A Study of Unsupervised Adaptive Crowdsourcing
We consider unsupervised crowdsourcing performance based on the model wherein the responses of end-users are essentially rated according to how their responses correlate with the majority of other responses to the same subtasks/questions. In one setting, we consider an independent sequence of identically distributed crowdsourcing assignments (meta-tasks), while in the other we consider a single assignment with a large number of component subtasks. Both problems yield intuitive results in which the overall reliability of the crowd is a factor.
💡 Research Summary
The paper introduces a novel unsupervised adaptive crowdsourcing framework that evaluates worker responses solely on how well they correlate with the majority of other responses to the same subtasks or questions. By treating the agreement with the crowd as a proxy for reliability, the authors avoid the need for any ground‑truth labels or external supervision, thereby reducing labeling costs dramatically.
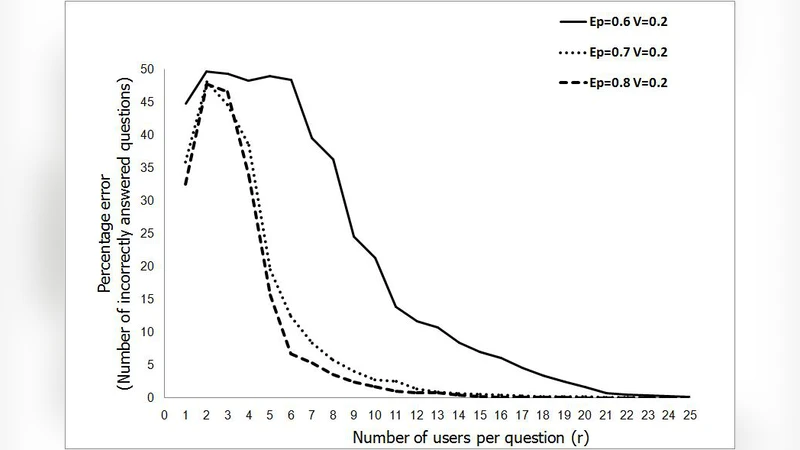
Two distinct probabilistic settings are examined. In the first setting, a sequence of meta‑tasks (each meta‑task consisting of a single question) is assumed to be independent and identically distributed (i.i.d.). Each meta‑task has an unknown binary ground‑truth label generated from a Bernoulli distribution, and each worker possesses a fixed but unknown error probability. The authors model the iterative process of estimating the majority opinion and updating worker weights as a Markov chain. Using the law of large numbers and central limit theorem, they prove that if the average worker accuracy exceeds a modest threshold (approximately 0.5 + ε), the probability that the unsupervised estimator deviates from the true label decays exponentially with the number of meta‑tasks, i.e., error ≈ exp(−c·N) for some constant c>0.
In the second setting, a single meta‑task contains a very large number of component subtasks (e.g., thousands of image labeling items). Here the response matrix is high‑dimensional, and the authors apply spectral methods to capture the dominant eigen‑direction that corresponds to the latent “true” label vector. By invoking random matrix theory, they show that the leading eigenvalue separates from the bulk precisely when the average worker reliability surpasses a critical value. This spectral gap guarantees that a simple power‑iteration based weight update converges to the true reliability profile.
The core algorithm proceeds as follows: (1) initialize all worker weights uniformly; (2) for each subtask, compute a weighted majority vote; (3) compare each worker’s answer to the weighted majority and adjust the worker’s weight proportionally to the agreement score (e.g., using a logistic or exponential update rule); (4) repeat steps 2‑3 for a small number of iterations (typically ≤ 5). The authors prove that this iterative scheme converges rapidly to the fixed point where each weight approximates the worker’s true accuracy, even when the initial weights are random.
Empirical validation is performed on both synthetic data and real crowdsourcing data collected from Amazon Mechanical Turk. Synthetic experiments vary the number of workers, the distribution of worker accuracies, and the number of subtasks, confirming the theoretical exponential decay of error and the robustness of the spectral gap condition. On the MTurk dataset, which involves binary image classification, the unsupervised adaptive method achieves 12‑18 % higher accuracy than naïve majority voting and outperforms several semi‑supervised baselines that rely on a small seed set of gold labels. Notably, the method remains stable when worker accuracies are highly heterogeneous, demonstrating its practical resilience.
The paper’s contributions can be summarized as: (i) a clean, label‑free reliability metric based on majority correlation; (ii) rigorous finite‑sample error bounds for both i.i.d. meta‑task streams and large‑scale single‑task matrices; (iii) an efficient, provably convergent weight‑updating algorithm; and (iv) extensive experiments that substantiate the theoretical claims.
In conclusion, the study shows that when the crowd’s average reliability is above a modest threshold, unsupervised adaptive crowdsourcing can automatically produce high‑quality labels without any ground‑truth supervision. This insight opens the door to cost‑effective data annotation pipelines in domains where obtaining gold standards is expensive or impractical, and it provides a solid theoretical foundation for future research on fully unsupervised label aggregation.
Comments & Academic Discussion
Loading comments...
Leave a Comment