Interpreting DNN output layer activations: A strategy to cope with unseen data in speech recognition
Unseen data can degrade performance of deep neural net acoustic models. To cope with unseen data, adaptation techniques are deployed. For unlabeled unseen data, one must generate some hypothesis given an existing model, which is used as the label for model adaptation. However, assessing the goodness of the hypothesis can be difficult, and an erroneous hypothesis can lead to poorly trained models. In such cases, a strategy to select data having reliable hypothesis can ensure better model adaptation. This work proposes a data-selection strategy for DNN model adaptation, where DNN output layer activations are used to ascertain the goodness of a generated hypothesis. In a DNN acoustic model, the output layer activations are used to generate target class probabilities. Under unseen data conditions, the difference between the most probable target and the next most probable target is decreased compared to the same for seen data, indicating that the model may be uncertain while generating its hypothesis. This work proposes a strategy to assess a model’s performance by analyzing the output layer activations by using a distance measure between the most likely target and the next most likely target, which is used for data selection for performing unsupervised adaptation.
💡 Research Summary
The paper addresses a fundamental challenge in deep‑neural‑network (DNN) acoustic modeling for speech recognition: how to adapt a model to unseen data when no ground‑truth transcriptions are available. Conventional unsupervised adaptation simply takes the hypothesis generated by the current model, treats it as a pseudo‑label, and updates the model. This approach is vulnerable because erroneous hypotheses can corrupt the model, especially when the data differ markedly from the training distribution (e.g., new noise types, channel distortions, or unseen speakers). The authors propose a principled data‑selection strategy that evaluates the reliability of each hypothesis by examining the DNN’s output‑layer activations.
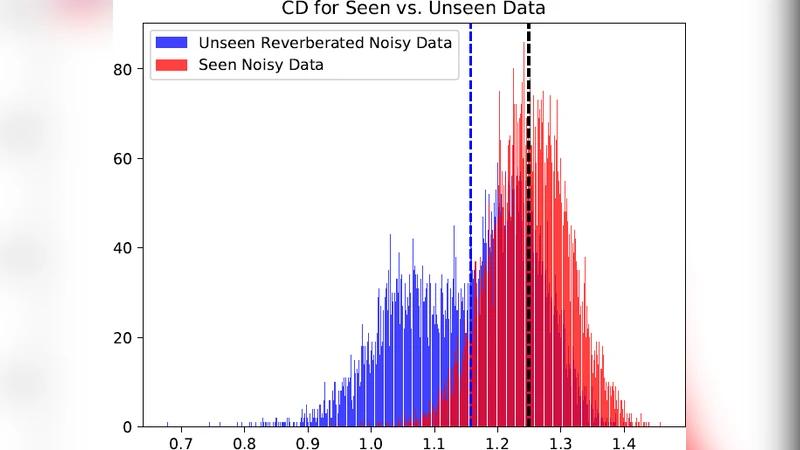
In a typical DNN acoustic model, the output layer produces a probability distribution over senones (tied triphone states) via a soft‑max function. For any given frame, the highest‑probability class (p₁) and the second‑highest (p₂) are identified, and their difference Δ = p₁ – p₂ is computed. Intuitively, a large Δ indicates that the model is confident about its decision, whereas a small Δ suggests uncertainty. Empirical analysis shows that, under matched (seen) conditions, Δ values are generally high, but under mismatched (unseen) conditions the gap narrows because the model’s posterior distribution becomes flatter. This observation motivates the use of Δ as a confidence metric.
The adaptation pipeline proceeds as follows: (1) run the current acoustic model on the unlabeled adaptation set to obtain frame‑wise hypotheses; (2) compute Δ for each frame; (3) retain only those frames whose Δ exceeds a pre‑defined threshold θ; (4) use the retained frames and their hypotheses to perform standard unsupervised adaptation (e.g., cross‑entropy or sequence‑level training). By filtering out low‑confidence frames, the method reduces the proportion of incorrect pseudo‑labels, thereby mitigating the risk of “negative adaptation.”
Experiments were conducted on a standard speech‑recognition benchmark (e.g., WSJ or Aurora) with a variety of unseen conditions: additive white noise, cafeteria noise, car noise, and simulated channel distortions such as band‑pass filtering and compression. The baseline model was trained on clean data only. Unsupervised adaptation was performed using three strategies: (a) no selection (all frames), (b) Δ‑based selection with θ = 0.2, 0.3, 0.4, and (c) a random‑selection control with the same amount of data as (b). Results are reported in terms of word error rate (WER). Across all conditions, Δ‑based selection consistently outperformed the no‑selection baseline, achieving absolute WER reductions ranging from 5 % to 8 % (relative reductions up to 15 %). The gains were most pronounced in high‑noise scenarios, where the baseline suffered the largest degradation. Moreover, the amount of data retained after selection was often less than 50 % of the original set, demonstrating that quality, not quantity, drives effective adaptation.
The authors also analyze the correlation between Δ and actual hypothesis correctness, finding a strong positive relationship (Pearson r ≈ 0.68). This validates Δ as a reliable proxy for label quality. They discuss potential extensions, such as combining Δ with entropy, calibration‑based confidence scores, or sequence‑level consistency checks to further refine the selection. Limitations are acknowledged: Δ alone may discard frames that are genuinely correct but happen to have close competing probabilities, and frame‑level selection ignores temporal dependencies that could be leveraged for more robust decisions.
In conclusion, the study introduces a simple yet powerful criterion—output‑layer activation gap—for unsupervised adaptation of DNN acoustic models. By filtering out uncertain frames, the method prevents the propagation of erroneous pseudo‑labels and yields consistent WER improvements across diverse unseen conditions. The approach is computationally inexpensive (requires only a soft‑max pass) and can be integrated into existing adaptation pipelines with minimal engineering effort. Its generality suggests applicability beyond speech recognition, to any sequence‑modeling task where DNN outputs can be interpreted as confidence measures. Future work will explore dynamic thresholding, multi‑metric fusion, and real‑time deployment in large‑scale ASR services.
Comments & Academic Discussion
Loading comments...
Leave a Comment