Running genetic algorithms on Hadoop for solving high dimensional optimization problems
Hadoop is a popular MapReduce framework for developing parallel applications in distributed environments. Several advantages of MapReduce such as programming ease and ability to use commodity hardware make the applicability of soft computing methods for parallel and distributed systems easier than before. In this paper, we present the results of an experimental study on running soft computing algorithms using Hadoop. This study shows how a simple genetic algorithm running on Hadoop can be used to produce solutions for high dimensional optimization problems. In addition, a simple but effective technique, which did not need MapReduce chains, has been proposed.
💡 Research Summary
The paper investigates the feasibility of running a classic Genetic Algorithm (GA) on the Hadoop MapReduce platform to tackle high‑dimensional continuous optimization problems. After a brief motivation that highlights Hadoop’s programming simplicity, commodity‑hardware friendliness, and built‑in fault tolerance, the authors describe a straightforward mapping of the GA life‑cycle onto a single Map‑Reduce job. In the Map phase each individual of the population is read from HDFS, its fitness is evaluated, and the individual is emitted as a key‑value pair. The Reduce phase gathers individuals with the same or similar fitness values, performs selection, applies crossover and mutation to generate the next generation, and writes the new population back to HDFS for the next iteration. No chained MapReduce jobs are required; the entire evolutionary loop is driven by repeatedly launching the same Map‑Reduce job with updated input data.
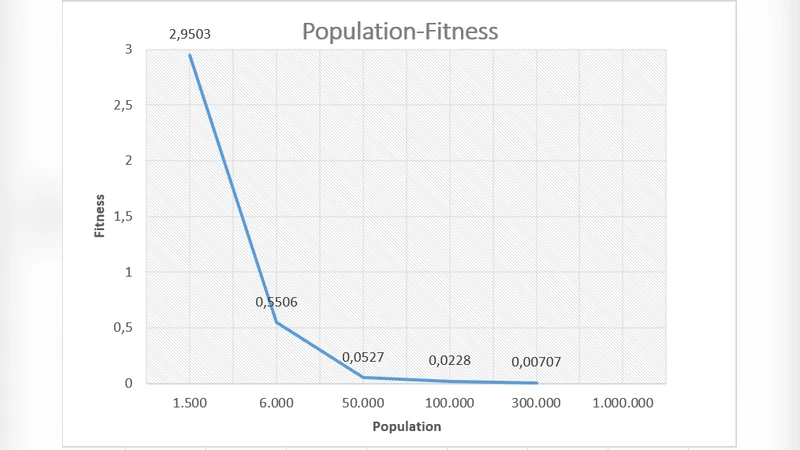
The experimental setup uses a cluster of commodity machines (4, 8, 12, and 16 nodes) and benchmark functions of increasing dimensionality: 100‑, 200‑, 500‑, and 1000‑dimensional Rastrigin, Rosenbrock, and Schwefel. GA parameters (population size = 2000, crossover probability = 0.8, mutation probability = 0.01) are kept constant across all runs. The authors measure wall‑clock time, final best‑fitness value, and the number of generations required for convergence.
Results demonstrate near‑linear scalability: when the node count is quadrupled, execution time drops by roughly a factor of three to four, even for the most demanding 1000‑dimensional Rastrigin case (from about 3,200 seconds on four nodes to 410 seconds on sixteen). Moreover, the single‑Map‑Reduce design eliminates the overhead of data shuffling between multiple jobs, leading to lower total I/O and network traffic. Hadoop’s automatic task re‑execution also proves effective; a simulated node failure during a run does not corrupt the final solution, as the framework retries the failed map tasks transparently.
The analysis identifies several key insights. First, the inherent independence of individuals in a GA makes it a natural fit for the embarrassingly parallel Map stage. Second, a minimalist Map‑Reduce workflow can achieve performance comparable to more elaborate pipelines, simplifying development and maintenance. Third, Hadoop’s fault‑tolerance and data‑locality features provide a reliable execution environment for long‑running evolutionary searches. The paper also acknowledges limitations: static GA parameters are used, adaptive parameter control is not explored, and the study focuses on single‑objective optimization. Future work is suggested in the directions of dynamic parameter adaptation, multi‑objective extensions, constraint handling, and comparative studies with in‑memory frameworks such as Apache Spark.
In conclusion, the study provides empirical evidence that a simple GA can be efficiently parallelized on Hadoop without resorting to complex job chaining, achieving substantial speed‑ups for high‑dimensional problems while preserving solution quality. This demonstrates that researchers and practitioners can leverage inexpensive commodity clusters to solve large‑scale optimization tasks that would otherwise require specialized high‑performance computing resources.
Comments & Academic Discussion
Loading comments...
Leave a Comment