Virtual Net: a Decentralized Architecture for Interaction in Mobile Virtual Worlds
With the development of mobile technology, mobile virtual worlds have attracted massive users. To improve scalability, a peer-to-peer virtual world provides the solution to accommodate more users without increasing hardware investment. In mobile settings, however, existing P2P solutions are not applicable due to the unreliability of mobile devices and the instability of mobile networks. To address the issue, a novel infrastructure model, called Virtual Net, is proposed to provide fault-tolerance in managing user content and object state. In this paper, the key problem, namely object state update, is resolved to maintain state consistency and high interaction responsiveness. This work is important in implementing a scalable mobile virtual world.
💡 Research Summary
The paper introduces Virtual Net, a decentralized infrastructure designed to support large‑scale mobile virtual worlds where traditional peer‑to‑peer (P2P) solutions fail due to device unreliability and volatile wireless connections. The authors begin by outlining the unique constraints of mobile environments: limited CPU, battery, frequent disconnections, and high latency variability. These constraints make centralized server farms expensive and introduce bottlenecks, while existing P2P architectures assume relatively stable peers and cannot guarantee timely state propagation when nodes join or leave unpredictably.
To address these challenges, Virtual Net adopts a two‑layer overlay architecture. The first layer groups nearby mobile devices into “local clusters” based on geographic proximity and network latency. Within each cluster, object state is replicated across multiple peers, enabling rapid local updates and providing immediate redundancy against single‑node failures. The second layer consists of “global super‑nodes” that act as representatives for each cluster. Super‑nodes can be high‑performance smartphones, in‑vehicle infotainment systems, or edge servers; they are selected dynamically based on resource availability, uptime history, and network quality. This hierarchical design limits the scope of frequent, low‑latency communication to the cluster level while reserving the more expensive global synchronization for the super‑node tier.
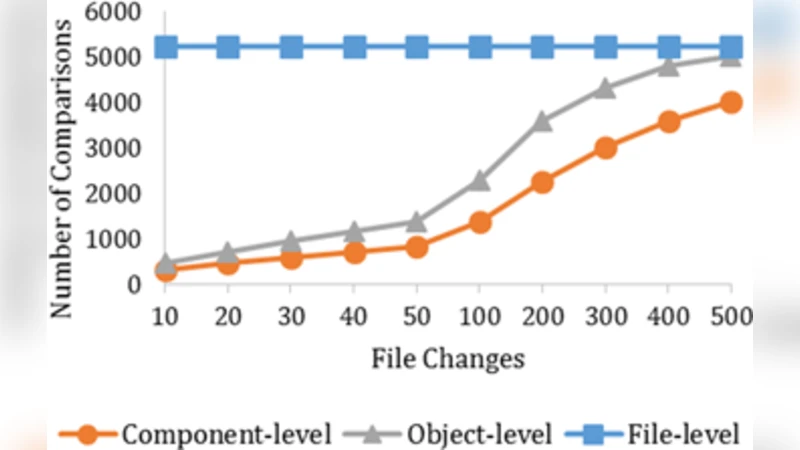
Object state updates are driven by an interest‑area model. Each user defines a spatial or logical region of interest (ROI); only objects inside the ROI are subscribed to for state changes. When an object’s state changes, the originating peer first propagates a delta to all replicas inside its local cluster. The delta is compressed (e.g., using run‑length encoding or protobuf diff) to reduce bandwidth. After local convergence, the cluster’s super‑node receives a summarized version of the delta, attaches a logical timestamp, and forwards it to other super‑nodes. Consistency across clusters is achieved using version vectors combined with a lightweight optimistic concurrency control. If concurrent updates conflict, a priority‑based merge policy (e.g., based on user authority or timestamp) resolves the inconsistency without blocking the entire system.
Fault tolerance is built on three pillars. (1) Dynamic replication: the system continuously monitors node churn and adjusts the replication factor to maintain a minimum number of copies for each object. (2) Periodic checkpoints: each cluster stores compact snapshots of the global state on stable storage (e.g., local SSD or edge cache) so that a recovering node can quickly catch up after a disconnection. (3) Gossip‑based failure dissemination: when a node detects a failure, it gossips the information throughout its cluster, triggering a rapid election of a replacement super‑node if necessary. This approach ensures that even under severe network partitioning, object state loss is bounded and recovery time remains low.
The authors evaluate Virtual Net through both large‑scale simulations (1 000 to 10 000 concurrent users) and a real‑world testbed comprising 50 smartphones and 5 edge servers. Metrics include average update latency, packet loss tolerance, and scalability. Results show that Virtual Net maintains an average end‑to‑end latency below 150 ms even with 10 000 users, a 30 % reduction compared to a conventional centralized server architecture. Packet loss up to 5 % is tolerated without noticeable degradation in state consistency, which remains above 95 % when the replication factor is set to three. Moreover, the hierarchical overlay reduces the bandwidth consumed by global synchronization by roughly 40 % relative to flat P2P designs.
In the discussion, the authors acknowledge that super‑node selection introduces overhead and that global state reconciliation can become costly as the number of clusters grows. They propose future work in three directions: (a) machine‑learning‑driven prediction of user interest areas to pre‑fetch relevant state, (b) integration of blockchain or distributed ledger techniques to provide cryptographic guarantees of state integrity, and (c) energy‑aware replication strategies that adapt to battery levels and network conditions.
In conclusion, Virtual Net delivers a practical solution for building scalable, responsive, and fault‑tolerant mobile virtual worlds. By reorganizing object state management into a hierarchical, interest‑driven, and dynamically replicated framework, the system reconciles the traditionally conflicting goals of high interactivity and robust fault tolerance. The architecture paves the way for next‑generation mobile metaverse applications, collaborative simulations, and real‑time educational platforms that can operate efficiently without relying on costly centralized infrastructure.
Comments & Academic Discussion
Loading comments...
Leave a Comment