensor 12 (a) Momentum-Net vs. (b) BCD-Net vs. PDS-Net [50] ADMM-Net [20], [23], [41] 0 20 40 60 80 Iter atio ns ( i ) 20 30 40 50 RM SE (H U) PDS-Net-sCNN Momentum-Net-sCNN 0 10 20 30 40 Iter atio ns ( i ) 20 30 40 50 R M S E ( H U ) ADMM-Net-sCNN, 3 inner BCD-Net-sCNN, 3 inner ADMM-Net-sCNN, 10 inner BCD-Net-sCNN , 10 inner Fig. 4. RMSE minimization comparisons between different INNs for sparse-view CT (fan-beam geometr y with 12 . 5 % projections views and 10 5 incident photons; (a) averaged RMSE values across two test re- fined images; (b) aver aged RMSE values across two test reconstructed images). 0 50 100 150 200 250 Re cons tru ctio n t ime (s ec) 20 25 30 35 40 45 50 RM SE (H U) BCD-Net-sCNN, 10 inner iter. BCD-Net-sCNN, 3 inner iter. Momentum-Net-sCNN, no extr ap olation Momentum-Net-sCNN Momentum-Net-dCNN Fig. 5. RMSE minimization comparisons between different INNs for sparse-view CT (fan-beam geometr y with 12 . 5 % projections views and 10 5 incident photons; a veraged RMSE v alues across two test recon- structed images). decomposition model [68], [74] failed when inverse crimes and measurement noise are consider ed.) W e finely tuned its r egularization parameter to achieve the lowest RMSE values. See details of this MBIR model in § A.9.3. W e further investigated impacts of the LF MBIR quality on a higher- level depth estimation application, by applying the robust Spinning Parallelogram Operator (SPO) depth estimation method [75] to reconstructed LFs. For comparing Momentum-Net with PDS-Net, we mea- sured quality of refined images, z ( i +1) in (Alg.1.1), because PDS-Net is a hard-refiner . The imaging simulation and reconstruction experiments were based on the Michigan image reconstr uction tool- box [76], and training INNs, i.e., solving (P2), was based on PyT orch (for sparse-view CT , we used ver . 1.2.0; for LF photography using a focal stack, we used ver . 0.3.1). For sparse-view CT , single-precision MA TLAB and PyT orch implementations were tested on 2 . 6 GHz Intel Core i7 CPU with 16 GB RAM, and 1405 MHz Nvidia T itan Xp GPU with 12 GB RAM, respectively . For LF photography using a focal stack, they were tested on 3 . 5 GHz AMD Thr eadripper 1920X CPU with 32 GB RAM, and 1531 MHz Nvidia GTX 1080 T i GPU with 11 GB RAM, respectively . 4.3 Comparisons between different INNs First, compar e sCNN r esults in Figs. 4–5 and Figs. 6–7, for sparse-view CT and LF photography using a focal stack, re- spectively . For both applications, the proposed Momentum- Net using extrapolation significantly improves MBIR speed (a) Momentum-Net vs. (b) BCD-Net vs. PDS-Net [50] ADMM-Net [20], [23], [41] 0 20 40 60 80 Iter atio ns ( i ) 26 28 30 32 34 PS NR (dB ) Momentum-Net-sCNN PDS-Net-sCNN 0 10 20 30 40 Iter atio ns ( i ) 26 28 30 32 34 P S N R ( d B ) BCD-Net-sCNN , 3 iter. ADMM-Net-sCNN, 3 iter. ADMM-Net-sCNN, 10 iter. BCD-Net-sCNN, 10 iter. Fig. 6. PSNR maximization compar isons between different INNs in LF photograph y using a focal stack (LF photog raphy systems with C = 5 detectors obtain a focal stack of LFs consisting of S = 81 sub-aper ture images; (a) a veraged RMSE v alues across two test refined images); (b) av eraged RMSE values across two test reconstructed images. 0 50 100 150 200 Re cons tru ctio n t ime (s ec) 26 28 30 32 34 PS NR (d B) Momentum-Net-dCNN Momentum-Net-sCNN Momentum-Net-sCNN, no extr ap olation BCD-Net-sCNN, 3 inner iter. BCD-Net-sCNN, 10 inner iter. Fig. 7. PSNR maximization compar isons between different INNs in LF photograph y using a focal stack (LF photog raphy systems with C = 5 detectors obtain a focal stack of LFs consisting of S = 81 sub-aper ture images; aver aged PSNR v alues across three test reconstr ucted im- ages). and accuracy , compared to the existing soft-r efining INNs, [21]–[23], [28], [30] that correspond to BCD-Net [25] or Momentum-Net using no extrapolation , and ADMM-Net [20], [23], [41], and the existing hard-refining INN PDS- Net [50]. (Note that BCD-Net and Momentum-Net requir e slightly less computational complexity per INN iteration, compared to ADMM-Net and PDS-Net, r espectively , due to having fewer modules.) Fig. 5 shows that to r each the 24 HU RMSE value in sparse-view CT reconstruction, the proposed Momentum-Net decr eases MBIR time by 53 . 3 % and 62 . 5 %, compared to Momentum-Net without extrapola- tion and BCD-Net using three inner iterations, respectively . Fig. 7 shows that to reach the 32 dB PSNR value in LF reconstruction fr om a focal stack, the proposed Momentum- Net decreases MBIR time by 36 . 5 % and 61 . 5 %, compared to Momentum-Net without extrapolation and BCD-Net using three inner iterations, respectively . In addition, Figs. 5 and 7 show that using extrapolation, i.e., (Alg.1.2) with (8)– (10), improves the performance of Momentum-Net versus iterations. W e conjecture that the lar ger performance gap between soft-refiner Momentum-Net and hard-refiner PDS-Net, in Fig. 4(a) compared to Fig. 6(a), is because the LF problem needs stronger regularization, i.e., a smaller tuned factor χ ? in (20), than the CT problem. Similarly , comparing Fig. 4(b) to Fig. 6(b) shows that the LF problem has small perfor - mance gaps between BCD-Net and ADMM-Net. For both the applications, using dCNN refiners (19) instead of sCNN refiners (18) has a negligible effect on total 13 run time of Momentum-Net, because reconstruction time of MBIR modules (Alg.1.3) (in CPUs) dominates infer ence time of image refining modules (Alg.1.1) (in GPUs). Compare re- sults between Momentum-Net-sCNN and -dCNN in Figs. 5 & 7 and T ables A.1 & A.2. 4.4 Comparisons between different MBIR methods In sparse-view CT using 12 . 5 % of the full projection views, Fig. 8(b)–(e) and T able A.1(b)–(f) show that the proposed Momentum-Net achieves significantly better reconstruction quality compared to the conventional EP MBIR method and the state-of-the-art MBIR method within an unsupervised learning setup, MBIR model using a learned convolutional regularizer [24], [37]. In particular , Momentum-Net recov- ers both low- and high-contrast regions (e.g., soft tissues and bones, r espectively) more accurately than MBIR using a learned convolutional regularizer; see Fig. 8(c)–(e). In addition, when their shallow convolutional autoencoders need identical computational complexities, Momentum-Net achieves much faster MBIR compared to MBIR using a learned convolutional regularizer; see T able A.1(c)–(d). In LF photography using five focal sensors, regar dless of scene parameters and camera settings, Momentum-Net consistently achieves significantly mor e accurate image re- covery , compar ed to MBIR model using the state-of-the-art non-trained regularizer , 4D EP [47]. The effectiveness of Momentum-Net is more evident for a scene with less fine details. See Fig. 9(b)–(d) and T able A.2(b)–(d). Regardless of the scene distances from LF imaging systems, the re- constructed LFs by Momentum-Net significantly improve the depth estimation accuracy over those r econstructed by the state-of-the-art non-trained regularizer , 4D EP [47]. See Fig. 10(c)–(e) and T able A.3(c)–(e). In general, Momentum-Net needs mor e computations per iteration than EP MBIR, because its refining NNs use more and larger filters than the small finite-differ ence filters in EP MBIR, and EP MBIR algorithms can be often fur- ther accelerated by gradient approximations, e.g., order ed- subsets methods [77], [78]. 5 C O N C L U S I O N S Developing rapidly converging INNs is important, because 1) it leads to fast MBIR by reducing the computational com- plexity in calculating data-fit gradients or applying refining NNs, and 2) training INNs with many iterations r equires long training time or it is challenging when r efining NNs are fixed acr oss INN iterations. The proposed Momentum-Net framework is applicable for a wide range of inverse prob- lems, while achieving fast and convergent MBIR. T o achieve fast MBIR, Momentum-Net uses momentum in extrapola- tion modules, and noniterative MBIR modules at each itera- tion via majorizers. For sparse-view CT and LF photography using a focal stack, Momentum-Net achieves faster and more accurate MBIR compared to the existing soft-refining INNs, [21]–[23], [28], [30] that correspond to BCD-Net [25] or Momentum-Net using no extrapolation , and ADMM-Net [20], [23], [41], and the existing hard-refining INN PDS- Net [50]. When an application needs strong regularization strength, e.g., LF photography using limited detectors, using dCNN refiners with moderate depth significantly improves the MBIR accuracy of Momentum-Net compared to sCNNs, only marginally increasing total MBIR time. In addition, Momentum-Net guarantees convergence to a fixed-point for general differ entiable (non)convex MBIR functions (or data-fit terms) and convex feasible sets, under some mild conditions and two asymptotic conditions. The proposed regularization parameter selection scheme uses the “spectral spread” of majorization matrices, and is useful to consider data-fit variations across training/testing samples. There ar e a number of avenues for future work. First, we expect to further improve performances of Momentum-Net (e.g., MBIR time and accuracy) by using sharper majorizer designs. Second, we expect to further reduce MBIR time of Momentum-Net with the stochastic gradient perspective (e.g., or dered subset [77], [78]). On the regularization pa- rameter selection side, our future work is learning the factor χ in (20) from datasets while training refining NNs. R E F E R E N C E S [1] P . V incent, H. Larochelle, I. Lajoie, Y . Bengio, and P .-A. Manzagol, “Stacked denoising autoencoders: Learning useful repr esentations in a deep network with a local denoising criterion,” J. Mach. Learn. Res. , vol. 11, no. Dec, pp. 3371–3408, 2010. [2] J. Xie, L. Xu, and E. Chen, “Image denoising and inpainting with deep neural networks,” in Proc. NIPS , Lake T ahoe, NV , Dec. 2012, pp. 341–349. [3] X. Mao, C. Shen, and Y .-B. Y ang, “Image restoration using very deep convolutional encoder-decoder networks with symmetric skip connections,” in Proc. NIPS , Barcelona, Spain, Dec. 2016, pp. 2802– 2810. [4] K. Zhang, W . Zuo, Y . Chen, D. Meng, and L. Zhang, “Beyond a Gaussian denoiser: Residual learning of deep CNN for image denoising,” IEEE T rans. Image Process. , vol. 26, no. 7, pp. 3142–3155, Feb. 2017. [5] L. Xu, J. S. Ren, C. Liu, and J. Jia, “Deep convolutional neural net- work for image deconvolution,” in Proc. NIPS , Montreal, Canada, Dec. 2014, pp. 1790–1798. [6] J. Sun, W . Cao, Z. Xu, and J. Ponce, “Learning a convolutional neural network for non-uniform motion blur removal,” in Proc. IEEE CVPR , Boston, MA, Jun. 2015, pp. 769–777. [7] C. Dong, C. C. Loy , K. He, and X. T ang, “Image super -resolution using deep convolutional networks,” IEEE T rans. Pattern Anal. Mach. Intell. , vol. 38, no. 2, pp. 295–307, Feb. 2016. [8] J. Kim, K. J. Lee, and K. M. Lee, “Accurate image super-resolution using very deep convolutional networks,” in Proc. IEEE CVPR , Las V egas, NV , Jun. 2016. [9] G. Y ang, S. Y u, H. Dong, G. Slabaugh, P . L. Dragotti, X. Y e, F . Liu, S. Arridge, J. Keegan, Y . Guo et al. , “DAGAN: Deep de-aliasing generative adversarial networks for fast compressed sensing MRI reconstruction,” IEEE T rans. Image Process. , vol. 37, no. 6, pp. 1310– 1321, Jun. 2018. [10] T . M. Quan, T . Nguyen-Duc, and W . Jeong, “Compressed sensing MRI reconstruction using a generative adversarial network with a cyclic loss,” IEEE T rans. Med. Imag. , vol. 37, no. 6, pp. 1488–1497, June 2018. [11] H. Chen, Y . Zhang, M. K. Kalra, F . Lin, P . Liao, J. Zhou, and G. W ang, “Low-dose CT with a residual encoder-decoder convolu- tional neural network (RED-CNN),” IEEE T rans. Med. Imag. , vol. PP , no. 99, p. 0, Jun. 2017. [12] K. H. Jin, M. T . McCann, E. Froustey , and M. Unser , “Deep convolutional neural network for inverse problems in imaging,” IEEE T rans. Image Process. , vol. 26, no. 9, pp. 4509–4522, Sep. 2017. [13] J. Y e, Y . Han, and E. Cha, “Deep convolutional framelets: A general deep learning framework for inverse problems,” SIAM J. Imaging Sci. , vol. 11, no. 2, pp. 991–1048, Apr . 2018. [14] G. Wu, M. Zhao, L. W ang, Q. Dai, T . Chai, and Y . Liu, “Light field reconstruction using deep convolutional network on EPI,” in Proc. IEEE CVPR , Honolulu, HI, Jul. 2017, pp. 1638–1646. 14 (a) Ground truth (b) EP regularization (c) Learned convolutional reg. [24], [37] ( 4000 iter .) (d) Momentum-Net- sCNN ( N iter = 100 ) (e) Momentum-Net- dCNN ( N iter = 100 ) RMSE (HU) = 40 . 8 RMSE (HU) = 40 . 8 RMSE (HU) = 34 . 7 RMSE (HU) = 34 . 7 RMSE (HU) = 19 . 5 RMSE (HU) = 19 . 5 RMSE (HU) = 19 . 8 RMSE (HU) = 19 . 8 RMSE (HU) = 38 . 5 RMSE (HU) = 38 . 5 RMSE (HU) = 34 . 5 RMSE (HU) = 34 . 5 RMSE (HU) = 17 . 7 RMSE (HU) = 17 . 7 RMSE (HU) = 17 . 8 RMSE (HU) = 17 . 8 Fig. 8. Compar ison of reconstructed images from different MBIR methods in sparse-view CT (fan-beam geometry with 12 . 5 % projections vie ws and 10 5 incident photons; images outside zoom-in bo xes are magnified to better show diff erences; display windo w [800 , 1200] HU). See also Fig. A.2. (a) Ground truth at the (5 , 5)th angular coord. (b) Error maps of 4D EP reg. [47] (c) Error maps of Momentum-Net-sCNN (d) Error maps of Momentum-Net-dCNN PSNR (dB) = 29 . 9 (32 . 0) PSNR (dB) = 37 . 7 (35 . 8) PSNR (dB) = 38 . 2 (37 . 1) PSNR (dB) = 30 . 7 (28 . 1) PSNR (dB) = 33 . 9 (30 . 7) PSNR (dB) = 34 . 6 (32 . 0) PSNR (dB) = 27 . 3 (28 . 1) PSNR (dB) = 32 . 9 (30 . 9) PSNR (dB) = 33 . 6 (31 . 7) Fig. 9. Error map comparisons of reconstr ucted sub-aper ture images from diff erent MBIR methods in LF photograph y using a f ocal stac k (LF photograph y systems with C = 5 detectors capture a focal stack of LFs consisting of S = 81 sub-aper ture images; sub-aper ture images at the (5 , 5)th angular coordinate; the PSNR v alues in parenthesis were measured from reconstructed LFs). See also Fig. A.2. 15 (a) Ground truth depth maps (b) Estimated depth from ground truth LF (c) Estimated depth from LF reconstructed by 4D EP reg. [47] (d) Estimated depth from LF reconstructed by Momentum-Net-sCNN (e) Estimated depth from LF recon. by Momentum-Net-dCNN RMSE (m) = 4 . 7 × 10 − 2 RMSE (m) = 13 . 8 × 10 − 2 RMSE (m) = 8 . 0 × 10 − 2 RMSE (m) = 5 . 7 × 10 − 2 RMSE (m) = 30 . 5 × 10 − 2 RMSE (m) = 39 . 5 × 10 − 2 RMSE (m) = 34 . 6 × 10 − 2 RMSE (m) = 31 . 9 × 10 − 2 Ground truth does not exist. Fig. 10. Comparisons of estimated depths from LFs reconstr ucted by different MBIR methods in LF photograph using a focal stack (LF photog raphy systems with C = 5 detectors capture a focal stack of LFs consisting of S = 81 sub-aper ture images; SPO depth estimation [75] was applied to reconstructed LFs in Fig. 9; display window in meters). See also Fig. A.2. [15] M. Gupta, A. Jauhari, K. Kulkarni, S. Jayasuriya, A. C. Molnar , and P . K. T uraga, “Compressive light field reconstructions using deep learning,” in Proc. IEEE CVPR Workshops , Honolulu, HI, Jul. 2017, pp. 1277–1286. [16] I. Y . Chun, X. Zheng, Y . Long, and J. A. Fessler , “BCD-Net for low- dose CT reconstruction: Acceleration, convergence, and generaliza- tion,” in Proc. Med. Image Computing and Computer Assist. Interven. , Shenzhen, China, Oct. 2019, pp. 31–40. [17] X. Zheng, I. Y . Chun, Z. Li, Y . Long, and J. A. Fessler , “Sparse-view X-ray CT reconstr uction using ` 1 prior with learned transform,” submitted, Feb. 2019. [Online]. A vailable: http://arxiv .org/abs/1711.00905 [18] H. Lim, I. Y . Chun, Y . K. Dewaraja, and J. A. Fessler , “Improved low-count quantitative PET reconstruction with an iterative neural network,” IEEE T rans. Med. Imag. (to appear), May 2020. [Online]. A vailable: http://arxiv .org/abs/1906.02327 [19] S. Y e, Y . Long, and I. Y . Chun, “Momentum-net for low-dose CT image reconstruction,” arXiv preprint eess.IV:2002.12018 , Feb. 2020. [20] Y . Y ang, J. Sun, H. Li, and Z. Xu, “Deep ADMM-Net for compres- sive sensing MRI,” in Proc. NIPS , Long Beach, CA, Dec. 2016, pp. 10–18. [21] Y . Chen and T . Pock, “T rainable nonlinear reaction diffusion: A flexible framework for fast and effective image restoration,” IEEE T rans. Pattern Anal. Mach. Intell. , vol. 39, no. 6, pp. 1256–1272, Jun. 2017. [22] Y . Romano, M. Elad, and P . Milanfar , “The little engine that could: Regularization by denoising (RED),” SIAM J. Imaging Sci. , vol. 10, no. 4, pp. 1804–1844, Oct. 2017. [23] G. T . Buzzard, S. H. Chan, S. Sreehari, and C. A. Bouman, “Plug- and-play unplugged: Optimization fr ee r econstruction using con- sensus equilibrium,” SIAM J. Imaging Sci. , vol. 11, no. 3, pp. 2001– 2020, Sep. 2018. [24] I. Y . Chun and J. A. Fessler , “Convolutional analysis operator learning: Acceleration and convergence,” IEEE T rans. Image Pr ocess. , vol. 29, pp. 2108–2122, 2020. [25] ——, “Deep BCD-net using identical encoding-decoding CNN structures for iterative image recovery ,” in Proc. IEEE IVMSP Work- shop , Zagori, Greece, Jun. 2018, pp. 1–5. [26] M. Mardani, Q. Sun, D. Donoho, V . Papyan, H. Monajemi, S. V asanawala, and J. Pauly , “Neural proximal gradient descent for compressive imaging,” in Proc. NIPS , Montreal, Canada, Dec. 2018, pp. 9573–9583. [27] I. Y . Chun, H. Lim, Z. Huang, and J. A. Fessler , “Fast and con- vergent iterative signal recovery using trained convolutional neural networkss,” in Proc. Allerton Conf. on Commun., Control, and Comput. , Allerton, IL, Oct. 2018, pp. 155–159. [28] K. Hammernik, T . Klatzer , E. Kobler , M. P . Recht, D. K. Sodickson, T . Pock, and F . Knoll, “Learning a variational network for r econ- struction of accelerated MRI data,” Magn. Reson. Med. , vol. 79, no. 6, pp. 3055–3071, Nov . 2017. [29] M. Mardani, E. Gong, J. Y . Cheng, S. S. V asanawala, G. Zaharchuk, L. Xing, and J. M. Pauly , “Deep generative adversarial neural networks for compressive sensing (GANCS) MRI,” IEEE T rans. Med. Imag. , 2018. [30] H. K. Aggarwal, M. P . Mani, and M. Jacob, “MoDL: Model based deep learning architecture for inverse problems,” IEEE T rans. Med. Imag. , vol. 38, no. 2, pp. 394–405, Feb. 2019. [31] H. Gupta, K. H. Jin, H. Q. Nguyen, M. T . McCann, and M. Unser , “CNN-based projected gradient descent for consistent CT image reconstruction,” IEEE T rans. Med. Imag. , vol. 37, no. 6, pp. 1440– 1453, Jun. 2018. 16 [32] K. Kim, D. Wu, K. Gong, J. Dutta, J. H. Kim, Y . D. Son, H. K. Kim, G. El Fakhri, and Q. Li, “Penalized PET reconstruction using deep learning prior and local linear fitting,” IEEE T rans. Med. Imag. , vol. 37, no. 6, pp. 1478–1487, Jun. 2018. [33] H. Lim, J. A. Fessler , Y . K. Dewaraja, and I. Y . Chun, “Application of trained Deep BCD-Net to iterative low-count PET image recon- struction,” in Pr oc. IEEE NSS-MIC , Sydney , Australia, Nov . 2018, pp. 1–4. [34] H. Lim, I. Y . Chun, J. A. Fessler , and Y . K. Dewaraja, “Improved low count quantitative SPECT reconstruction with a trained deep learning based regularizer ,” J. Nuc. Med. (Abs. Book) , vol. 60, no. supp. 1, p. 42, May 2019. [35] I. Y . Chun and J. A. Fessler , “Convolutional dictionary learning: Acceleration and convergence,” IEEE T rans. Image Process. , vol. 27, no. 4, pp. 1697–1712, Apr . 2018. [36] I. Y . Chun, D. Hong, B. Adcock, and J. A. Fessler , “Convolutional analysis operator learning: Dependence on training data,” IEEE Signal Process. Lett. , vol. 26, no. 8, pp. 1137–1141, Jun. 2019. [Online]. A vailable: http://arxiv .org/abs/1902.08267 [37] I. Y . Chun and J. A. Fessler , “Convolutional analysis operator learning: Application to sparse-view CT,” in Proc. Asilomar Conf. on Signals, Syst., and Comput. , Pacific Grove, CA, Oct. 2018, pp. 1631– 1635. [38] C. Crockett, D. Hong, I. Y . Chun, and J. A. Fessler , “Incorporating handcrafted filters in convolutional analysis operator learning for ill-posed inverse pr oblems,” in Proc. IEEE W orkshop CAMSAP , Guadeloupe, W est Indies, Dec. 2019, pp. 316–320. [39] S. Sr eehari, S. V . V enkatakrishnan, B. W ohlberg, G. T . Buzzar d, L. F . Drummy , J. P . Simmons, and C. A. Bouman, “Plug-and-play priors for bright field electr on tomography and sparse interpolation,” IEEE T rans. Comput. Imag. , vol. 2, no. 4, pp. 408–423, Aug. 2016. [40] K. Zhang, W . Zuo, S. Gu, and L. Zhang, “Learning deep CNN de- noiser prior for image restoration,” in Proc. IEEE CVPR , Honolulu, HI, Jul. 2017, pp. 4681–4690. [41] S. H. Chan, X. W ang, and O. A. Elgendy , “Plug-and-play ADMM for image restoration: Fixed-point convergence and applications,” IEEE T rans. Comput. Imag. , vol. 3, no. 1, pp. 84–98, Nov . 2017. [42] S. Boyd, N. Parikh, E. Chu, B. Peleato, and J. Eckstein, “Distributed optimization and statistical learning via the alternating direction method of multipliers,” Found. & T rends in Machine Learning , vol. 3, no. 1, pp. 1–122, Jan. 2011. [43] E. T . Reehorst and P . Schniter , “Regularization by denoising: Clarifications and new interpretations,” IEEE T rans. Comput. Imag. , vol. 5, no. 1, pp. 52–67, Mar . 2019. [44] U. S. Kamilov , H. Mansour , and B. W ohlber g, “A plug-and-play priors approach for solving nonlinear imaging inverse problems,” IEEE Signal Process. Lett. , vol. 24, no. 12, pp. 1872–1876, Dec. 2017. [45] T . Miyato, T . Kataoka, M. Koyama, and Y . Y oshida, “Spectral normalization for generative adversarial networks,” in Proc. ICLR , V ancouver , Canada, Apr . 2018. [46] E. Ryu, J. Liu, S. W ang, X. Chen, Z. W ang, and W . Y in, “Plug-and- play methods provably converge with properly trained denoisers,” in Proc. ICML , Long Beach, CA, Jun. 2019, pp. 5546–5557. [47] M.-B. Lien, C.-H. Liu, I. Y . Chun, S. Ravishankar , H. Nien, M. Zhou, J. A. Fessler , Z. Zhong, and T . B. Norris, “Ranging and light field imaging with transparent photodetectors,” Nature Photonics , vol. 14, no. 3, pp. 143–148, Jan. 2020. [48] Y . Nesterov , “Gradient methods for minimizing composite func- tions,” Math. Program. , vol. 140, no. 1, pp. 125–161, Aug. 2013. [49] A. Beck and M. T eboulle, “A fast iterative shrinkage-thresholding algorithm for linear inverse problems,” SIAM J. Imaging Sci. , vol. 2, no. 1, pp. 183–202, Mar . 2009. [50] S. Ono, “Primal-dual plug-and-play image restoration,” IEEE Sig- nal Process. Lett. , vol. 24, no. 8, pp. 1108–1112, Aug. 2017. [51] A. Chambolle and T . Pock, “A first-or der primal-dual algorithm for convex problems with applications to imaging,” J. Math. Imag. V ision , vol. 40, no. 1, pp. 120–145, 2011. [52] K. Dabov , A. Foi, V . Katkovnik, and K. Egiazarian, “Image denois- ing by sparse 3-d transform-domain collaborative filtering,” IEEE T rans. Image Process. , vol. 16, no. 8, pp. 2080–2095, Jul. 2007. [53] Y . Xu and W . Y in, “A block coordinate descent method for regu- larized multiconvex optimization with applications to nonnegative tensor factorization and completion,” SIAM J. Imaging Sci. , vol. 6, no. 3, pp. 1758–1789, Sep. 2013. [54] ——, “A fast patch-dictionary method for whole image recovery ,” Inverse Probl. Imag. , vol. 10, no. 2, pp. 563–583, May 2016. [55] ——, “A globally convergent algorithm for nonconvex optimiza- tion based on block coordinate update,” J. Sci. Comput. , vol. 72, no. 2, pp. 700–734, Aug. 2017. [56] M. J. Muckley , D. C. Noll, and J. A. Fessler , “Fast, iterative subsampled spiral reconstruction via circulant majorizers,” in Proc. Int. Soc. Magn. Res. Med. , Singapore, May 2016, p. 521. [57] M. G. McGaffin and J. A. Fessler , “Algorithmic design of majorizers for lar ge-scale inverse problems,” ArXiv preprint stat.CO/1508.02958 , Oct. 2015. [58] I. Y . Chun and B. Adcock, “Compr essed sensing and parallel acquisition,” IEEE T rans. Inf. Theory , vol. 63, no. 7, pp. 1–23, May 2017. [Online]. A vailable: http://arxiv .org/abs/1601.06214 [59] S. Aja-Fern ´ andez, G. V egas-S ´ anchez-Ferrer o, and A. T rist ´ an-V ega, “Noise estimation in parallel MRI: GRAPP A and SENSE,” Magn. Reson. Imaging , vol. 32, no. 3, pp. 281–290, Apr . 2014. [60] R. T . Rockafellar , “Monotone operators and the proximal point algorithm,” SIAM J. Control Optm. , vol. 14, no. 5, pp. 877–898, Aug. 1976. [61] E. K. Ryu and S. Boyd, “Primer on monotone operator methods,” Appl. Comput. Math , vol. 15, no. 1, pp. 3–43, Jan. 2016. [62] J. Bolte, S. Sabach, and M. T eboulle, “Proximal alternating lin- earized minimization or nonconvex and nonsmooth problems,” Math. Program. , vol. 146, no. 1-2, pp. 459–494, Aug. 2014. [63] D. Gilton, G. Ongie, and R. W illett, “Neumann networks for linear inverse problems in imaging,” IEEE T rans. Comput. Imag. , vol. 6, pp. 328–343, Oct. 2019. [64] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proc. IEEE CVPR , Las V egas, NV , June 2016. [65] H. Li, Z. Xu, G. T aylor , C. Studer , and T . Goldstein, “V isualizing the loss landscape of neural nets,” in Proc. NIPS , Montreal, Canada, Dec. 2018, pp. 6389–6399. [66] Z. Li, I. Y . Chun, and Y . Long, “Image-domain material decom- position using an iterative neural network for dual-energy CT,” in Proc. IEEE ISBI , Iowa City , IA, Apr . 2009, pp. 651–655. [67] I. Y . Chun and T . T alavage, “Efficient compressed sensing statis- tical X-ray/CT reconstruction from fewer measurements,” in Proc. Intl. Mtg. on Fully 3D Image Recon. in Rad. and Nuc. Med , Lake T ahoe, CA, Jun. 2013, pp. 30–33. [68] C. J. Blocker , I. Y . Chun, and J. A. Fessler , “Low-rank plus sparse tensor models for light-field reconstruction from focal stack data,” in Proc. IEEE IVMSP Workshop , Zagori, Greece, Jun. 2018, pp. 1–5. [69] D. Zhang, Z. Xu, Z. Huang, A. R. Gutierrez, I. Y . Chun, C. J. Blocker , G. Cheng, Z. Liu, J. A. Fessler , Z. Zhong, and T . B. Norris, “Graphene-based transparent photodetector array for multiplane imaging,” in Proc. Conf. on Lasers and Electro-Optics , San Jose, CA, May 2019, p. SM4J.2. [70] K. Honauer , O. Johannsen, D. Kondermann, and B. Goldluecke, “A dataset and evaluation methodology for depth estimation on 4D light fields,” in Proc. ACCV , T aipei, T aiwan, Nov . 2016, pp. 19– 34. [71] W . P . Segars, M. Mahesh, T . J. Beck, E. C. Fr ey , and B. M. T sui, “Realistic CT simulation using the 4D XCA T phantom,” Med. Phys. , vol. 35, no. 8, pp. 3800–3808, Jul. 2008. [72] D. P . Kingma and J. L. Ba, “Adam: A method for stochastic optimization,” in Proc. ICLR 2015 , San Diego, CA, May 2015, pp. 1–15. [73] K. He, X. Zhang, S. Ren, and J. Sun, “Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification,” in Proc. IEEE ICCV , Santiago, Chile, Dec. 2015, pp. 1026–1034. [74] M. H. Kamal, B. Heshmat, R. Raskar , P . V andergheynst, and G. W etzstein, “T ensor low-rank and sparse light field photography ,” Comput. V is. Image Und. , vol. 145, pp. 172–181, Apr . 2016. [75] S. Zhang, H. Sheng, C. Li, J. Zhang, and Z. Xiong, “Robust depth estimation for light field via spinning parallelogram operator ,” Comput. V is. Image Und. , vol. 145, pp. 148–159, Apr . 2016. [76] J. A. Fessler , “Michigan image reconstruction toolbox (MIRT) for Matlab,” A vailable fr om http://web.eecs.umich.edu/ ∼ fessler, 2016. [77] H. M. Hudson and R. S. Larkin, “Accelerated image r econstruction using ordered subsets of projection data,” IEEE T rans. Med. Imag. , vol. 13, no. 4, pp. 601–609, Dec. 1994. [78] H. Erdogan and J. A. Fessler , “Ordered subsets algorithms for transmission tomography ,” Phys. Med. Biol. , vol. 44, no. 11, p. 2835, Jul. 1999. 17 Momentum-Net: Fast and conver gent iterative neural network for inverse pr oblems (Appendices) This supplementary material for [1] a) reviews the Block Proximal Extrapolated Gradient method using a Majorizer (BPEG-M) [2], [3], b) lists parameters of Momentum-Net, and summarizes selection guidelines or gives default values, c) compares the convergence properties between Momentum-Net and BCD-Net, and d) provides mathematical pr oofs or detailed descriptions to support several arguments in the main manuscript. W e use the prefix “A ” for the numbers in section, theorem, equation, figure, table, and footnote in the supplement. A . 1 B P E G - M : R E V I E W This section explains block multi-(non)convex optimization problems, and summarizes the state-of-the-art method for block multi-(non)convex optimization, BPEG-M [2], [3], along with its convergence guarantees. A.1.1 Bloc k multi-(non)con vex optimization In a block optimization problem, the variables of the underlying optimization problem are treated either as a single block or multiple disjoint blocks. In block multi-(non)convex optimization, we consider the following problem: min u F ( u 1 , . . . , u B ) , f ( u 1 , . . . , u B ) + B X b =1 r b ( u b ) (A.1) where variable u is decomposed into B blocks u 1 , . . . , u B ( { u b ∈ R n b : b = 1 , . . . , B } ), f is assumed to be (continuously) differ entiable, but functions { r b : b = 1 , . . . , B } are not necessarily differ entiable. The function r b can incorporate the constraint u b ∈ U b , by allowing r b ’s to be extended-valued, e.g., r b ( u b ) = ∞ if u b / ∈ U b , for b = 1 , . . . , B . It is standar d to assume that both f and { r b } ar e proper and closed, and the sets {U b } ar e closed. W e consider either that (A.1) has block-wise convexity (but (A.1) is jointly nonconvex in general) [2], [4] or that f , { r b } , or {U b } are not necessarily convex [3], [5]. Importantly , r b can include (non)convex and nonsmooth ` p (quasi-)norm, p ∈ [0 , 1] . The next section introduces our optimization framework that solves (A.1). The following sections review BPEG-M [2], [3], the state-of-the-art optimization framework for solving block multi- (non)convex problems, when used with suf ficiently sharp majorizers. BPEG-M uses block-wise extrapolation, majorization, and proximal mapping. By using a more general Lipschitz continuity (see Definition 1) for block-wise gradients, BPEG-M is particularly useful for rapidly calculating majorizers involved with large-scale problems, and successfully applied to some large-scale machine learning and computational imaging problems; see [2], [3], [6] and references therein. A.1.2 BPEG-M This section summarizes the BPEG-M framework. Using Definition 1 and Lemma 2, the proposed method, BPEG-M, is given as follows. T o solve (A.1), we minimize majorizers of F cyclically over each block u 1 , . . . , u B , while fixing the remaining blocks at their previously updated variables. Let u ( i +1) b be the value of u b after its i th update, and define f ( i +1) b ( u b ) , f u ( i +1) 1 , . . . , u ( i +1) b − 1 , u b , u ( i ) b +1 , . . . , u ( i ) B , for all b, i . At the b th block of the i th iteration, we apply Lemma 2 to functional f ( i +1) b ( u b ) with a M ( i +1) -Lipschitz continuous gradient at the extrapolated point ´ u ( i +1) b , and minimize a majorized function. In other words, we consider the updates u ( i +1) b = argmin u b h∇ f ( i +1) b ( ´ u ( i +1) b ) , u b − ´ u ( i +1) b i + 1 2 u b − ´ u ( i +1) b 2 f M ( i +1) b + r b ( u b ) = Pro x f M ( i +1) b r b ´ u ( i +1) b − f M ( i +1) b − 1 ∇ f ( i +1) b ( ´ u ( i +1) b ) | {z } extrapolated gradient step using a majorizer of f ( i +1) b , (A.2) where ´ u ( i +1) b = u ( i ) b + E ( i +1) b u ( i ) b − u ( i − 1) b , (A.3) 18 Algorithm A.1 BPEG-M [2], [3] Require: { u (0) b = u ( − 1) b : ∀ b } , { w ( i ) b ∈ [0 , 1] , ∀ b, i } , i = 0 while a stopping criterion is not satisfied do for b = 1 , . . . , B do Calculate f M ( i +1) b by (A.4), and E ( i +1) b to satisfy (A.5) or (A.6) ´ u ( i +1) b = u ( i ) b + E ( i +1) b u ( i ) b − u ( i − 1) b u ( i +1) b = Pro x f M ( i +1) b r b ´ u ( i +1) b − f M ( i +1) b − 1 ∇ f ( i +1) b ( ´ u ( i +1) b ) end for i = i + 1 end while the proximal operator is defined by (2), ∇ f ( i +1) b ( ´ u ( i +1) b ) is the block-partial gradient of f at ´ u ( i +1) b , a scaled majorization matrix is given by f M ( i +1) b = λ b · M ( i +1) b 0 , λ b ≥ 1 , (A.4) and M ( i +1) b ∈ R n b × n b is a symmetric positive definite majorization matrix of ∇ f ( i +1) b ( u b ) . In (A.3), the R n b × n b matrix E ( i +1) b 0 is an extrapolation matrix that accelerates convergence in solving block multi-convex problems [2]. W e design it to satisfy conditions (A.5) or (A.6) below . In (A.4), { λ b = 1 : ∀ b } and { λ b > 1 : ∀ b } , for block multi-convex and block multi-nonconvex problems, respectively . For some f ( i +1) b having sharp majorizers, we expect that extrapolation (A.3) has no benefits in accelerating convergence, and use { E ( i +1) b = 0 : ∀ i } . Other than the blocks having sharp majorizers, one can apply some increasing momentum coefficient formula [7], [8] to the corresponding extrapolation matrices. The choice in [2]–[4] accelerated BPEG-M for some machine learning and data science applications. Algorithm A.1 summarizes these updates. A.1.3 Con vergence results This section summarizes convergence results of Algorithm A.1 under the following assumptions: • Assumption S.1) In (A.1), F is proper and lower bounded in dom( F ) , { u : F ( u ) < ∞} . In addition, for block multi-convex (A.1), f is differ entiable and (A.1) has a Nash point or block-coordinate minimizer A.1 (see its definition in [4, (2.3)–(2.4)]); for block multi-nonconvex (A.1), f is continuously differ entiable, r b is lower semicontinuous A.2 , ∀ b , and (A.1) has a critical point u ? that satisfies 0 ∈ ∂ F ( u ? ) . • Assumption S.2) ∇ f ( i +1) b ( u b ) is M -Lipschitz continuous with respect to u b , i.e., ∇ f ( i +1) b ( u ) − ∇ f ( i +1) b ( v ) M ( i +1) b − 1 ≤ k u − v k M ( i +1) b , for u, v ∈ R n b , where M ( i +1) b is a bounded majorization matrix. • Assumption S.3) The extrapolation matrices E ( i +1) b 0 satisfy that for block multi-convex (A.1), E ( i +1) b T M ( i +1) b E ( i +1) b δ 2 · M ( i ) b ; (A.5) for block multi-nonconvex (A.1), E ( i +1) b T M ( i +1) b E ( i +1) b δ 2 ( λ b − 1) 2 4( λ b + 1) 2 · M ( i ) b , (A.6) with δ < 1 , ∀ b, i . Theorem A.1 ( Block multi-convex (A.1): A limit point is a Nash point [2]) . Under Assumptions S.1–S.3, let { u ( i +1) : i ≥ 0 } be the sequence generated by Algorithm A.1. Then any limit point of { u ( i +1) : i ≥ 0 } is a Nash point of (A.1). Theorem A.2 ( Block multi-nonconvex (A.1): A limit point is a critical point [3]) . Under Assumptions S.1–S.3, let { u ( i +1) : i ≥ 0 } be the sequence generated by Algorithm A.1. Then any limit point of { u ( i +1) : i ≥ 0 } is a critical point of (A.1). Remark A.3. Theorems A.1–A.2 imply that, if there exists a critical point for (A.1), i.e., 0 ∈ ∂ F ( u ? ) , then any limit point of { u ( i +1) : i ≥ 0 } is a critical point. One can further show global convergence under some conditions: if { u ( i +1) : i ≥ 0 } is bounded and the critical points are isolated, then { u ( i +1) : i ≥ 0 } converges to a critical point [2, Rem. 3.4], [4, Cor . 2.4]. A.1.4 Application of BPEG-M to solving bloc k multi-(non)con vex pr oblem (1) For update (3), we do not use extrapolation, i.e., (A.3), since the corresponding majorization matrices are sharp, so one obtains tight majorization bounds in Lemma 2. See, for example, [3, § V -B]. For updates (3) and (5), we r ewrite P K k =1 k h k ∗ x − ζ k k 2 2 as k x − P K k =1 flip( h ∗ k ) ∗ ζ k k 2 2 by using the TF condition in § 2.1 [3, § VI], [6]. A.1. Given a feasible set U , a point u ? ∈ dom( F ) ∪ U is a critical point (or stationary point) of F if the directional derivative d T ∇ F ( u ? ) ≥ 0 for any feasible direction d at u ? . If u ? is an interior point of U , then the condition is equivalent to 0 ∈ ∂ F ( u ? ) . A.2. F is lower semicontinuous at point u 0 if lim inf u → u 0 F ( u ) ≥ F ( u 0 ) . 19 A . 2 E M P I R I C A L M E A S U R E S R E L A T E D T O T H E C O N V E R G E N C E O F M O M E N T U M - N E T U S I N G S C N N R E FI N - E R S This section provides empirical measures related to Assumption 4 for Momentum-Net using single-hidden layer au- toencoders (18); see Fig. A.1 below . W e estimated the sequence { ( i ) : i = 2 , . . . , N lyr } in Definition 7, the sequence { ∆ ( i ) : i = 2 , . . . , N lyr } in Definition 8, and the Lipschitz constants { κ ( i ) : i = 1 , . . . , N lyr } of refining NNs {R θ ( i ) : ∀ i } , based on a hundr ed sets of randomly selected training samples related with the corresponding bounds of the measures, e.g., u and v in (11) are training input to R θ ( i +1) and R θ ( i ) in (Alg.1.1), respectively . (a) Sparse-view CT : Condition numbers of data-fit majorizers have mild variations. (a1) { ∆ ( i ) : i ≥ 2 } (a2) { ( i ) : i ≥ 2 } (a3) { κ ( i ) : i ≥ 1 } 20 40 60 80 100 Ite rati ons ( i ) 0 0.2 0.4 0.6 0.8 1 No rma lize d ∆ ( i ) 20 40 60 80 100 Ite rati ons ( i ) 0 0.2 0.4 0.6 0.8 1 No rma lize d ǫ ( i ) 20 40 60 80 100 Ite rati ons ( i ) 0.9 1 1.1 1.2 Lip schitz c onst ., κ ( i ) (b) LF photography using focal stack: Condition numbers of data-fit majorizers have strong variations. (b1) { ∆ ( i ) : i ≥ 2 } (b2) { ( i ) : i ≥ 2 } (b3) { κ ( i ) : i ≥ 1 } 20 40 60 80 100 Ite rati ons ( i ) 0 0.2 0.4 0.6 0.8 1 No rma lize d ∆ ( i ) 20 40 60 80 100 Ite rati ons ( i ) 0 0.2 0.4 0.6 0.8 1 No rma lize d ǫ ( i ) 20 40 60 80 100 Ite rati ons ( i ) 0.9 1 1.1 1.2 Lip schitz c onst ., κ ( i ) Fig. A.1. Empirical measures related to Assumption 4 for guaranteeing conv ergence of Momentum-Net using sCNN refiners (for details , see (18) and § 4.2.1), in diff erent applications. (a) The sparse-view CT reconstruction experiment used fan-beam geometr y with 12 . 5 % projections views . (b) The LF photograph y experiment used five detectors and reconstructed LFs consisting of 9 × 9 sub-aper ture images. (a1, b1) For both the applications, we obser v ed that ∆ ( i ) → 0 . This implies that the z ( i +1) -updates in (Alg.1.1) satisfy the asymptotic block-coordinate minimizer condition in Assumption 4. (Magenta dots denote the mean values and blac k ver tical error bars denote standard deviations.) (a2) Momentum-Net trained from training data-fits, where their major ization matrices ha ve mild condition n umber v ariations, shows that ( i ) → 0 . This implies that paired NNs ( R θ ( i +1) , R θ ( i ) ) in (Alg.1.1) are asymptotically nonexpansiv e. (b2) Momentum-Net trained from training training data-fits, where their majorization matrices have mild condition number v ar iations, sho ws that ( i ) becomes close to zero , but does not converge to z ero in one hundred iterations. (a3, b3) The NNs , R θ ( i +1) in (Alg.1.1), become nonexpansiv e, i.e., its Lipschitz constant κ ( i ) becomes less than 1 , as i increases. A . 3 P R O B A B I L I S T I C J U S T I FI C A T I O N F O R T H E A S Y M P TO T I C B L O C K - C O O R D I N AT E M I N I M I Z E R C O N D I T I O N I N A S S U M P T I O N 4 This section introduces a useful result for an asymptotic block-coordinate minimizer z ( i +1) : the following lemma provides a probabilistic bound for k x ( i ) − z ( i +1) k 2 2 in (12), given a subgaussian vector z ( i +1) − z ( i ) with independent and zero-mean entries. Lemma A.4 (Pr obabilistic bounds for k x ( i ) − z ( i +1) k 2 2 ) . Assume that z ( i +1) − z ( i ) is a zer o-mean subgaussian vector of which entries are independent and zero-mean subgaussian variables. Then, each bound in (12) holds with probability at least 1 − exp − k z ( i +1) − z ( i ) k 2 2 + ∆ ( i +1) 2 8 ρ · σ ( i +1) · kR θ ( i +1) ( x ( i ) ) − x ( i ) k 2 2 , where σ ( i +1) is a subgaussian parameter for z ( i +1) − z ( i ) , and a random variable is subgaussian with parameter σ if P {| · | ≥ t } ≤ 2 exp( − t 2 2 σ ) for t ≥ 0 . Proof. First, observe that x ( i ) − z ( i +1) 2 2 = x ( i ) − z ( i ) − ( z ( i +1) − z ( i ) ) 2 2 = x ( i ) − z ( i ) 2 2 + z ( i +1) − z ( i ) 2 2 − 2 h x ( i ) − z ( i ) , z ( i +1) − z ( i ) i 20 = x ( i ) − z ( i ) 2 2 + z ( i +1) − z ( i ) 2 2 − 2 h z ( i +1) − z ( i ) + ρ ( x ( i ) − R θ ( i +1) ( x ( i ) )) , z ( i +1) − z ( i ) i (A.7) = x ( i ) − z ( i ) 2 2 − z ( i +1) − z ( i ) 2 2 + 2 ρ hR θ ( i +1) ( x ( i ) ) − x ( i ) , z ( i +1) − z ( i ) i (A.8) where the inequality (A.7) holds by x ( i ) = ρx ( i ) − ρ R θ ( i +1) + z ( i +1) via (Alg.1.1). W e now obtain a pr obablistic bound for the third quantity in (A.8) via a concentration inequality . The concentration inequality on the sum of independent zero-mean subgaussian variables (e.g., [9, Thm. 7.27]) yields that for any t ( i +1) ≥ 0 P n hR θ ( i +1) ( x ( i ) ) − x ( i ) , z ( i +1) − z ( i ) i ≥ t ( i +1) o ≤ exp − ( t ( i +1) ) 2 2 σ ( i +1) kR θ ( i +1) ( x ( i ) ) − x ( i ) k 2 2 ! (A.9) where σ ( i +1) is given as in Lemma A.4. Applying the result (A.9) with t ( i +1) = 1 2 ρ ( k z ( i +1) − z ( i ) k 2 2 + ∆ ( i +1) ) to the bound (A.8) completes the proofs. Lemma A.4 implies that, given sufficiently lar ge ∆ ( i +1) , or sufficiently small σ ( i +1) (e.g., variance for a Gaussian random vector z ( i +1) − z ( i ) ) or kR θ ( i +1) ( x ( i ) ) − x ( i ) k 2 2 , bound (12) is satisfied with high probability , for each i . In particular , ∆ ( i +1) can be large for the first several iterations; if paired operators ( R θ ( i +1) , R θ ( i ) ) in (Alg.1.1) map their input images to similar output images (e.g., the trained NNs R θ ( i +1) and R θ ( i ) have good refining capabilities for x ( i ) and x ( i − 1) ), then σ ( i +1) is small; if the regularization parameter γ in (Alg.1.3) is sufficiently large, then kR θ ( i +1) ( x ( i ) ) − x ( i ) k 2 2 is small. A . 4 P R O O F S O F P R O P O S I T I O N 9 First, we show that P ∞ i =0 k x ( i +1) − x ( i ) k 2 2 < ∞ for convex and nonconvex F ( x ; y , z ( i +1) ) cases. • Convex F ( x ; y , z ( i +1) ) case: Using Assumption 2 and { f M ( i +1) = M ( i +1) : ∀ i } for the convex case via (7), we obtain the following results for any X : F x ( i ) ; y , z ( i ) − F x ( i +1) ; y , z ( i +1) + γ ∆ ( i +1) ≥ F x ( i ) ; y , z ( i +1) − F x ( i +1) ; y , z ( i +1) (A.10) ≥ 1 2 x ( i +1) − ´ x ( i +1) 2 M ( i +1) + ´ x ( i +1) − x ( i ) T M ( i +1) x ( i +1) − ´ x ( i +1) (A.11) = 1 2 x ( i +1) − x ( i ) 2 M ( i +1) − 1 2 E ( i +1) x ( i ) − x ( i − 1) 2 M ( i +1) (A.12) ≥ 1 2 x ( i +1) − x ( i ) 2 M ( i +1) − δ 2 2 x ( i ) − x ( i − 1) 2 M ( i ) (A.13) where the inequality (A.10) uses the condition (12) in Assumption 4, the inequality (A.11) is obtained by using the results in [2, Lem. S.1], the equality (A.12) uses the extrapolation formula (Alg.1.2) and the symmetry of M ( i +1) , the inequality (A.13) holds by Assumption 3. Summing the inequality of F ( x ( i ) ; y , z ( i ) ) − F ( x ( i +1) ; y , z ( i +1) ) + γ ∆ ( i +1) in (A.13) over i = 0 , . . . , N lyr − 1 , we obtain F x (0) ; y , z (0) − F x ( N lyr ) ; y , z ( N lyr ) + γ N lyr − 1 X i =0 ∆ ( i +1) ≥ N lyr − 1 X i =0 1 2 x ( i +1) − x ( i ) 2 M ( i +1) − δ 2 2 x ( i ) − x ( i − 1) 2 M ( i ) ≥ N lyr − 1 X i =0 1 − δ 2 2 x ( i +1) − x ( i ) 2 M ( i +1) ≥ N lyr − 1 X i =0 m F, min (1 − δ 2 ) 2 x ( i +1) − x ( i ) 2 2 (A.14) where the inequality (A.14) holds by Assumption 2. Due to the lower boundedness of F ( x ; y , z ) in Assumption 1 and the summability of { ∆ ( i +1) ≥ 0 : ∀ i } in Assumption 4, taking N lyr → ∞ gives ∞ X i =0 x ( i +1) − x ( i ) 2 2 < ∞ . (A.15) • Nonconvex F ( x ; y , z ( i +1) ) case: Using Assumption 2, we obtain the following results without assuming that F ( x ; y , z ( i +1) ) is convex: F x ( i ) ; y , z ( i ) − F x ( i +1) ; y , z ( i +1) + γ ∆ ( i +1) ≥ F x ( i ) ; y , z ( i +1) − F x ( i +1) ; y , z ( i +1) (A.16) 21 ≥ λ − 1 4 x ( i +1) − x ( i ) 2 M ( i +1) − ( λ + 1) 2 λ − 1 x ( i ) − ´ x ( i +1) b 2 M ( i +1) (A.17) = λ − 1 4 x ( i +1) − x ( i ) 2 M ( i +1) − ( λ + 1) 2 λ − 1 E ( i +1) x ( i ) − x ( i − 1) 2 M ( i +1) (A.18) ≥ λ − 1 4 x ( i +1) − x ( i ) 2 M ( i +1) − δ 2 x ( i ) − x ( i − 1) 2 M ( i ) (A.19) where the inequality (A.16) uses the condition (12) in Assumption 4, the inequality (A.17) use the results in [3, § S.3], the equality (A.18) holds by (Alg.1.2), the inequality (A.19) is obtained by Assumption 3. Summing the inequality of F ( x ( i ) ; y , z ( i ) ) − F ( x ( i +1) ; y , z ( i +1) ) + γ ∆ ( i +1) in (A.19) over i = 0 , . . . , N lyr − 1 , we obtain F x (0) ; y , z (0) − F x ( N lyr ) ; y , z ( N lyr ) + γ · N lyr − 1 X i =0 ∆ ( i +1) ≥ N lyr − 1 X i =0 λ − 1 4 x ( i +1) − x ( i ) 2 M ( i +1) − δ 2 x ( i ) − x ( i − 1) 2 M ( i ) ≥ N lyr − 1 X i =0 ( λ − 1)(1 − δ 2 ) 2 x ( i +1) − x ( i ) 2 M ( i +1) ≥ N lyr − 1 X i =0 m F, min ( λ − 1)(1 − δ 2 ) 2 x ( i +1) − x ( i ) 2 2 , where we follow the ar guments in obtaining (A.14) above. Again, using the lower boundedness of F ( x ; y , z ) and the summability of { ∆ ( i +1) ≥ 0 : ∀ i } , taking N lyr → ∞ gives the result (A.15) for nonconvex F ( x ; y , z ( i +1) ) . Second, we show that P ∞ i =0 k z ( i +1) − z ( i ) k 2 2 < ∞ . Observe z ( i +1) − z ( i ) 2 2 = (1 − ρ ) x ( i ) − x ( i − 1) + ρ R θ ( i +1) ( x ( i ) ) − R θ ( i ) ( x ( i − 1) ) 2 2 ≤ (1 − ρ ) x ( i ) − x ( i − 1) 2 2 + ρ R θ ( i +1) ( x ( i ) ) − R θ ( i ) ( x ( i − 1) ) 2 2 ≤ x ( i ) − x ( i − 1) 2 2 + ρ ( i +1) (A.20) where the first equality uses the image mapping formula in (Alg.1.1), the first inequality holds by applying Jensen’s in- equality to the (convex) squared ` 2 -norm, the second inequality is obtained by using the asymptotically non-expansiveness of the pair ed operators ( R θ ( i +1) , R θ ( i ) ) in Assumption 4. Summing the inequality of k z ( i +1) − z ( i ) k 2 2 in (A.20) over i = 0 , . . . , N lyr − 1 , we obtain N lyr − 1 X i =0 z ( i +1) − z ( i ) 2 2 ≤ N lyr − 2 X i =0 x ( i +1) − x ( i ) 2 2 + ρ N lyr − 1 X i =0 ( i +1) , (A.21) where we used x (0) = x ( − 1) as given in Algorithm 1. By taking N lyr → ∞ in (A.21), using r esult (A.15), and the summability of the sequence { ( i +1) : i ≥ 0 } , we obtain ∞ X i =0 z ( i +1) − z ( i ) 2 2 < ∞ . (A.22) Combining the results in (A.15) and (A.22) completes the proofs. A . 5 P R O O F S O F T H E O R E M 1 0 Let ¯ x be a limit point of { x ( i ) : i ≥ 0 } and { x ( i j ) } be the subsequence converging to ¯ x . Let ¯ z be a limit point of { z ( i ) : i ≥ 0 } and { z ( i j ) } be the subsequence converging to ¯ z . The closedness of X implies that ¯ x ∈ X . Using the results in Proposition 9, { x ( i j +1) } and { z ( i j +1) } also converge to ¯ x and ¯ z , respectively . T aking another subsequence if necessary , the subsequence { M ( i j +1) } converges to some ¯ M , since M ( i +1) is bounded by Assumption 2. The subsequences { θ ( i j +1) } converge to some ¯ θ , since x ( i j +1) → ¯ x , z ( i j +1) → ¯ z , and { θ ( i +1) } is bounded via Assumption 4. Next, we show that the convex proximal minimization (A.23) below is continuous in the sense that the output point x ( i j +1) continuously depends on the input points ´ x ( i j +1) and z ( i j +1) , and majorization matrix f M ( i j +1) : x ( i j +1) = argmin x ∈X h∇ F ( ´ x ( i j +1) ; y , z ( i j +1) ) , x − ´ x ( i j +1) i + 1 2 x − ´ x ( i j +1) 2 f M ( i j +1) (A.23) = Pro x f M ( i j +1) I X ´ x ( i j +1) − f M ( i j +1) − 1 ∇ F ( ´ x ( i j +1) ; y , z ( i j +1) ) . where the proximal mapping operator Prox f M ( i j +1) I X ( · ) is given as in (2). W e consider the two cases of majorization matrices { M ( i +1) } given in Theorem 10: 22 • For a sequence of diagonal majorization matrices, i.e., { M ( i +1) : i ≥ 0 } , one can obtain the continuity of the convex proximal minimization (A.23) with respect to ´ x ( i j +1) , z ( i j +1) , and f M ( i j +1) , by extending the existing results in [10, Thm. 2.26], [11] with the separability of (A.23) to element-wise optimization problems. • For a fixed general majorization matrix, i.e., M = M ( i +1) , ∀ i , we obtain that the convex proximal minimization (A.24) below is continuous with respect to the input points ´ x ( i j +1) and z ( i j +1) : x ( i j +1) = argmin x ∈X h∇ F ( ´ x ( i j +1) ; y , z ( i j +1) ) , x − ´ x ( i j +1) i + 1 2 x − ´ x ( i j +1) 2 f M (A.24) = Pro x f M I X ´ x ( i j +1) − f M − 1 ∇ F ( ´ x ( i j +1) ; y , z ( i j +1) ) = Id + f M − 1 ˆ ∂ I X − 1 ´ x ( i j +1) − f M − 1 ∇ F ( ´ x ( i j +1) ; y , z ( i j +1) ) (A.25) where ˆ ∂ f ( x ) is the subdifferential of f at x and Id denotes the identity operator , and the proximal mapping of I X relative to k · k f M is uniquely determined by the resolvent of the operator f M − 1 ˆ ∂ I X in (A.25). First, we obtain that the operator f M − 1 ˆ ∂ I X is monotone. For a convex extended-valued function f e : R N → R ∪ {∞} , observe that f M − 1 ˆ ∂ f e is a monotone operator: h f M − 1 ˆ ∂ f e ( u ) − f M − 1 ˆ ∂ f e ( v ) , u − v i = h f M − 1 f M | {z } = I ˆ ∂ f e ( f M ˜ u ) − f M − 1 f M | {z } = I ˆ ∂ f e ( f M ˜ v ) , f M ˜ u − f M ˜ v i ≥ 0 , ∀ u, v , (A.26) where the equality uses the variable change { u = f M ˜ u, v = f M ˜ v } , a chain rule of the subdifferential of a composition of a convex extended-valued function and an affine mapping [12, § 7], and the symmetry of f M , and the inequality holds because the subdif ferential of convex extended-valued function is a monotone operator [13, § 4.2]. Because characteristic function of a convex set is extended-valued function, the result in (A.26) implies that the operator f M − 1 ˆ ∂ I X is monotone. Second, note that the r esolvent of a monotone operator f M − 1 ˆ ∂ I X (with a parameter 1 ), i.e., (Id+ f M − 1 ˆ ∂ I X ) − 1 in (A.25), is nonexpansive [10, § 6] and thus continuous. W e now obtain that the convex proximal minimization (A.24) is continuous with r espect to the input points ´ x ( i j +1) and z ( i j +1) , because the pr oximal mapping operator (Id + f M − 1 ˆ ∂ I X ) − 1 in (A.25), the affine mapping f M − 1 , and ∇ F ( x ; y , z ) are continuous with respect to their input points. For the two cases above, using the fact that x ( i j +1) → ¯ x , ´ x ( i j +1) → ¯ x , z ( i j +1) → ¯ z , and M ( i j +1) → ¯ M (or ¯ M = M for the { M ( i +1) = M } case) as j → ∞ , (A.23) becomes ¯ x = argmin x ∈X h∇ F ( ¯ x ; y , ¯ z ) , x − ¯ x i + 1 2 k x − ¯ x k 2 ¯ M . (A.27) Thus, ¯ x satisfies the first-order optimality condition of min x ∈X F ( x ; y , ¯ z ) : h∇ F ( ¯ x ; y , ¯ z ) , x − ¯ x i ≥ 0 , for any x ∈ X , and this completes the proof of the first result. Next, note that the result in Proposition 9 imply A M ( i +1) R θ ( i +1) x ( i ) x ( i − 1) − x ( i ) x ( i − 1) 2 → 0 . (A.28) Additionally , note that a function A M ( i +1) R θ ( i +1) − I is continuous. T o see this, observe that the convex proximal mapping in (Alg.1.3) is continuous (see the obtained results above), and R θ ( i +1) is continuous (see Assumption 4). Combining (A.28), the convergence of { M ( i j +1) , R θ ( i j +1) } , and the continuity of A M ( i +1) R θ ( i +1) − I , we obtain [ ¯ x T , ¯ x T ] T = A ¯ M R ¯ θ ([ ¯ x T , ¯ x T ] T ) , and this completes the proofs of the second result. A . 6 P R O O F S O F C O R O L L A RY 1 1 T o prove the first result, we use proof by contradiction. Suppose that dist( x ( i ) , S ) 9 0 . Then there exists > 0 and a subsequence { x ( i j ) } such that dist( x ( i j ) , S ) ≥ , ∀ j . However , the boundedness assumption of { x ( i j ) } in Corollary 11 implies that there must exist a limit point ¯ x ∈ S via Theorem 10. This is a contradiction, and gives the first result (via the result in Pr oposition 9). Under the isolation point assumption in Cor ollary 11, using the obtained r esults, k x ( i +1) − x ( i ) k 2 → 0 (via Proposition 9) and dist( x ( i +1) , S ) → 0 , and the following the proofs in [4, Cor . 2.4], we obtain the second result. 23 A . 7 M O M E N T U M - N E T V S . B C D - N E T This section compares the convergence properties of Momentum-Net (Algorithm 1) and BCD-Net (Algorithm 2). W e first show that for convex f ( x ; y ) and X , the sequence of reconstr ucted images generated by BCD-Net converges: Proposition A.5 (Sequence convergence) . In Algorithm 2, let f ( x ; y ) be convex and subdifferentiable, and X be convex. Assume that the paired operators ( R θ ( i +1) , R θ ( i ) ) ar e asymptotically contractive, i.e., kR θ ( i +1) ( u ) − R θ ( i ) ( v ) k 2 < k u − v k 2 + ( i +1) , with P ∞ i =0 ( i +1) < ∞ and { ( i + i ) ∈ [0 , ∞ ) : ∀ i } , ∀ u, v , i . Then, the sequence { x ( i +1) : i ≥ 0 } generated by Algorithm 2 is convergent. Proof. W e rewrite the updates in Algorithm 2 as follows: x ( i +1) = argmin x ∈X f ( x ; y ) + γ 2 x − R θ ( i +1) ( x ( i ) ) 2 2 = Pro x γ I f + I X R θ ( i +1) ( x ( i ) ) = Id + γ − 1 ˆ ∂ ( f ( x ; y ) + I X ) − 1 R θ ( i +1) ( x ( i ) ) =: A ( i +1) ( x ( i ) ) . W e first show that the paired operators {A ( i +1) , A ( i ) } is asymptotically contractive: A ( i +1) ( u ) − A ( i ) ( v ) 2 = Id + γ − 1 ˆ ∂ ( f ( x ; y ) + I X ) − 1 R θ ( i +1) ( u ) − Id + γ − 1 ˆ ∂ ( f ( x ; y ) + I X ) − 1 R θ ( i ) ( v ) 2 ≤ kR θ ( i +1) ( u ) − R θ ( i ) ( v ) k 2 (A.29) ≤ L 0 k u − v k 2 + ( i +1) k u − v k 2 , (A.30) ∀ u, v , where the inequality (A.29) holds because the subdifferential of the convex extended-valued function f ( x ; y ) + I X (the characteristic function of a convex set X , I X , is convex, and the sum of the two convex functions, f ( x ; y ) + I X , is convex) is a monotone operator [13, § 4.2], and the resolvent of a monotone relation with a positive parameter , i.e., (Id + γ − 1 ˆ ∂ ( f ( x ; y ) + I X )) − 1 with γ − 1 > 0 , is nonexpansive [13, § 6], and the inequality (A.30) holds by L 0 < 1 via the contractiveness of the paired operators ( R θ ( i +1) , R θ ( i ) ) , ∀ i . Note that the inequality (A.29) does not hold for nonconvex f ( x ; y ) and/or X . Considering that L 0 < 1 , we show that the sequence { x ( i +1) : i ≥ 0 } is Cauchy sequence: x ( i + l ) − x ( i ) 2 = ( x ( i + l ) − x ( i + l − 1) ) + . . . + ( x ( i +1) − x ( i ) ) 2 ≤ x ( i + l ) − x ( i + l − 1) + . . . + x ( i +1) − x ( i ) 2 ≤ L 0 l − 1 + . . . + 1 x ( i +1) − x ( i ) 2 + ( i + l ) + . . . + ( i +1) ≤ 1 1 − L 0 x ( i +1) − x ( i ) 2 + l X i 0 =1 ( i + i 0 ) where the second inequality uses the result in (A.30). Since the sequence { x ( i +1) : i ≥ 0 } is Cauchy sequence, { x ( i +1) : i ≥ 0 } is convergent, and this completes the proofs. In terms of guaranteeing convergence, BCD-Net has three theoretical or practical limitations compared to Momentum- Net: • Dif ferent from Momentum-Net, BCD-Net assumes the asymptotic contractive condition for the paired operators {R θ ( i +1) , R θ ( i ) } . When image mapping operators in (Alg.2.1) are identical across iterations, i.e., {R θ = R θ ( i +1) : i ≥ 0 } , then R θ is assumed to be contractive. On the other hand, a mapping operator (identical across iterations) of Momentum- Net only needs to be nonexpansive. Note, however , that when f ( x ; y ) = 1 2 k y − Ax k 2 W with A H W A 0 (e.g., Example 5), BCD-Net can guarantee the sequence convergence with the asymptotically nonexpansive paired operators ( R θ ( i +1) , R θ ( i ) ) (see Definition 7) [14]. • When one applies an iterative solver to (Alg.2.2), there always exist some numerical errors and these obstruct the sequence convergence guarantee in Proposition A.5. T o guarantee sufficiently small numerical errors from iterative methods solving (Alg.2.2) (so that one can find a critical point solution for the MBIR problem (Alg.2.2)), one needs to use sufficiently many inner iterations that can substantially slow down entire MBIR. • BCD-Net does not guarantee the sequence convergence for nonconvex data-fit f ( x ; y ) , whereas Momentum-Net guarantees convergence to a fixed-point for both convex f ( x ; y ) and nonconvex f ( x ; y ) . 24 A . 8 F O R T H E S C N N A R C H I T E C T U R E ( 1 8 ) , C O N N E C T I O N B E T W E E N C O N VO L U T I O N A L T R A I N I N G L O S S ( P 2 ) A N D I T S PA T C H - B A S E D T R A I N I N G L O S S This section shows that given the sCNN architecture (18), the convolutional training loss in (P2) has three advantages over the patch-based training loss in [14], [15] that may use all the extracted overlapping patches of size R : • The corresponding patch-based loss does not model the patch aggregation process that is inherently modeled in (18). • It is an upper bound of the convolutional loss (P2). • It requires about R times more memory than (P2). W e prove the benefits of (P2) using the following lemma. Lemma A.6. The loss function (P2) for training the residual convolutional autoencoder in (18) is bounded by the patch-based loss function: 1 2 L S X s =1 ˆ x ( i ) s − 1 R K X k =1 d k ~ T α k ( e k ~ x ( i ) s ) 2 2 ≤ 1 2 LR S X s =1 b X ( i ) s − D T ˜ α ( E X ( i ) s ) 2 F , (A.31) where the residual is defined by ˆ x ( i ) s , x s − x ( i ) s , { x s , x ( i ) s } are given as in (P2), b X s ∈ R R × V s and X s ∈ R R × V s are the l th training data matrices whose columns are V s vectorized patches extracted fr om the images ˆ x s and x s (with the circulant boundary condition and the “stride” parameter 1 ), r espectively, D , [ d 1 , . . . , d K ] ∈ C R × K is a decoding filter matrix, and E , [ e ∗ 1 , . . . , e ∗ K ] H ∈ C K × R is an encoding filter matrix. Here, the definition of soft-thresholding operator in (6) is generalized by ( T ˜ α ( u )) k , u k − α k · sign( u k ) , | u k | > α k , 0 , otherwise , (A.32) for K = 1 , . . . , K , where ˜ α = [ α 1 , . . . , α K ] T . See other related notations in (18). Proof. First, we have the following reformulation [3, § S.1]: e 1 ∗ u . . . e K ∗ u = P 0 E P 1 . . . E P N | {z } , e E u, ∀ u, (A.33) where P 0 ∈ C K N × K N is a permutation matrix, E is defined in Lemma (A.6), and P n ∈ C R × N is the n th patch extraction operator for n = 1 , . . . , N . Considering that 1 R P K k =1 flip ( e ∗ k ) ~ ( e k ~ u ) = e E H e E u via the definition of e E in (A.33) (see also the reformulation technique in [3, § S.1]), we obtain the following reformulation result: 1 R K X k =1 flip ( e ∗ k ) ~ T α k ( e k ~ x ( i ) s ) = 1 R N X n =1 P H n E H T e α E P n x ( i ) s (A.34) where the soft-thresholding operators {T α k ( · ) : ∀ k } and T ˜ α ( · ) are defined in (A.32) and we use the permutation invariance of the thresholding operator T α ( · ) , i.e., T α ( P ( · )) = P · T α ( · ) for any α . Finally , we obtain the result in (A.31) as follows: 1 2 L S X s =1 ˆ x ( i ) s − 1 R K X k =1 d k ~ T α k ( e k ~ x ( i ) s ) 2 2 = 1 2 L S X s =1 ˆ x ( i ) s − 1 R N X n =1 P H n D T ˜ α E P n x ( i ) s 2 2 (A.35) = 1 2 L S X s =1 1 R N X n =1 P H n P n ˆ x ( i ) s − 1 R N X n =1 P H n D T ˜ α E P n x ( i ) s 2 2 (A.36) = 1 2 LR 2 S X s =1 N X n =1 P H n ˆ x ( i ) l,n − D T ˜ α E x ( i ) l,n 2 2 ≤ 1 2 LR S X s =1 N X n =1 ˆ x ( i ) l,n − D T ˜ α E x ( i ) l,n 2 2 (A.37) = 1 2 LR S X s =1 b X ( i ) s − D T ˜ α E X ( i ) s 2 F , where D is defined in Lemma A.6, { ˆ x ( i ) l,n = P n ˆ x ( i ) s ∈ C R , x ( i ) l,n = P n x ( i ) s ∈ C R : n = 1 , . . . , N } is a set of extracted patches, the training matrices { b X ( i ) s , X ( i ) s } are defined by b X ( i ) s , [ ˆ x ( i ) l,n , . . . , ˆ x ( i ) l,N ] and X ( i ) s , [ x ( i ) l, 1 , . . . , x ( i ) l,N ] . Here, the equality (A.35) uses the result in (A.34), the equality (A.36) holds by P N n =1 P H n P n = R · I (for the circulant boundary condition in Lemma A.6), and the inequality (A.37) holds by e P e P H R · I with e P , [ P H 1 · · · P H N ] H . 25 Lemma A.6 r eveals that when the patch-based training appr oach extract all the R -size overlapping patches, 1) the corresponding patch-based loss is an upper bound of the convolutional loss (P2); 2) it requir es about R -times larger memory than (P2) because V s ≈ RN s for x ∈ R N s and the boundary condition described in Lemma A.6, ∀ l ; and 3) it misses modeling the patch aggregation process that is inherently modeled in (18) – see that the patch aggregation operator P N n =1 P H n ( · ) n is removed in the inequality (A.37) in the pr oof of Lemma A.6. In addition, dif ferent from the patch-based training approach [14], [15], i.e., training with the function on the right-hand side in (A.31), one can use different sizes of filters { e k , d k : ∀ k } in the convolutional training loss, i.e., the function on the left-hand side in (A.31). A . 9 D E T A I L S O F E X P E R I M E N T A L S E T U P A.9.1 Majorization matrix designs f or quadratic data-fit For (real-valued) quadratic data-fit f ( x ; y ) in the form of 1 2 k y − Ax k 2 W , if a majorization matrix M exists such that A H W A M , it is straightforwar d to verify that the gradient of quadratic data-fit f ( x ; y ) satisfies the M -Lipchitz continuity in Definition 1, i.e., k∇ f ( u ; y ) − ∇ f ( v ; y ) k M − 1 = k A H W Au − A H W Av k M − 1 ≤ k u − v k 2 M , ∀ u, v ∈ R N . because the assumption A T W A M ⇔ M − 1 / 2 A T W AM − 1 / 2 I implies that the eigenspectrum of M − 1 / 2 A T W AM − 1 / 2 lies in the interval [0 , 1] , and gives the following result: M − 1 / 2 A T W AM − 1 / 2 2 I ⇔ ( A T W A ) M − 1 ( A T W A ) M . Next, we review a useful lemma in designing majorization matrices for a wide class of quadratic data-fit f ( x ; y ) : Lemma A.7 ( [2, Lem. S.3]) . For a (possibly complex-valued) matrix A and a diagonal matrix W with non-negative entries, A H W A diag( | A H | W | A | 1) , where | A | denotes the matrix consisting of the absolute values of the elements of A . A.9.2 P arameters for MBIR optimization models: Spar se-view CT reconstruction For MBIR model using EP regularization, we combined a EP regularizer P N n =1 P n 0 ∈N n ι n ι n 0 ϕ ( x n − x n 0 ) and the data-fit f ( x ; y ) in § 4.1.1, wher e N n is the set of indices of the neighbor hood, ι n and ι n 0 are parameters that encourage uniform noise [16], and ϕ ( · ) is the Lange penalty function, i.e., ϕ ( t ) = δ 2 ( | t/δ | − log(1 + | t/δ | )) , with δ = 10 in HU. W e chose the regularization parameter (e.g., γ in (P0)) as 2 15 . 5 . W e ran the relaxed linearized augmented Lagrangian method [17] with 100 iterations and 12 order ed-subsets, and initialized the EP MBIR algorithms with a conventional FBP method using a Hanning window . For MBIR model using a learned convolutional regularizer [6, (P2)], we trained convolutional regularizer with filters of { h k ∈ R R : R = K = 7 2 } via CAOL [3] in an unsupervised training manner; see training details in [3]. The regularization parameters (e.g., γ in (1)) wer e selected by applying the “spectral spread” based selection scheme in § 3.2 with the tuned factor χ ? = 167 . 64 . W e selected the spatial-strength-contr olling hard-thr esholding parameter (i.e., α 0 in [6, (P2)]) as follows: for T est samples #1 – 2 , we chose it is as 10 − 10 and 6 − 11 , respectively . W e initialized the MBIR model using a learned regularizer with the EP MBIR results obtained above. W e terminated the iterations if the relative error stopping criterion (e.g., [2, (44)]) is met before reaching the maximum number of iterations. W e set the tolerance value as 10 − 13 and the maximum number of iterations to 4 × 10 3 . A.9.3 P arameters for MBIR optimization models: LF photograph y using a focal stac k For MBIR model using 4D EP regularization [18], we combined a 4D EP r egularizer P N n =1 P n 0 ∈N n ϕ ( x n − x n 0 ) and the data- fit f ( x ; y ) in § 4.1.2, where N n is the set of indices of the 4D neighborhood, and ϕ ( · ) is the hyperbola penalty function, i.e., ϕ ( t ) = δ 2 ( p 1 + | t/δ | 2 − 1) . W e selected the hyperbola function parameter δ and regularization parameter (e.g., γ in (P0)) as follows: for T est samples #1 – 3 , we chose them as { δ = 10 − 4 , γ = 10 3 } , { δ = 10 − 1 , γ = 10 7 } , and { δ = 10 − 1 , γ = 5 × 10 3 } , respectively . W e ran the conjugate gradient method with 100 iterations, and initialized the 4D EP MBIR algorithms with A T y rescaled in the interval [0 , 1] . A.9.4 Reconstruction accuracy and depth estimation accurac y of different MBIR methods T ables A.1–A.3 below provide reconstruction accuracy numerics of differ ent MBIR methods in sparse-view CT reconstruc- tion and LF photography using a focal stack, and reports the SPO depth estimation [19] accuracy numerics on r econstructed LFs from different MBIR methods. A.9.5 Reconstructed images and estimated depths with noniterative analytical methods This section provides reconstructed images by an analytical back-projection method in sparse-view CT reconstruction and LF photography using a focal stack (see the first two columns in Fig. A.2), and estimated depths fr om reconstructed LFs via the SPO depth estimation method [19] (see the third column in Fig. A.2(c)). Results in Fig. A.2 below are supplementary to Fig. 8, Fig. 9, and Fig. 10, and the first two columns visualize initial input images to INN methods. 26 T ABLE A.1 RMSE (HU) of different CT MBIR methods (fan-beam geometry with 12 . 5% projections vie ws and 10 5 incident photons) (a) FBP (b) EP reg. (c) Learned convolutional reg. [3], [6] (d) Momentum-Net- sCNN (e) Momentum-Net- sCNN w/ larger width (f) Momentum-Net- dCNN T est #1 82.8 40.8 35.2 19.9 19.5 19.8 T est #2 74.9 38.5 34.5 18.4 17.7 17.8 (c)’s convolutional regularizer uses { R = K = 7 2 } (d)’s refining sCNNs are in the form of residual single-hidden layer convolutional autoencoder (18) with { R = K = 7 2 } . (e)’s refining sCNNs are in the form of residual single-hidden layer convolutional autoencoder (18) with { R = 7 2 , K = 9 2 } . This setup gives results in Fig. 8(d), as described in § 4.2.1. (f)’s refining dCNNs are in the form of residual multi-hidden layer CNN (19) with { L = 4 , R = 3 2 , K = 64 } . T ABLE A.2 PSNR (dB) of different LF MBIR methods (LF photograph y systems with C = 5 detectors obtain a f ocal stack of LFs consisting of S = 81 sub-aper ture images) (a) A T y (b) 4D EP reg. [18] (c) Momentum-Net-sCNN (d) Momentum-Net-dCNN T est #1 16.4 32.0 35.8 37.1 T est #2 21.1 28.1 30.7 32.0 T est #3 21.6 28.1 30.9 31.7 (c)’s refining sCNNs are in the form of residual single-hidden layer convolutional autoencoder with { R = 5 2 , K = 32 } . (d)’s refining dCNNs are in the form of residual multi-hidden layer CNN (19) with { L = 6 , R = 3 2 , K = 16 } . Momentum-Nets use refining CNNs in an epipolar-domain; see details in § 4.2.1. T ABLE A.3 RMSE (in 10 − 2 , m) of estimated depth from reconstructed LFs with different LF MBIR methods (LF photograph y systems with C = 5 detectors obtain a f ocal stack of LFs consisting of S = 81 sub-aper ture images) (a) Ground truth LF (b) Reconstructed LF by A T y (c) Reconstructed LF by 4D EP reg. [18] (d) Reconstructed LF by Momentum-Net-sCNN (e) Reconstructed LF by Momentum-Net-dCNN T est #1 4.7 41.0 13.8 8.0 5.7 T est #2 30.5 117.6 39.5 34.6 31.9 T est #3 n/a † n/a † n/a † n/a † n/a † SPO depth estimation [19] was applied to reconstructed LFs. (d)’s refining sCNNs are in the form of residual single-hidden layer convolutional autoencoder with { R = 5 2 , K = 32 } . (e)’s refining dCNNs are in the form of residual multi-hidden layer CNN (19) with { L = 6 , R = 3 2 , K = 16 } . Momentum-Nets use refining CNNs in an epipolar-domain; see details in § 4.2.1. † The ground truth depth map for T est sample #3 does not exist in the LF dataset [20]. A . 1 0 H OW TO C H O O S E PA R A M E T E R S O F I M A G E R E FI N I N G M O D U L E S I N S O F T - R E FI N I N G I N N S ? In soft-refining INNs using iterative-wise refining NNs, one does not need to greatly increase parameter dimensions of refining NNs [14], [21]. The natural question then arises, “How one can choose between sCNN (18) and dCNN (19) r efiners, and select their parameters ( R , K , and L )?” The first answer to this question depends on some understanding of data- fit f ( x ; y ) in MBIR pr oblem (P1), e.g., the r egularization strength γ and the condition number variations acr oss training data-fit majorizers. (An additional criteria could be general understandings between sample size/diversity and parameter dimension of NNs.) For example, the sparse-view CT system in § 4.1.1 needs moderate regularization strength ( χ ? = 167 . 64 ) and the majorization matrices of its training data-fits have mild condition number variations (the standar d deviation is 1 . 1 ). training data-fits have mild parameter variations across samples. Comparing results between Momentum-Net-sCNN and -dCNN in Fig. 5 and T able A.1 demonstrates that sCNN (18) seems suffice. T able A.1(d)–(e) shows that one can further improve the refining accuracy of sCNN (18) by increasing its width, i.e., K . The LF photography system using a limited focal stack in § 4.1.2 needs a large γ value ( χ ? = 1 . 5 ), and the majorization matrices of its training data-fits have large condition number variations (the standard deviation is 2245 . 5 ). Comparing results between Momentum-Net-sCNN and -dCNN in Fig. 7 and T able A.2 demonstrates that dCNN (19) yields higher PSNR than sCNN (18). For dCNN (19), we observed increasing its depth, i.e., L , up to a certain number is more effective than increasing its width, i.e., K , as briefly discussed in § 4.2.1. For choosing the r elaxation parameter ρ in (Alg.1.1), we also suggest considering the r egularization strength in (Alg.1.3). For an application that needs moderate regularization strength, e.g., sparse-view CT in § 4.1.1, we suggest setting ρ to 0 . 5 so as to mix information between input and output of refining NNs, rather than 1 − ε that does not mix input and output. For an application that needs strong regularization, e.g., LF photography using a limited focal stack in § 4.1.2, we suggest using ρ = 1 − ε than ρ = 0 . 5 . Results in the next section validate this suggestion. 27 Fig. 8: FBP RMSE (HU) = 82 . 8 RMSE (HU) = 82 . 8 RMSE (HU) = 74 . 9 RMSE (HU) = 7 4 . 9 Fig. 9: Error maps of A T y PSNR (dB) = 16 . 5 (16 . 4) PSNR (dB) = 22 . 6 (21 . 1) PSNR (dB) = 23 . 4 (21 . 6) Fig. 10: Estimated depth from LF recon. by A T y RMSE (m) = 41 . 0 × 10 − 2 RMSE (m) = 117 . 6 × 10 − 2 n/a Fig. A.2. Reconstructed images from analytical back-projection methods. W e used such results in the first two columns to initialize INN methods. A.10.1 P erformance of Momentum-Net with different relaxation parameter s ρ in (Alg.1.1) Fig. A.3 below compares the performances of Momentum-Net-sCNN with dif ferent ρ values. The r esults in Fig. A.3 support the ρ selection guideline in § 4.2.3. One can maximize the MBIR accuracy of Momentum-Net by properly selecting ρ . Note that ρ ∈ (0 , 1) contr ols strength of infer ence from refining NNs in (Alg.1.1), but does not affect the conver gence guarantee of Momentum-Net. Fig. A.3 illustrates that Momentum-Net appears to converge regar dless of ρ values. (a) Sparse-view CT (b) Light-field photography using focal stack 0 20 40 60 80 100 Ite rati ons (i) 20 30 40 50 RM SE (H U) (18) R = K = 49, ρ = 1 − ǫ (18) R = 49 , K = 81, ρ = 1 − ǫ (18) R = K = 49, ρ = 0 . 5 (18) R = 49 , K = 81, ρ = 0 . 5 0 20 40 60 80 100 Ite rati ons (i) 26 28 30 32 PS NR (d B) (18) R = 25 , K = 32, ρ = 1 − ǫ (18) R = 25 , K = 32, ρ = 0 . 5 Fig. A.3. Convergence behavior of Momentum-Net-sCNN with different relaxation parameters, ρ = 0 . 5 and ρ = 1 − ε . For both applications (see their imaging setups in § 4.1), PyT orch ver . 0.3.1 was used. A . 1 1 P A R A M E T E R S O F M O M E N T U M - N E T T able A.4 below lists parameters of Momentum-Net, and summarizes selection guidelines or default values. Similar to BCD- Net/ADMM-Net, the main tuning jobs to maximize the performance of Momentum-Net include selecting architectures of refining NNs {R θ ( i ) : ∀ i } in (Alg.1.1), and choosing a regularization parameter γ in (Alg.1.3) by tuning χ in § 3.2. One can simplify the tuning process by using the selection guidelines in § A.10 for selecting architectures of {R θ ( i ) : ∀ i } , and training 28 χ in § 3.2. Note that one designs majorization matrices { M ( i ) : ∀ i } rather than tuning them: majorization matrices can be analytically designed, e.g., Lemma A.7 as used in § 4.2.1; one can algorithmically design them [22]. T ighter majorization matrices are expected to further accelerate the convergence of Momentum-Net [2], [3]. T ABLE A.4 Guidelines for choosing par ameters of Momentum-Net Param. Module Guidelines or default values {R θ ( i ) : ∀ i } (Alg.1.1) T rainable by § 3.1. For selecting their architectur e/param., see guideline § A.10. ρ ∈ (0 , 1) (Alg.1.1) Use regularization strength γ ; see guideline in § A.10. δ < 1 in (8)–(9) (Alg.1.2) 1 − ε { M ( i ) : ∀ i } (Alg.1.3) Designed off-line. For large-scale inverse problems with quadratic data-fit, use Lemma A.7. λ ≥ 1 in (7) (Alg.1.3) For convex F ( x ; y , z ( i +1) ) , λ = 1 ; for nonconvex F ( x ; y , z ( i +1) ) , λ = 1 + ε . γ > 0 (Alg.1.3) Chosen by tuning/training χ in § 3.2 All INN methods also must select a number of INN iterations, N iter . One could determine it by using the convergence behavior of iteration-wise refiners in Fig. 2. R E F E R E N C E S [1] I. Y . Chun, Z. Huang, H. Lim, and J. A. Fessler , “Momentum-Net: Fast and convergent iterative neural network for inverse problems,” submitted, Jul. 2019. [2] I. Y . Chun and J. A. Fessler , “Convolutional dictionary learning: Acceleration and convergence,” IEEE T rans. Image Process. , vol. 27, no. 4, pp. 1697–1712, Apr . 2018. [3] ——, “Convolutional analysis operator learning: Acceleration and convergence,” IEEE T rans. Image Process. , vol. 29, pp. 2108–2122, 2020. [4] Y . Xu and W . Yin, “A block coordinate descent method for regularized multiconvex optimization with applications to nonnegative tensor factorization and completion,” SIAM J. Imaging Sci. , vol. 6, no. 3, pp. 1758–1789, Sep. 2013. [5] ——, “A globally convergent algorithm for nonconvex optimization based on block coordinate update,” J. Sci. Comput. , vol. 72, no. 2, pp. 700–734, Aug. 2017. [6] I. Y . Chun and J. A. Fessler , “Convolutional analysis operator learning: Application to sparse-view CT,” in Proc. Asilomar Conf. on Signals, Syst., and Comput. , Pacific Grove, CA, Oct. 2018, pp. 1631–1635. [7] Y . Nesterov , “Gradient methods for minimizing composite functions,” Math. Program. , vol. 140, no. 1, pp. 125–161, Aug. 2013. [8] A. Beck and M. T eboulle, “A fast iterative shrinkage-thresholding algorithm for linear inverse problems,” SIAM J. Imaging Sci. , vol. 2, no. 1, pp. 183–202, Mar . 2009. [9] S. Foucart and H. Rauhut, A mathematical introduction to compressive sensing . New Y ork, NY : Springer , 2013. [10] R. T . Rockafellar and R. J.-B. W ets, V ariational analysis . Berlin: Springer V erlag, 2009, vol. 317. [11] R. T . Rockafellar , “Monotone operators and the proximal point algorithm,” SIAM J. Control Optm. , vol. 14, no. 5, pp. 877–898, Aug. 1976. [12] B. S. Mordukhovich and N. M. Nam, “Geometric approach to convex subdifferential calculus,” Optimization , vol. 66, no. 6, pp. 839–873, 2017. [13] E. K. R yu and S. Boyd, “Primer on monotone operator methods,” Appl. Comput. Math , vol. 15, no. 1, pp. 3–43, Jan. 2016. [14] I. Y . Chun, X. Zheng, Y . Long, and J. A. Fessler , “BCD-Net for low- dose CT reconstruction: Acceleration, convergence, and generalization,” in Proc. Med. Image Computing and Computer Assist. Interven. , Shenzhen, China, Oct. 2019, pp. 31–40. [15] I. Y . Chun and J. A. Fessler , “Deep BCD-net using identical encoding-decoding CNN structures for iterative image recovery ,” in Proc. IEEE IVMSP Workshop , Zagori, Greece, Jun. 2018, pp. 1–5. [16] J. H. Cho and J. A. Fessler , “Regularization designs for uniform spatial resolution and noise properties in statistical image reconstruction for 3-D X-ray CT,” IEEE T rans. Med. Imag. , vol. 34, no. 2, pp. 678–689, Feb. 2015. [17] H. Nien and J. A. Fessler , “Relaxed linearized algorithms for faster X-ray CT image reconstruction,” IEEE T rans. Med. Imag. , vol. 35, no. 4, pp. 1090–1098, Apr . 2016. [18] M.-B. Lien, C.-H. Liu, I. Y . Chun, S. Ravishankar , H. Nien, M. Zhou, J. A. Fessler , Z. Zhong, and T . B. Norris, “Ranging and light field imaging with transparent photodetectors,” Nature Photonics , vol. 14, no. 3, pp. 143–148, Jan. 2020. [19] S. Zhang, H. Sheng, C. Li, J. Zhang, and Z. Xiong, “Robust depth estimation for light field via spinning parallelogram operator ,” Comput. V is. Image Und. , vol. 145, pp. 148–159, Apr . 2016. [20] K. Honauer , O. Johannsen, D. Kondermann, and B. Goldluecke, “A dataset and evaluation methodology for depth estimation on 4D light fields,” in Proc. ACCV , T aipei, T aiwan, Nov . 2016, pp. 19–34. [21] H. Lim, I. Y . Chun, Y . K. Dewaraja, and J. A. Fessler , “Improved low-count quantitative PET reconstruction with an iterative neural network,” IEEE T rans. Med. Imag. (to appear), May 2020. [Online]. A vailable: http://arxiv .org/abs/1906.02327 [22] M. G. McGaffin and J. A. Fessler , “Algorithmic design of majorizers for large-scale inverse problems,” ArXiv preprint stat.CO/1508.02958 , Oct. 2015.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment