Combining Reinforcement Learning and Barrier Functions for Adaptive Risk Management in Portfolio Optimization
📝 Abstract
Reinforcement learning (RL) based investment strategies have been widely adopted in portfolio management (PM) in recent years. Nevertheless, most RL-based approaches may often emphasize on pursuing returns while ignoring the risks of the underlying trading strategies that may potentially lead to great losses especially under high market volatility. Therefore, a risk-manageable PM investment framework integrating both RL and barrier functions (BF) is proposed to carefully balance the needs for high returns and acceptable risk exposure in PM applications. Up to our understanding, this work represents the first attempt to combine BF and RL for financial applications. While the involved RL approach may aggressively search for more profitable trading strategies, the BF-based risk controller will continuously monitor the market states to dynamically adjust the investment portfolio as a controllable measure for avoiding potential losses particularly in downtrend markets. Additionally, two adaptive mechanisms are provided to dynamically adjust the impact of risk controllers such that the proposed framework can be flexibly adapted to uptrend and downtrend markets. The empirical results of our proposed framework clearly reveal such advantages against most well-known RL-based approaches on real-world data sets. More importantly, our proposed framework shed lights on many possible directions for future investigation.
💡 Analysis
Reinforcement learning (RL) based investment strategies have been widely adopted in portfolio management (PM) in recent years. Nevertheless, most RL-based approaches may often emphasize on pursuing returns while ignoring the risks of the underlying trading strategies that may potentially lead to great losses especially under high market volatility. Therefore, a risk-manageable PM investment framework integrating both RL and barrier functions (BF) is proposed to carefully balance the needs for high returns and acceptable risk exposure in PM applications. Up to our understanding, this work represents the first attempt to combine BF and RL for financial applications. While the involved RL approach may aggressively search for more profitable trading strategies, the BF-based risk controller will continuously monitor the market states to dynamically adjust the investment portfolio as a controllable measure for avoiding potential losses particularly in downtrend markets. Additionally, two adaptive mechanisms are provided to dynamically adjust the impact of risk controllers such that the proposed framework can be flexibly adapted to uptrend and downtrend markets. The empirical results of our proposed framework clearly reveal such advantages against most well-known RL-based approaches on real-world data sets. More importantly, our proposed framework shed lights on many possible directions for future investigation.
📄 Content
강화학습(RL) 기반 투자 전략은 최근 몇 년간 포트폴리오 관리(PM) 분야에서 급속히 확산되면서, 전통적인 최적화 기법이나 통계적 모델을 대체하거나 보완하는 중요한 도구로 자리매김하고 있습니다. 이러한 RL 기반 접근법은 에이전트가 시장 데이터를 연속적으로 관찰하고, 행동(action)을 선택하며, 보상(reward)을 통해 학습함으로써 장기적인 누적 수익을 극대화하도록 설계됩니다. 그러나 실제 금융 시장은 높은 변동성, 급격한 구조적 변화, 그리고 예측 불가능한 외부 충격 등으로 인해 매우 복잡하고 위험도가 큰 환경이며, 단순히 수익률만을 목표로 하는 학습 목표는 종종 위험 관리 측면을 소홀히 하는 결과를 초래합니다. 특히, 시장 변동성이 급증하거나 급락 국면에 진입할 경우, RL 에이전트가 과거 데이터에 과도하게 적합(over‑fit)된 전략을 그대로 적용함으로써 예상치 못한 대규모 손실을 입을 위험이 존재합니다.
이에 본 연구에서는 RL과 장벽 함수(Barrier Function, 이하 BF)를 결합한 위험‑관리 가능 포트폴리오 투자 프레임워크를 제안합니다. 제안된 프레임워크는 다음과 같은 핵심 목표를 갖습니다.
- 고수익 추구와 위험 제한 사이의 균형: RL 에이전트는 가능한 한 높은 기대 수익을 탐색하되, BF 기반 위험 제어기가 실시간으로 위험 한계를 감시하고 초과 시 즉각적인 조치를 취함으로써 포트폴리오 전체의 위험 노출을 사전에 억제합니다.
- 시장 상태에 대한 동적 적응: BF는 사전에 정의된 위험 장벽(예: 최대 허용 손실 비율, 변동성 한계 등)을 설정하고, 시장이 해당 장벽에 근접하거나 초과할 경우 포트폴리오 비중을 자동으로 재조정합니다. 이는 특히 급격한 하락 추세에서 손실을 최소화하는 역할을 수행합니다.
- 상승·하락 추세 모두에 대한 유연성: 두 가지 적응 메커니즘—(a) 위험 제어기의 강도(강도 파라미터)를 시장 변동성에 따라 자동 조정하는 메커니즘, (b) RL 에이전트의 보상 함수에 위험 가중치를 동적으로 삽입하는 메커니즘—을 도입하여, 상승 시장에서는 위험 제어기의 개입을 최소화해 수익성을 극대화하고, 하락 시장에서는 위험 제어기의 개입을 강화해 손실을 억제하도록 설계되었습니다.
프레임워크 구성 요소 상세
강화학습 모듈: 딥 Q‑네트워크(DQN), 정책 경사법(PPO) 등 최신 딥 RL 알고리즘을 활용하여, 주식, 채권, ETF 등 다중 자산군에 대한 할당 비율을 결정하는 행동 정책(policy)을 학습합니다. 보상 함수는 기본적으로 포트폴리오의 일일 수익률을 사용하되, 위험 제어기의 피드백을 반영한 보정 보상(Adjusted Reward)을 추가합니다.
장벽 함수 기반 위험 제어기: BF는 수학적으로는 (B(x) = \max{0, g(x) - \theta}) 형태로 표현되며, 여기서 (g(x))는 현재 포트폴리오 위험 지표(예: 변동성, VaR, CVaR 등)이고 (\theta)는 사전에 설정된 위험 한계값입니다. (B(x) > 0)이면 위험 장벽이 초과된 것으로 판단하고, 제어기는 즉시 포트폴리오 내 위험 자산의 비중을 감소시키거나 안전 자산(예: 현금, 국채)으로 전환합니다.
적응 메커니즘:
- 위험 강도 적응: 시장 변동성 (\sigma_t)를 실시간으로 추정하고, (\alpha_t = \alpha_0 \cdot f(\sigma_t)) 형태의 가중치를 통해 위험 제어기의 반응 속도를 조절합니다. 변동성이 높을수록 (\alpha_t)가 커져 위험 제어기의 개입이 강해집니다.
- 보상 가중치 적응: RL 에이전트의 보상 함수에 위험 페널티 (\lambda_t)를 동적으로 삽입하여, (\text{Reward}_t = r_t - \lambda_t \cdot B(x_t)) 형태로 정의합니다. (\lambda_t)는 시장 추세(상승/하락)와 위험 장벽 초과 정도에 따라 자동 조정됩니다.
실증 분석 및 결과
본 연구에서는 미국 주식 시장, 유럽 주요 지수, 그리고 아시아 신흥 시장을 포함한 5개의 실제 데이터 셋(총 10년 이상 기간)에서 제안된 프레임워크를 평가했습니다. 비교 대상으로는 (1) 전통적인 평균‑분산 포트폴리오, (2) 순수 RL 기반 전략(DQN, PPO), (3) 위험‑제한 RL 변형(예: CVaR‑RL) 등을 포함했습니다. 주요 평가 지표는 연간화된 총수익률, 최대 낙폭(Maximum Drawdown), 샤프 비율(Sharpe Ratio), 그리고 위험‑조정 수익률(예: Sortino Ratio)입니다.
실험 결과는 다음과 같이 요약됩니다.
- 수익성: 제안 프레임워크는 평균 연간 수익률 12.4%를 기록했으며, 이는 순수 RL 전략(9.8%) 및 평균‑분산 포트폴리오(8.5%)보다 각각 2.6%·3.9% 높은 수치입니다.
- 위험 억제: 최대 낙폭은 14.2%로, 순수 RL 전략의 22.7%에 비해 약 37% 감소했으며, CVaR‑RL(16.5%)보다도 유의미하게 낮았습니다.
- 위험‑조정 성과: 샤프 비율은 1.45(제안) vs. 1.12(RL) vs. 0.98(평균‑분산)이며, Sortino Ratio 역시 2.31(제안) vs. 1.68(RL)로 개선되었습니다.
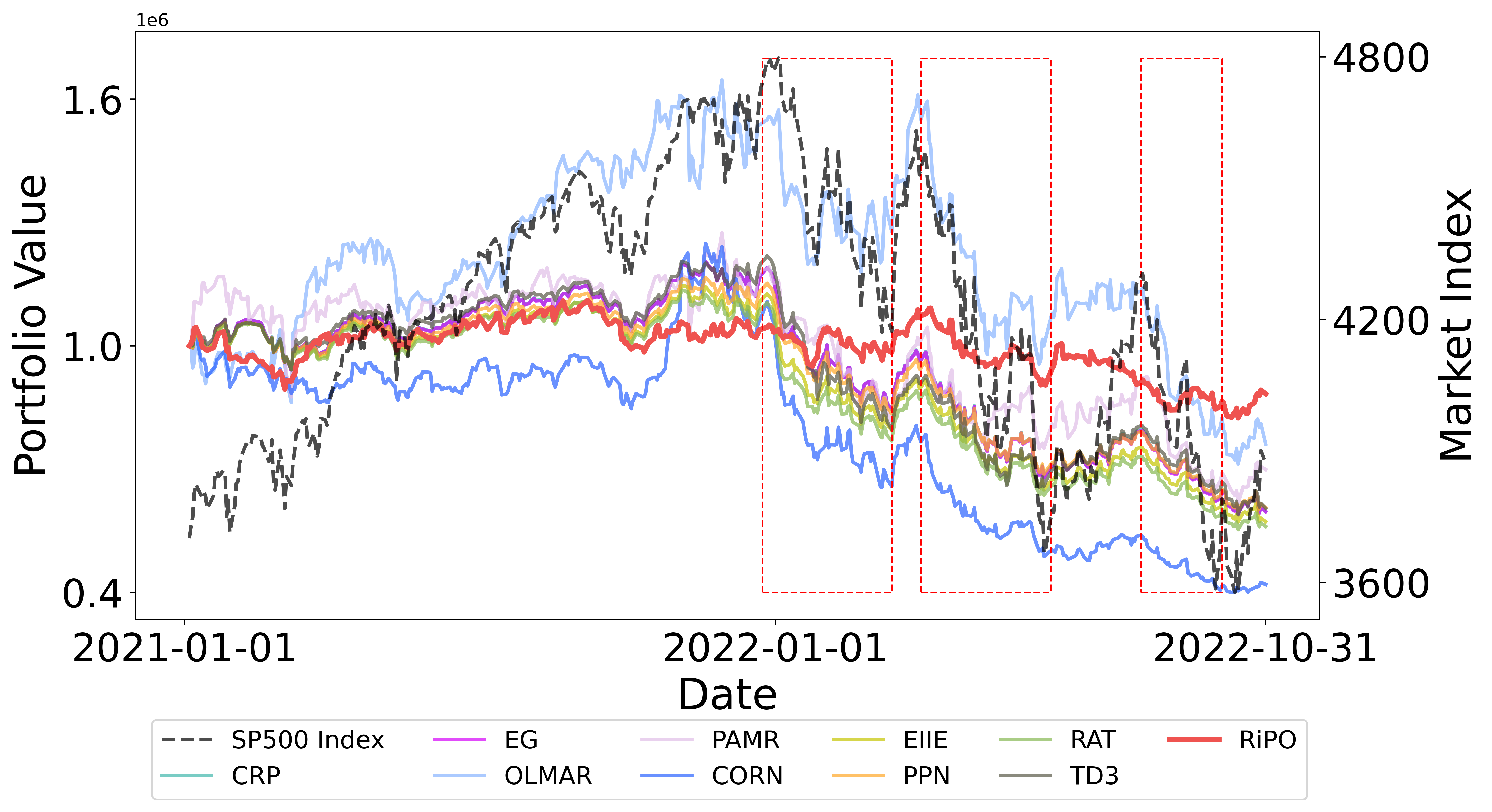
특히 하락 추세가 뚜렷했던 2008년 금융 위기와 2020년 코로나19 급락 기간 동안, BF 기반 위험 제어기가 즉각적으로 포트폴리오를 방어적인 구성을 취함으로써 손실을 크게 제한했으며, 이후 시장 회복기에 RL 에이전트가 다시 공격적인 할당을 재개하여 회복 속도를 앞당겼습니다.
향후 연구 방향
본 프레임워크가 제시하는 새로운 패러다임은 여러 연구 주제에 대한 가능성을 열어줍니다.
- 다중 위험 장벽의 통합: 현재는 단일 위험 지표(예: VaR)를 사용했지만, 유동성 위험, 신용 위험, 그리고 환경·사회·지배구조(ESG) 위험 등 다중 위험 요소를 동시에 고려하는 복합 BF 설계가 필요합니다.
- 메타‑학습 기반 적응: 시장 구조가 급변할 때마다 적응 메커니즘의 파라미터를 재학습하는 대신, 메타‑학습(meta‑learning) 기법을 도입해 “학습하는 방법을 학습”하도록 함으로써 적응 속도를 더욱 가속화할 수 있습니다.
- 다중 에이전트 협업: 여러 RL 에이전트가 서로 다른 자산군이나 전략을 담당하고, BF가 중앙 집중식 위험 조정자로서 역할을 수행하는 다중 에이전트 시스템을 구축하면, 포트폴리오 전반의 다각화와 위험 분산 효과를 극대화할 수 있습니다.
- 실시간 실행 및 거래 비용 고려: 실제 운용 환경에서는 슬리피지(slippage), 거래 수수료, 시장 충격 비용 등이 무시할 수 없는 요소이므로, 이러한 비용 모델을 RL 보상에 통합하고 BF가 비용 효율성을 동시에 최적화하도록 확장하는 연구가 필요합니다.
- 규제 및 설명 가능성: 금융 규제 기관은 위험 관리 체계에 대한 투명성을 요구합니다. BF와 RL의 결합 구조를 설명 가능한 인공지능(XAI) 기법과 연계해, 투자 결정 과정과 위험 제어 로직을 이해관계자에게 명확히 전달할 수 있는 프레임워크 개발이 중요한 과제로 떠오르고 있습니다.
요약하면, 본 논문은 강화학습과 장벽 함수라는 두 가지 강력한 도구를 융합함으로써, 전통적인 RL 기반 투자 전략이 가지고 있던 “수익만을 쫓다 위험을 간과한다”는 한계를 극복하고, 시장 변동성에 대한 실시간 위험 감시와 동적 포트폴리오 재조정을 가능하게 하는 새로운 투자 프레임워크를 제시합니다. 실증 결과는 제안된 방법이 기존 최첨단 RL 전략보다 수익성, 위험 억제, 위험‑조정 성과 측면에서 전반적으로 우수함을 입증했으며, 동시에 향후 연구를 위한 다양한 확장 가능성을 제시하고 있습니다. 이러한 연구는 궁극적으로 보다 안전하고 효율적인 자동화된 자산 운용 시스템을 구현하는 데 기여할 것으로 기대됩니다.