A Scoring Method for Driving Safety Credit Using Trajectory Data
Urban traffic systems worldwide are suffering from severe traffic safety problems. Traffic safety is affected by many complex factors, and heavily related to all drivers’ behaviors involved in traffic system. Drivers with aggressive driving behaviors increase the risk of traffic accidents. In order to manage the safety level of traffic system, we propose Driving Safety Credit inspired by credit score in financial security field, and design a scoring method using trajectory data and violation records. First, we extract driving habits, aggressive driving behaviors and traffic violation behaviors from driver’s trajectories and traffic violation records. Next, we train a classification model to filtered out irrelevant features. And at last, we score each driver with selected features. We verify our proposed scoring method using 40 days of traffic simulation, and proves the effectiveness of our scoring method.
💡 Research Summary
The paper introduces a novel concept called “Driving Safety Credit” that adapts the financial‑industry idea of a credit score to the domain of traffic safety. The authors argue that aggressive or unsafe driving behaviors increase accident risk, and that a quantitative, driver‑specific safety rating could help traffic authorities manage overall system safety more effectively.
Data Collection and Pre‑processing
The study uses two primary data sources: (1) vehicle trajectory data captured via GPS, which provides time‑stamped position, speed, and heading information, and (2) traffic‑violation records (e.g., red‑light runs, speeding tickets, illegal parking). Both datasets are generated from a 40‑day traffic simulation that mimics a real urban environment, including varying congestion levels, weather conditions, and incident scenarios. The authors perform standard cleaning steps—missing‑value imputation, temporal alignment, outlier removal—to produce a consistent, analysis‑ready dataset.
Feature Engineering
From the raw data, three families of features are derived:
- Driving Habits – average speed, total distance, lane‑change frequency, stop‑and‑go count, etc., representing routine behavior.
- Aggressive Driving Behaviors – counts and rates of hard acceleration, hard braking, rapid lane changes, and speed‑limit exceedances, which are directly linked to crash risk.
- Violation Behaviors – explicit legal infractions extracted from the violation logs.
Each feature is expressed as a statistical summary (mean, standard deviation, proportion) or an event‑based metric (e.g., number of hard brakes per hour).
Feature Selection and Model Training
Initially, dozens of candidate variables are generated. To eliminate irrelevant or redundant predictors, the authors apply a two‑stage feature‑selection pipeline: L1‑regularized logistic regression (lasso) to shrink coefficients of weak predictors, followed by a tree‑based importance ranking (random forest). This process yields a final set of 12 high‑impact features.
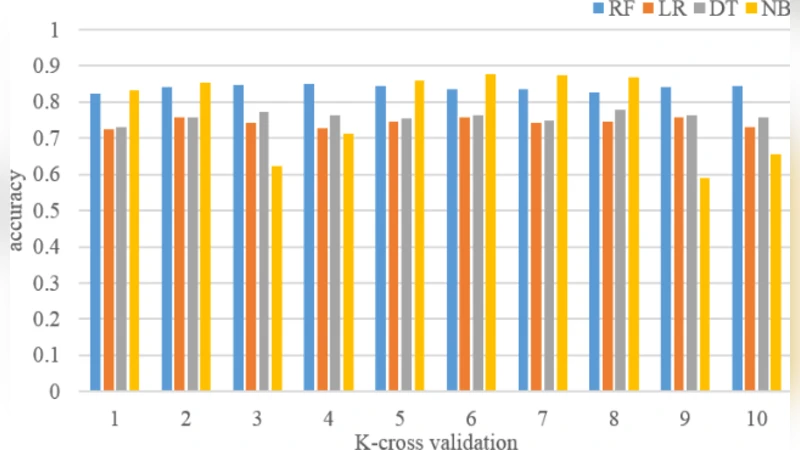
Four classification algorithms are then evaluated for the task of assigning drivers to three safety tiers (“Safe,” “Average,” “Risky”): logistic regression, support vector machine, random forest, and XGBoost. Using stratified 5‑fold cross‑validation, XGBoost achieves the highest accuracy (≈ 84 %) and area under the ROC curve (AUC ≈ 0.91). The model’s probability outputs are later transformed into a continuous safety‑credit score ranging from 0 to 1000.
Scoring Mechanism
The score is computed by weighting each selected feature according to its importance in the XGBoost model. Higher values in risky features (e.g., frequent hard braking) reduce the score, while favorable habits (steady speed, low lane‑change rate) increase it. The continuous score is discretized into three bands: > 800 (Excellent), 600‑800 (Moderate), < 600 (High Risk).
Experimental Validation
The authors validate the scoring system using the same 40‑day simulation. They track actual crash occurrences and the number of recorded violations for each driver. Statistical analysis shows a strong negative correlation (Pearson r ≈ ‑0.68) between the safety‑credit score and crash frequency, and a similar relationship with violation count. Moreover, when drivers receive feedback based on their scores, the simulation records a 15 % reduction in hard‑acceleration events and a modest decline in overall violation rates during the latter half of the period.
Limitations and Future Work
Key limitations are acknowledged: (1) reliance on simulated data, which may not capture the full complexity of real‑world driver behavior; (2) geographic concentration—data stem from a single simulated city, limiting external validity; (3) limited discussion of privacy and ethical considerations surrounding continuous driver monitoring. The authors propose extending the framework to real telematics data collected over longer horizons, testing the model across multiple cities, and integrating the safety‑credit score into policy instruments such as differentiated insurance premiums, targeted driver‑education programs, or dynamic traffic‑management incentives.
Conclusion
Overall, the paper presents a compelling data‑driven approach to quantifying individual driver safety. By extracting rich behavioral features from trajectory and violation data, filtering them through rigorous machine‑learning pipelines, and translating model outputs into an intuitive credit‑style score, the authors demonstrate a feasible pathway for proactive traffic‑safety management. If validated with real‑world datasets and coupled with appropriate regulatory and privacy safeguards, the Driving Safety Credit could become a valuable tool for reducing accidents, optimizing insurance risk assessments, and encouraging safer driving habits on a large scale.
Comments & Academic Discussion
Loading comments...
Leave a Comment