Anthropic decision theory
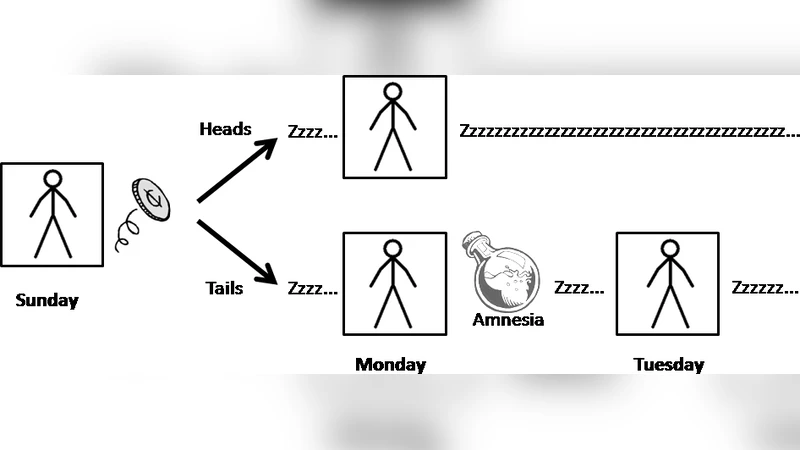
This paper sets out to resolve how agents ought to act in the Sleeping Beauty problem and various related anthropic (self-locating belief) problems, not through the calculation of anthropic probabilities, but through finding the correct decision to make. It creates an anthropic decision theory (ADT) that decides these problems from a small set of principles. By doing so, it demonstrates that the attitude of agents with regards to each other (selfish or altruistic) changes the decisions they reach, and that it is very important to take this into account. To illustrate ADT, it is then applied to two major anthropic problems and paradoxes, the Presumptuous Philosopher and Doomsday problems, thus resolving some issues about the probability of human extinction.
💡 Research Summary
The paper tackles the long‑standing difficulty of deciding how an agent should act in anthropic or self‑locating problems such as the Sleeping Beauty puzzle, not by trying to assign a “correct” anthropic probability but by constructing a decision‑theoretic framework that directly yields the optimal action. The author introduces Anthropic Decision Theory (ADT), which rests on four simple principles: (1) treat all possible worlds consistent with the agent’s self‑locating uncertainty as equally real for the purpose of decision making; (2) recognize that the agent may be duplicated (e.g., multiple awakenings) and that other agents may exist, and explicitly specify how their utilities are weighted; (3) retain the standard expected‑utility calculation but allow two distinct weighting modes—self‑ish (the agent cares only about its own copies) and altruistic (the agent cares about all copies and possibly other beings); and (4) choose the policy that maximizes the summed utility under the chosen weighting mode.
Applying ADT to the classic Sleeping Beauty problem shows how the disagreement between the “halfers” (who assign a 1/2 probability to heads) and the “thirders” (who assign 1/3) can be understood as a clash of utility‑weighting attitudes. A self‑ish Beauty cares only about the payoff she receives when she is awake; she therefore bets only when she knows she is the unique awake copy, reproducing the half‑probability solution. An altruistic Beauty, by contrast, cares about the total payoff across all possible awakenings, which leads her to adopt the thirder’s 1/3‑based betting strategy. Thus ADT does not “solve” the probability puzzle; it explains why different rational agents, given different ethical stances, should make different choices.
The theory is then deployed on two high‑profile anthropic paradoxes. In the Presumptuous Philosopher scenario, a philosopher who assumes that humanity occupies a vastly larger fraction of the universe than is warranted would conclude that human extinction is extremely unlikely. ADT shows that a self‑ish philosopher will indeed ignore the low prior weight of humanity because his utility is tied only to his own existence. An altruistic philosopher, however, must incorporate the welfare of all possible intelligent beings; this dramatically reduces the confidence in humanity’s dominance and yields a more cautious assessment of extinction risk.
Finally, the Doomsday argument, which claims that because we find ourselves early in the total human timeline we should expect a near‑term end, is re‑examined. Traditional Bayesian treatments treat the observed birth rank as evidence that the total number of humans will be relatively small, inflating extinction probability. ADT reframes the issue: a self‑ish agent evaluates only his own future prospects, so the early birth rank does not substantially lower his expected utility, and he therefore does not see a heightened doomsday risk. An altruistic agent, by contrast, aggregates the welfare of all future humans (and possibly other sentient species); the early rank becomes a more significant piece of evidence, leading to a more conservative estimate of survival.
Overall, the paper’s contribution is methodological rather than purely probabilistic. By making the agent’s ethical stance an explicit parameter in the decision model, ADT unifies a variety of anthropic puzzles under a single formalism and clarifies why they have produced apparently contradictory conclusions. It demonstrates that the “right” answer to an anthropic problem is not a single probability but a pair of optimal policies, one for self‑ish agents and one for altruistic agents. The framework opens a path for future work in AI safety, cosmology, and normative ethics, where agents must routinely make decisions under self‑locating uncertainty. Further research is suggested to extend ADT to multi‑agent games with strategic interaction and to develop empirical methods for estimating the appropriate utility‑weighting parameters in real‑world contexts.
Comments & Academic Discussion
Loading comments...
Leave a Comment