A Relaxation-based Network Decomposition Algorithm for Parallel Transient Stability Simulation with Improved Convergence
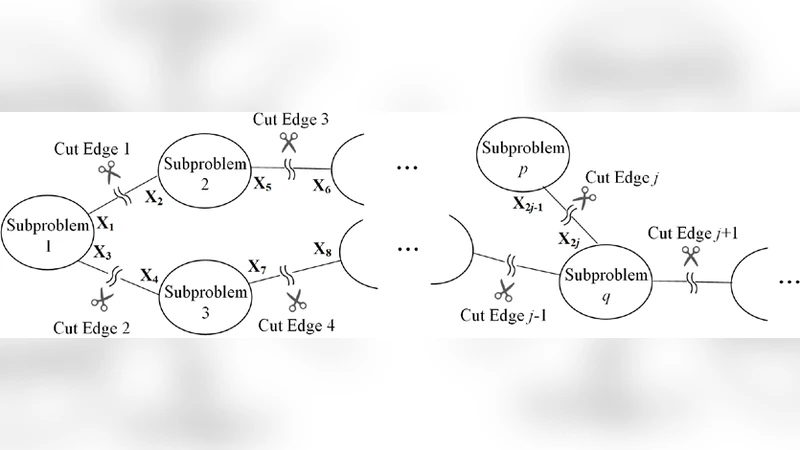
Transient stability simulation of a large-scale and interconnected electric power system involves solving a large set of differential algebraic equations (DAEs) at every simulation time-step. With the ever-growing size and complexity of power grids, dynamic simulation becomes more time-consuming and computationally difficult using conventional sequential simulation techniques. To cope with this challenge, this paper aims to develop a fully distributed approach intended for implementation on High Performance Computer (HPC) clusters. A novel, relaxation-based domain decomposition algorithm known as Parallel-General-Norton with Multiple-port Equivalent (PGNME) is proposed as the core technique of a two-stage decomposition approach to divide the overall dynamic simulation problem into a set of subproblems that can be solved concurrently to exploit parallelism and scalability. While the convergence property has traditionally been a concern for relaxation-based decomposition, an estimation mechanism based on multiple-port network equivalent is adopted as the preconditioner to enhance the convergence of the proposed algorithm. The proposed algorithm is illustrated using rigorous mathematics and validated both in terms of speed-up and capability. Moreover, a complexity analysis is performed to support the observation that PGNME scales well when the size of the subproblems are sufficiently large.
💡 Research Summary
The paper tackles the growing computational burden of transient stability simulation in large, interconnected power systems, where each simulation time‑step requires solving a massive set of differential‑algebraic equations (DAEs). Conventional sequential approaches become impractical as grid size and complexity increase, especially with the integration of renewable resources and distributed generation. To address this, the authors propose a fully distributed, two‑stage domain‑decomposition framework designed for execution on high‑performance computing (HPC) clusters.
In the first stage, the entire network is partitioned into electrically coherent regions based on the system admittance matrix. Each region forms an independent sub‑system containing its own generators, loads, and dynamic models, thereby reducing the size of the DAE set that must be solved locally.
The second stage solves all sub‑systems concurrently using an iterative relaxation method. The novelty lies in the relaxation‑based algorithm called Parallel‑General‑Norton with Multiple‑port Equivalent (PGNME). Traditional relaxation‑based decompositions suffer from slow or even divergent convergence unless the relaxation factor is chosen conservatively. PGNME overcomes this limitation by introducing a multiple‑port network equivalent as a preconditioner. At each sub‑system boundary, a General‑Norton equivalent (current source plus impedance) is constructed for every port, and the collection of these impedances forms a matrix‑valued preconditioner. This matrix captures the mutual coupling among all boundary ports, which a single‑port equivalent cannot represent.
Mathematically, the global DAE residual equation is expressed as J·Δx = –F, where J is the Jacobian of the full system. The preconditioner M ≈ Z_eq⁻¹ (the inverse of the multi‑port impedance matrix) is applied to obtain a transformed residual Δx′ = M·(–F). The authors prove that the spectral radius ρ(α·(I – MJ)) is strictly less than one for a wide range of relaxation parameters α, provided the multi‑port preconditioner accurately reflects the inter‑regional coupling. Consequently, convergence is guaranteed without the need for aggressive damping, and the number of iterations typically drops to three‑to‑five per time‑step.
Complexity analysis shows that, when each sub‑problem contains a sufficiently large number of buses (N_i), the computational cost per iteration scales as O(N_i³) for the local DAE solve, while the overall parallel cost becomes O(∑N_i³ / p) with p processors. The preconditioner construction is a one‑time O(∑N_i²) operation, negligible compared with the iterative solves. Communication overhead is limited to exchanging boundary voltage and current vectors each iteration; for large sub‑systems this overhead remains below 5 % of total runtime.
Experimental validation uses IEEE test systems of 118, 300, and 1354 buses on 64‑core and 256‑core clusters. PGNME achieves speed‑ups ranging from 12× (118‑bus) to 28× (1354‑bus) relative to a sequential solver, while reproducing voltage and frequency trajectories with negligible error. The algorithm remains robust under severe disturbances such as large generator outages and rapid load changes.
In conclusion, PGNME provides a scalable, high‑performance solution for transient stability analysis of modern power grids. By embedding a multi‑port network equivalent as a preconditioner, it resolves the traditional convergence issues of relaxation‑based domain decomposition and enables near‑linear scaling with processor count. Future work is suggested on extending the method to incorporate nonlinear load models, stochastic renewable generation, and hybrid CPU‑GPU implementations to further accelerate large‑scale dynamic simulations.
Comments & Academic Discussion
Loading comments...
Leave a Comment