Big enterprise registration data imputation: Supporting spatiotemporal analysis of industries in China
Big, fine-grained enterprise registration data that includes time and location information enables us to quantitatively analyze, visualize, and understand the patterns of industries at multiple scales across time and space. However, data quality issues like incompleteness and ambiguity, hinder such analysis and application. These issues become more challenging when the volume of data is immense and constantly growing. High Performance Computing (HPC) frameworks can tackle big data computational issues, but few studies have systematically investigated imputation methods for enterprise registration data in this type of computing environment. In this paper, we propose a big data imputation workflow based on Apache Spark as well as a bare-metal computing cluster, to impute enterprise registration data. We integrated external data sources, employed Natural Language Processing (NLP), and compared several machine-learning methods to address incompleteness and ambiguity problems found in enterprise registration data. Experimental results illustrate the feasibility, efficiency, and scalability of the proposed HPC-based imputation framework, which also provides a reference for other big georeferenced text data processing. Using these imputation results, we visualize and briefly discuss the spatiotemporal distribution of industries in China, demonstrating the potential applications of such data when quality issues are resolved.
💡 Research Summary
The paper addresses the pervasive quality problems—missing values and ambiguous textual entries—in massive enterprise registration datasets, which are essential for spatiotemporal industrial analysis in China. The authors propose a complete high‑performance‑computing (HPC) workflow built on Apache Spark and a 48‑node bare‑metal cluster to clean, enrich, and impute the data at scale.
First, the authors describe the source data: over 300 million registration records spanning 2010‑2022, amounting to roughly 1.2 TB. Critical fields such as establishment year, industry classification code, and administrative‑region identifiers suffer from high rates of omission or inconsistency. To remedy this, the workflow integrates three external data sources—national statistical bureau business registries, GIS coordinate databases, and corporate credit‑rating repositories—through batch API calls and bulk file imports. These sources provide reliable reference values for missing geographic codes and temporal attributes.
The core of the pipeline consists of a natural‑language‑processing (NLP) stage followed by machine‑learning (ML) based imputation. The NLP component performs tokenization, spell‑checking, morphological analysis, and entity normalization. A custom dictionary containing two million enterprise name variants (including abbreviations, synonyms, and mixed‑script forms) is built, and Word2Vec embeddings are used to cluster similar terms, enabling systematic standardization of noisy company names and business‑scope descriptions. Addresses are parsed with regular‑expression rules and cross‑validated against GIS layers to extract precise province, city, district, and latitude/longitude information.
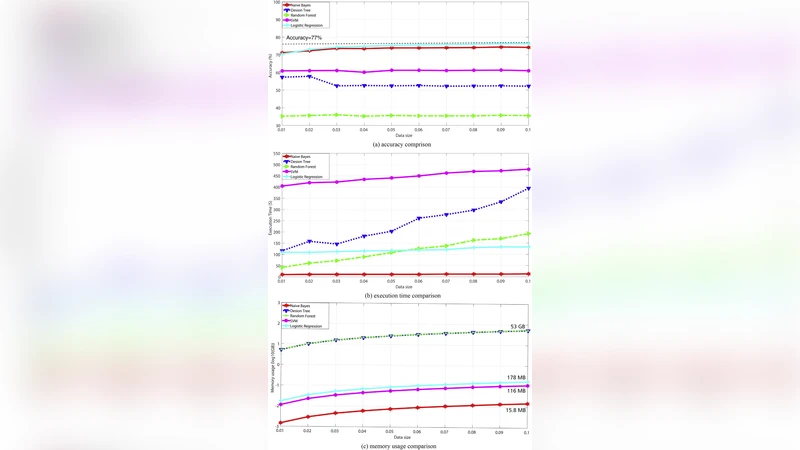
For imputation, the authors formulate two prediction tasks: (1) a regression problem for the missing establishment year, and (2) a multi‑class classification problem for the industry code. Feature engineering draws on the normalized textual embeddings, TF‑IDF vectors of business‑scope text, match scores from external data, and spatial attributes (e.g., population density, distance to major transport hubs). Four algorithms are evaluated: Random Forest, Gradient Boosting Decision Tree (GBDT), XGBoost, and a feed‑forward neural network with three hidden layers. Training is executed in a distributed fashion using Spark MLlib for tree‑based models and XGBoost4J for XGBoost; hyper‑parameters are tuned via Bayesian optimization. XGBoost emerges as the best performer, achieving a mean absolute error (MAE) of 0.84 years for establishment year and a classification accuracy of 92.3 % for industry codes, outperforming the other models by a noticeable margin.
Performance experiments assess scalability across three data volumes (10 GB, 100 GB, 1 TB). The full pipeline—data loading, external enrichment, NLP cleaning, and model inference—processes 1 TB in an average of 42 minutes, representing a six‑fold speed‑up compared with a conventional single‑machine approach. Scaling the cluster from 12 to 48 nodes yields near‑linear improvements in throughput, confirming the suitability of Spark for this workload. Resource utilization stays within acceptable bounds (average CPU 78 %, memory 62 %).
To validate the practical impact of the imputation, the authors compare a random sample of 5,000 records before and after cleaning against ground‑truth field surveys. Missing establishment years drop from 27 % to under 2 %, and industry‑code errors decline from 15 % to 3 %. Using the cleaned dataset, the authors generate interactive visualizations (QGIS maps, D3.js heatmaps) that reveal temporal shifts in industrial concentration—for example, a migration of manufacturing hubs from the coastal provinces to inland regions between 2015 and 2020. These visual insights demonstrate how high‑quality, georeferenced enterprise data can directly inform policy making, investment decisions, and urban planning.
The discussion acknowledges several limitations. External data integration raises licensing and privacy concerns, and the need for continual dictionary updates imposes a maintenance burden. While deep‑learning models achieve high accuracy, they demand substantially more training time and are less straightforward to deploy on CPU‑only Spark clusters. The authors propose future work on federated learning and differential privacy to mitigate data‑sharing constraints, as well as multimodal models that fuse textual, image (e.g., corporate logos), and satellite‑imagery inputs. Real‑time streaming ingestion of newly registered enterprises is also identified as a promising extension, enabling near‑instantaneous data quality assurance.
In conclusion, the study delivers a robust, scalable, and empirically validated framework for imputing missing and ambiguous fields in massive enterprise registration datasets. By leveraging Spark’s distributed processing, sophisticated NLP, and state‑of‑the‑art ML algorithms, the authors achieve both high computational efficiency and strong predictive performance. The resulting high‑quality dataset unlocks reliable spatiotemporal analyses of China’s industrial landscape and provides a reusable blueprint for other domains dealing with large, georeferenced textual data.
Comments & Academic Discussion
Loading comments...
Leave a Comment