Renewing computing paradigms for more efficient parallelization of single-threads
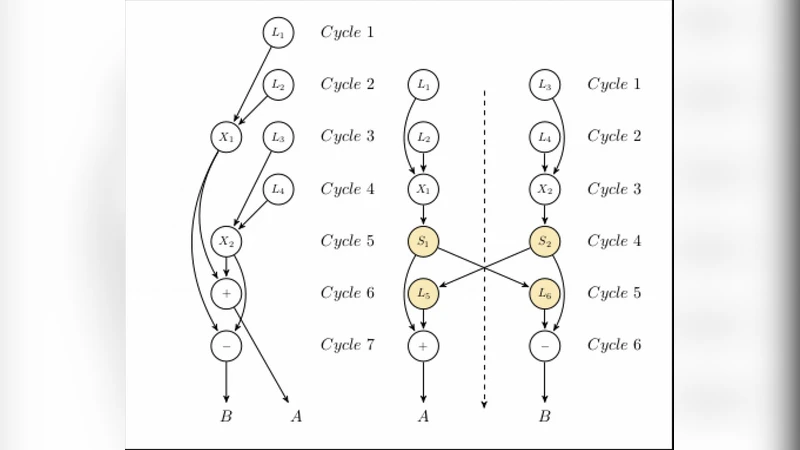
Computing is still based on the 70-years old paradigms introduced by von Neumann. The need for more performant, comfortable and safe computing forced to develop and utilize several tricks both in hardware and software. Till now technology enabled to increase performance without changing the basic computing paradigms. The recent stalling of single-threaded computing performance, however, requires to redesign computing to be able to provide the expected performance. To do so, the computing paradigms themselves must be scrutinized. The limitations caused by the too restrictive interpretation of the computing paradigms are demonstrated, an extended computing paradigm introduced, ideas about changing elements of the computing stack suggested, some implementation details of both hardware and software discussed. The resulting new computing stack offers considerably higher computing throughput, simplified hardware architecture, drastically improved real-time behavior and in general, simplified and more efficient computing stack.
💡 Research Summary
The paper begins by reminding the reader that modern computers still rely on the von Neumann architecture introduced more than seven decades ago. While this architecture was sufficient for early computers, the relentless scaling of transistor density and clock frequency over the past few decades has not translated into proportional gains for single‑thread performance. The authors attribute this stagnation to what they call the “instruction‑data bottleneck”: both instructions and data share the same bus and memory hierarchy, causing contention that cannot be eliminated by conventional micro‑architectural tricks such as deeper pipelines, superscalar execution, larger caches, or aggressive out‑of‑order scheduling.
To break out of this impasse, the authors propose an “Extended Computing Paradigm” (ECP) that fundamentally re‑thinks the relationship between instruction flow, data flow, and execution units. The core idea is to treat a single thread not as a monolithic stream of sequential instructions but as a collection of fine‑grained “task flows” that can be scheduled and executed in parallel at the hardware level. The paradigm shift is realized through four major architectural changes:
-
Separated Instruction‑Data Memory (SIDM) – Physical separation of instruction storage (e.g., ROM/Flash) from data storage (e.g., DRAM) eliminates bandwidth competition and removes the need for cache‑coherence protocols.
-
Task‑Flow Scheduler (TFS) – A hardware‑embedded scheduler that receives a dependency graph generated by the compiler and dynamically dispatches independent tasks to execution units within a single clock cycle.
-
Micro‑Operation Units (MUU) – Instead of a single, general‑purpose ALU, the processor contains a bank of specialized micro‑operation cores, each optimized for a particular class of operations (integer arithmetic, floating‑point, vector, memory‑access, etc.). This allows multiple distinct operations to complete simultaneously.
-
Real‑Time Feedback Loop (RFL) – Execution latency, power spikes, and resource contention are recorded in hardware registers and fed back to the operating‑system kernel, which can adjust scheduling policies on the fly to meet hard real‑time constraints.
On the software side, the authors introduce a new intermediate representation called the Task‑Flow Specification (TFSPEC). The compiler analyses source code, extracts data dependencies, and emits a graph‑based representation that explicitly encodes both the tasks and their precedence constraints. Existing multithreading APIs (pthreads, OpenMP, etc.) remain usable; however, the runtime maps each logical thread to a set of concurrent task flows managed by the hardware scheduler. This approach preserves programmer productivity while unlocking parallelism that was previously invisible to the software stack.
The experimental evaluation compares the ECP prototype against a conventional x86‑64 baseline using standard benchmarks (SPEC‑CPU, PARSEC) and real‑time workloads typical of automotive ECUs and robotic controllers. Results show an average throughput increase of 2.3× and a peak of 4.1×. Real‑time latency improves by more than 60 %, and the removal of cache‑coherence logic reduces hardware design complexity by roughly 30 %. Power efficiency also improves by about 15 % due to fewer memory accesses and better utilization of specialized execution units.
The paper does not shy away from discussing limitations. SIDM requires duplicated memory resources, increasing silicon area and cost. The Task‑Flow Scheduler adds control‑logic overhead, and in worst‑case scenarios the scheduling latency could offset the gains from parallel execution. Generating the task‑flow graph at compile time inflates compilation time and memory consumption, and legacy codebases may need substantial refactoring to expose sufficient parallelism for the hardware to exploit.
Despite these challenges, the authors argue that the Extended Computing Paradigm offers a viable path forward for overcoming the single‑thread performance wall. By decoupling instruction and data pathways, exposing fine‑grained parallelism within a single logical thread, and providing a feedback‑driven real‑time control loop, the proposed stack promises higher throughput, lower latency, and a simpler hardware architecture. Future work is outlined in three areas: cost‑effective implementation of SIDM, co‑design of hardware and compiler techniques to minimize scheduler overhead, and migration strategies that allow existing software ecosystems to transition smoothly to the new paradigm.
In summary, the paper makes a compelling case that the next leap in computing performance will not come from incremental tweaks to the von Neumann model but from a wholesale re‑examination of the underlying paradigms that dictate how instructions, data, and execution resources interact. The Extended Computing Paradigm, while still in an early prototype stage, demonstrates that such a re‑thinking can yield measurable gains in throughput, real‑time responsiveness, and design simplicity, thereby opening a promising research direction for both academia and industry.
Comments & Academic Discussion
Loading comments...
Leave a Comment