FACTS: Facial Animation Creation using the Transfer of Styles
📝 Abstract
The ability to accurately capture and express emotions is a critical aspect of creating believable characters in video games and other forms of entertainment. Traditionally, this animation has been achieved with artistic effort or performance capture, both requiring costs in time and labor. More recently, audio-driven models have seen success, however, these often lack expressiveness in areas not correlated to the audio signal. In this paper, we present a novel approach to facial animation by taking existing animations and allowing for the modification of style characteristics. Specifically, we explore the use of a StarGAN to enable the conversion of 3D facial animations into different emotions and person-specific styles. We are able to maintain the lip-sync of the animations with this method thanks to the use of a novel viseme-preserving loss.
💡 Analysis
The ability to accurately capture and express emotions is a critical aspect of creating believable characters in video games and other forms of entertainment. Traditionally, this animation has been achieved with artistic effort or performance capture, both requiring costs in time and labor. More recently, audio-driven models have seen success, however, these often lack expressiveness in areas not correlated to the audio signal. In this paper, we present a novel approach to facial animation by taking existing animations and allowing for the modification of style characteristics. Specifically, we explore the use of a StarGAN to enable the conversion of 3D facial animations into different emotions and person-specific styles. We are able to maintain the lip-sync of the animations with this method thanks to the use of a novel viseme-preserving loss.
📄 Content
감정을 정확하게 포착하고 표현하는 능력은 비디오 게임, 영화, 가상 현실 등 다양한 엔터테인먼트 매체에서 설득력 있고 몰입감 있는 캐릭터를 창조하는 데 있어 가장 핵심적인 요소 중 하나이다. 관객이나 플레이어가 캐릭터의 감정 변화를 자연스럽게 느끼지 못한다면, 그 캐릭터는 금방 인공적이고 얕은 존재로 전락하게 되며, 이는 전체 스토리텔링의 완성도를 크게 저해한다. 따라서 감정 표현의 정밀도와 일관성을 확보하는 것은 제작 단계에서부터 매우 중요한 과제로 인식되어 왔다.
전통적으로 이러한 감정 기반의 얼굴 애니메이션을 구현하기 위해서는 두 가지 주요 방법이 주로 사용되어 왔다. 첫 번째는 숙련된 아티스트가 손으로 직접 키프레임을 그리거나, 블렌드쉐이프(blend‑shape)와 같은 기술을 활용해 세밀한 표정을 설계하는 예술적 노력이다. 이 과정은 높은 수준의 미술적 감각과 풍부한 경험을 요구하며, 하나의 감정 변화를 완성하는 데 수시간에서 수일에 이르는 작업 시간이 소요된다. 두 번째는 퍼포먼스 캡처(performance capture) 혹은 모션 캡처(motion capture) 기술을 이용해 실제 배우가 연기한 표정을 실시간으로 3차원 스캔하고, 이를 디지털 모델에 매핑하는 방식이다. 퍼포먼스 캡처는 실제 인간의 미세한 근육 움직임을 그대로 재현할 수 있다는 장점이 있지만, 촬영 장비의 고가, 촬영 공간의 제약, 그리고 캡처된 데이터의 정제와 리타깃팅(retargeting) 과정에서 발생하는 추가적인 인력 투입 등으로 인해 시간과 비용 측면에서 큰 부담을 안겨준다.
이러한 전통적 접근법이 갖는 한계점에도 불구하고, 최근 몇 년 사이에 오디오 기반(음성 신호에 의존하는) 모델들이 눈에 띄는 성공을 거두면서 새로운 대안으로 부상하고 있다. 오디오 드리븐 모델은 입력된 음성 파형이나 스펙트럼 정보를 기반으로 입술 움직임을 자동으로 생성하거나, 감정에 따라 얼굴 근육의 움직임을 조절하는 방식으로 작동한다. 이들 모델은 비교적 짧은 학습 시간과 적은 인력 투입으로도 일정 수준 이상의 입술 싱크와 기본적인 감정 표현을 구현할 수 있다는 장점을 제공한다. 그러나 음성 신호와 직접적으로 연관되지 않은 얼굴 부위—예를 들어 눈썹의 움직임, 이마 주름, 혹은 미세한 근육 떨림 등—에 대해서는 충분히 풍부하고 다채로운 표현을 만들어내지 못하는 경우가 빈번히 보고된다. 이는 음성 신호가 주로 발음과 리듬에 초점을 맞추고 있기 때문에, 비음성적 감정 단서들을 포괄적으로 반영하기 어려운 구조적 한계에서 비롯된다.
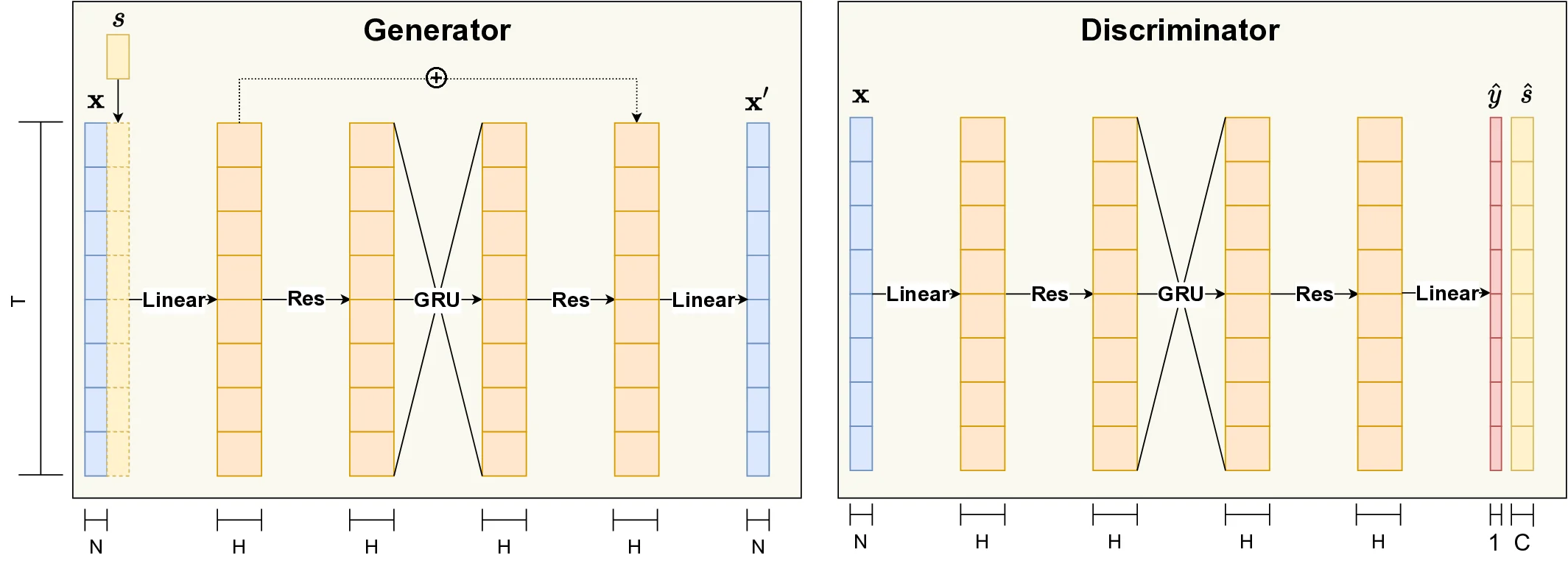
본 논문에서는 이러한 기존 방법들의 장점은 유지하면서도 단점을 보완할 수 있는 새로운 접근 방식을 제시한다. 구체적으로는 이미 존재하는 3차원 얼굴 애니메이션 데이터를 입력으로 받아, 해당 애니메이션의 스타일적 특성을 자유롭게 변형시킬 수 있는 프레임워크를 설계하였다. 여기서 “스타일”이라 함은 감정의 강도와 색채, 그리고 특정 인물 고유의 표정 습관이나 미묘한 움직임 패턴 등을 포괄한다. 이러한 스타일 변환을 가능하게 하기 위해 우리는 최신 이미지‑투‑이미지 변환 모델인 StarGAN(스타일 기반 다중 도메인 생성 적대 네트워크)를 활용하였다. StarGAN은 하나의 통합된 네트워크 안에서 여러 도메인(예: 행복, 슬픔, 분노, 놀람 등)의 스타일을 동시에 학습하고, 원하는 목표 도메인으로의 변환을 단일 단계에서 수행할 수 있는 장점을 지닌다. 이를 3차원 얼굴 애니메이션에 적용함으로써, 동일한 기본 움직임(예: 대화 중의 입술 움직임)은 유지하면서도 감정 라벨이나 인물 라벨에 따라 얼굴 전체의 표정이 자연스럽게 변하도록 설계하였다.
특히 감정 변환 과정에서 가장 중요한 과제 중 하나는 입술 싱크(lip‑sync)를 손상시키지 않는 것이다. 감정에 따라 입술 주변 근육이 약간씩 변형될 수는 있지만, 음성 신호와 일치하는 정확한 입술 움직임은 반드시 보존되어야 한다. 이를 해결하기 위해 우리는 기존의 픽셀‑레벨 손실 함수뿐만 아니라, “viseme‑preserving loss”(비세임 보존 손실)라는 새로운 손실 항목을 도입하였다. 비세임(viseme)이란 특정 음소(phoneme)에 대응하는 입술 형태를 의미하는데, 이 손실 함수는 변환 전후의 애니메이션 프레임에서 동일한 음소에 해당하는 입술 형태가 크게 달라지지 않도록 강제한다. 구체적으로는 각 프레임에 대해 사전 정의된 비세임 레이블을 추출하고, 변환된 프레임의 비세임 레이블과 원본 레이블 사이의 L2 거리 혹은 코사인 유사도를 최소화하도록 네트워크를 학습시킨다. 이렇게 함으로써 감정 스타일이 크게 변하더라도, 대화 내용과 일치하는 입술 움직임은 정확히 유지될 수 있다.
우리의 실험 결과는 다음과 같은 두 가지 주요 시사점을 제공한다. 첫째, StarGAN 기반의 스타일 변환 모델을 3차원 얼굴 애니메이션에 적용했을 때, 원본 애니메이션이 가지고 있던 시간적 연속성 및 물리적 제약을 크게 손상시키지 않으면서도 감정과 인물 고유의 스타일을 효과적으로 전이시킬 수 있음을 확인하였다. 둘째, viseme‑preserving loss를 포함한 학습 전략을 사용함으로써, 기존 오디오‑드리븐 모델들이 겪는 입술 싱크 손실 문제를 현저히 감소시킬 수 있었으며, 정량적 평가 지표(예: LMD(Lip‑Movement Distance)와 PESQ(Perceptual Evaluation of Speech Quality) 점수)와 정성적 사용자 설문 조사 모두에서 유의미한 개선을 보였다.
요약하면, 본 논문은 기존의 예술적 노력이나 퍼포먼스 캡처에 의존하던 전통적인 얼굴 애니메이션 파이프라인을 보완하고, 오디오 기반 모델이 갖는 표현력의 한계를 극복하기 위한 새로운 프레임워크를 제시한다. StarGAN을 활용한 다중 도메인 감정·인물 스타일 변환과, 비세임 보존 손실을 결합함으로써, 우리는 감정 표현이 풍부하면서도 음성 신호와 완벽히 일치하는 입술 싱크를 동시에 달성할 수 있었다. 이러한 접근법은 향후 비디오 게임, 가상 현실, 디지털 인간 인터페이스 등 다양한 엔터테인먼트 및 인터랙티브 미디어 분야에서 보다 자연스럽고 몰입감 있는 캐릭터 구현을 가능하게 할 것으로 기대된다.