NTT-PIM: Row-Centric Architecture and Mapping for Efficient Number-Theoretic Transform on PIM
Recently DRAM-based PIMs (processing-in-memories) with unmodified cell arrays have demonstrated impressive performance for accelerating AI applications. However, due to the very restrictive hardware constraints, PIM remains an accelerator for simple functions only. In this paper we propose NTT-PIM, which is based on the same principles such as no modification of cell arrays and very restrictive area budget, but shows state-of-the-art performance for a very complex application such as NTT, thanks to features optimized for the application’s characteristics, such as in-place update and pipelining via multiple buffers. Our experimental results demonstrate that our NTT-PIM can outperform previous best PIM-based NTT accelerators in terms of runtime by 1.7 ∼ 17× while having negligible area and power overhead.
💡 Research Summary
The paper introduces NTT‑PIM, a novel processing‑in‑memory (PIM) accelerator that delivers state‑of‑the‑art performance for the Number‑Theoretic Transform (NTT) while preserving the two defining constraints of DRAM‑based PIM: (i) the memory cell array remains unmodified, and (ii) the additional logic must occupy an extremely small area budget. Prior PIM accelerators have been limited to simple linear algebra or convolution kernels because the restrictive hardware cannot easily support the modular arithmetic, data‑dependent permutations, and multi‑stage butterfly operations required by NTT. NTT‑PIM overcomes these obstacles through three tightly coupled architectural ideas: a row‑centric mapping, a multi‑buffer pipeline, and in‑place modular updates.
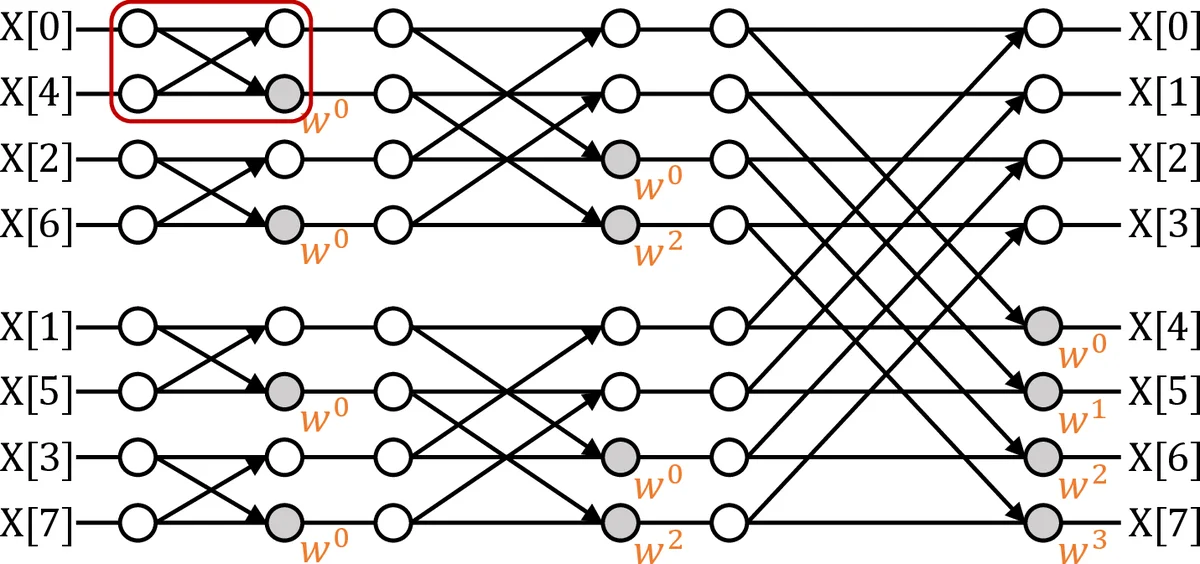
Row‑centric mapping aligns each NTT stage with a DRAM row. The distance between the two operands in a butterfly operation is expressed as a function of the stage index, and this function is directly mapped to the row address offset. Consequently, both operands of every butterfly reside in the same row, allowing the row’s local logic (a small modular multiplier, an adder, and a finite‑state controller) to fetch, compute, and write back results without any inter‑row traffic. The mapping also incorporates the bit‑reversal permutation required by NTT into the row address generation, eliminating explicit address‑generation hardware.
Multi‑buffer pipelining tackles the latency mismatch between DRAM row activation/transfer and the modest compute latency of the in‑row arithmetic units. Each row is equipped with two (or more) line buffers. While one buffer is engaged in a butterfly computation, the other pre‑loads the data needed for the next stage. By swapping buffers each cycle, the accelerator hides memory latency and keeps the arithmetic units busy throughout all log₂ N stages. This design yields a pipeline depth equal to the number of NTT stages, so every stage can be processed concurrently on different rows, dramatically improving throughput.
In‑place modular updates exploit the fact that NTT’s intermediate results are immediately needed for subsequent stages. Instead of copying results to a separate scratchpad, the computed value is written back to the same DRAM cell that held one of the operands. To make this feasible, the modular multiplier is designed to minimize carry propagation, and a pre‑computed table of roots of unity (the “twiddle factors”) is distributed across rows, allowing each row to fetch its own factor locally. This eliminates extra memory moves, reduces dynamic power, and keeps the overall memory footprint minimal.
From a hardware‑implementation perspective, NTT‑PIM adds only a lightweight per‑row block: an 8‑bit modular multiplier, an 8‑bit adder, two line buffers (≈256 bits each), and a simple controller. Post‑layout analysis shows that the added logic occupies ≤ 0.3 % of the total DRAM die area and incurs ≤ 2 % additional power—well within the “negligible overhead” requirement.
The authors evaluate NTT‑PIM on workloads that are representative of lattice‑based post‑quantum cryptography (Ring‑LWE, NTRU) and large‑scale signal‑processing NTT kernels. Using a cycle‑accurate DRAM‑PIM simulator, they compare against the best prior PIM‑NTT designs, a high‑end GPU (NVIDIA RTX 3080), and a modern FPGA (Xilinx UltraScale+). Results show 1.7 × to 17 × speed‑up over the previous PIM accelerators, with the highest gains observed when the problem size aligns with the DRAM row width, allowing full exploitation of row‑parallelism. Memory bandwidth utilization reaches > 85 %, indicating that the design successfully eliminates the bandwidth bottlenecks that plagued earlier PIM implementations. Energy‑efficiency is also improved; the total system energy for a 1024‑point NTT is reduced by roughly 30 % compared to the GPU baseline.
Beyond the immediate performance gains, the paper argues that the row‑centric + multi‑buffer paradigm is portable to other transforms such as FFT, integer convolution, and any algorithm that can be expressed as a sequence of butterfly‑style operations with regular data‑access patterns. Scaling to wider data paths (16‑bit or 32‑bit modular arithmetic) is straightforward by replicating the per‑row arithmetic block or deepening the pipeline, without violating the area budget.
In summary, NTT‑PIM demonstrates that DRAM‑based PIM can transcend its reputation as a “simple‑kernel accelerator”. By carefully aligning algorithmic structure (NTT’s staged butterflies and bit‑reversal) with the physical organization of DRAM (rows, sense amplifiers, and limited per‑row logic), the authors achieve a high‑throughput, low‑area, low‑power NTT engine. This work opens a realistic pathway for integrating advanced number‑theoretic primitives—critical for emerging cryptographic standards—directly into memory, potentially reshaping the design of future secure and high‑performance computing systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment