Polyphonic audio tagging with sequentially labelled data using CRNN with learnable gated linear units
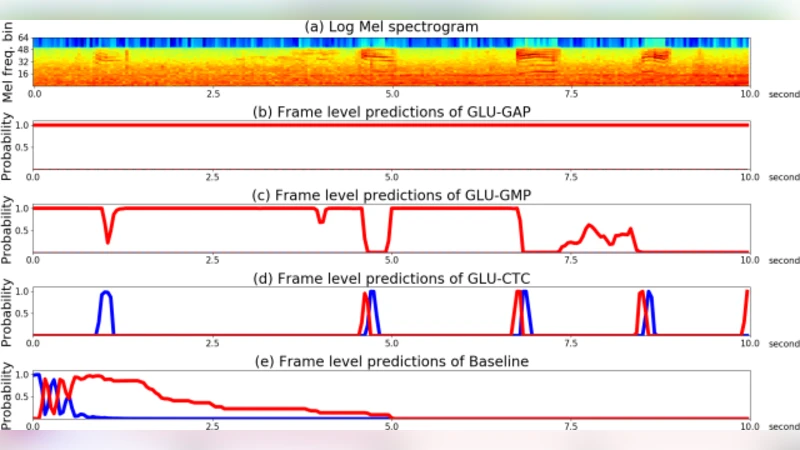
Audio tagging aims to detect the types of sound events occurring in an audio recording. To tag the polyphonic audio recordings, we propose to use Connectionist Temporal Classification (CTC) loss function on the top of Convolutional Recurrent Neural Network (CRNN) with learnable Gated Linear Units (GLU-CTC), based on a new type of audio label data: Sequentially Labelled Data (SLD). In GLU-CTC, CTC objective function maps the frame-level probability of labels to clip-level probability of labels. To compare the mapping ability of GLU-CTC for sound events, we train a CRNN with GLU based on Global Max Pooling (GLU-GMP) and a CRNN with GLU based on Global Average Pooling (GLU-GAP). And we also compare the proposed GLU-CTC system with the baseline system, which is a CRNN trained using CTC loss function without GLU. The experiments show that the GLU-CTC achieves an Area Under Curve (AUC) score of 0.882 in audio tagging, outperforming the GLU-GMP of 0.803, GLU-GAP of 0.766 and baseline system of 0.837. That means based on the same CRNN model with GLU, the performance of CTC mapping is better than the GMP and GAP mapping. Given both based on the CTC mapping, the CRNN with GLU outperforms the CRNN without GLU.
💡 Research Summary
The paper addresses the challenging problem of polyphonic audio tagging, where multiple sound events may overlap within a single recording. The authors introduce two complementary innovations: (1) a new labeling paradigm called Sequentially Labelled Data (SLD) and (2) a model architecture that combines a Convolutional Recurrent Neural Network (CRNN) with learnable Gated Linear Units (GLU) and the Connectionist Temporal Classification (CTC) loss, referred to as GLU‑CTC.
SLD lies between the traditional strong (frame‑level) and weak (clip‑level) annotations. Instead of providing exact onset and offset timestamps for each event, SLD supplies only the ordered list of event labels present in a clip. This preserves temporal ordering information while dramatically reducing annotation effort, making large‑scale dataset creation more feasible. The authors argue that the sequential nature of SLD is well‑suited for sequence‑to‑sequence learning frameworks such as CTC, which can align variable‑length label sequences to frame‑level predictions without explicit timing information.
The model backbone is a standard CRNN: a stack of 2‑D convolutional layers extracts local time‑frequency patterns from log‑mel spectrograms, followed by bidirectional gated recurrent units (Bi‑GRU) that capture long‑range temporal dependencies. A GLU layer is inserted after the convolutional stack. GLU splits its input into two linear projections; one passes through a sigmoid gate, and the gated output is multiplied element‑wise with the other projection. This mechanism enables the network to learn dynamic feature selection, suppressing irrelevant or noisy activations—a crucial advantage in polyphonic environments where background clutter is prevalent.
On top of the GLU‑enhanced CRNN, the CTC loss is applied directly to the frame‑wise output logits. CTC introduces a special “blank” token and sums over all possible alignments between the frame sequence and the target label sequence, thereby learning a mapping from frame‑level probabilities to clip‑level label sequences. Because CTC does not require explicit alignment, it can exploit the ordering information in SLD while remaining tolerant to timing variations.
To evaluate the contribution of each component, the authors construct three comparative systems using the same CRNN backbone: (i) GLU‑CTC (proposed), (ii) GLU‑GMP (GLU followed by Global Max Pooling) and (iii) GLU‑GAP (GLU followed by Global Average Pooling). Additionally, a baseline model that applies CTC without GLU is tested. All systems are trained on a publicly available polyphonic audio dataset that has been re‑annotated into SLD format. Performance is measured using the Area Under the ROC Curve (AUC), a metric robust to class imbalance in multi‑label settings.
Experimental results show a clear hierarchy: GLU‑CTC achieves an AUC of 0.882, outperforming the baseline CTC (0.837), GLU‑GMP (0.803), and GLU‑GAP (0.766). The superiority of GLU‑CTC demonstrates that CTC’s alignment‑aware mapping is more effective than simple pooling strategies, which collapse temporal information and thus lose event ordering cues. The gap between GLU‑GMP and GLU‑GAP further suggests that, in polyphonic audio, the most salient frames (captured by max pooling) carry more discriminative information than the average activation across time. Moreover, the improvement of GLU‑CTC over the GLU‑less baseline confirms that the gating mechanism enhances feature selectivity, leading to cleaner frame‑level predictions that CTC can align more accurately.
The paper’s contributions can be summarized as follows:
- Introduction of Sequentially Labelled Data, a cost‑effective annotation scheme that retains temporal order without requiring precise timestamps.
- Design of a GLU‑CTC architecture that leverages dynamic gating and CTC’s alignment capability to map frame‑level predictions to ordered label sequences.
- Empirical validation that CTC‑based mapping outperforms traditional global pooling approaches and that GLU provides a consistent performance boost when combined with CTC.
Limitations acknowledged by the authors include the reliance on SLD quality (ordering errors could degrade CTC alignment), the relatively modest size of the experimental dataset, and the absence of real‑time or streaming evaluations. Future work is proposed in several directions: scaling SLD annotation to larger and more diverse audio corpora, exploring multi‑scale GLU designs or Transformer‑based encoders to capture richer hierarchical patterns, incorporating Bayesian extensions of CTC to model label uncertainty, and assessing computational efficiency for on‑device deployment.
In conclusion, the study demonstrates that preserving sequential label information and employing an alignment‑aware loss function, together with a gating mechanism that refines feature representations, yields a state‑of‑the‑art solution for polyphonic audio tagging. The findings open avenues for more scalable annotation practices and for integrating advanced sequence modeling techniques into audio understanding systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment