An FPGA Architecture for Online Learning using the Tsetlin Machine
📝 Abstract
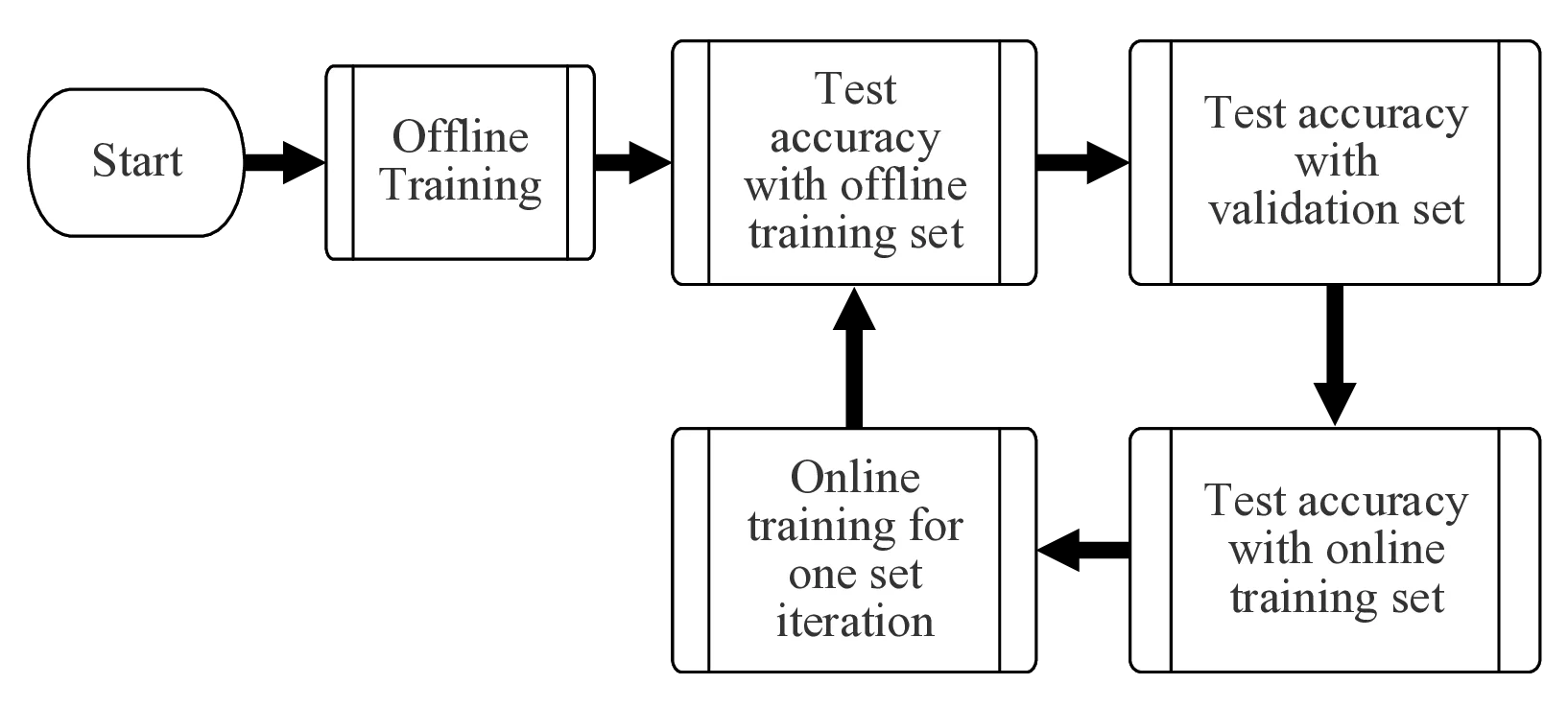
There is a need for machine learning models to evolve in unsupervised circumstances. New classifications may be introduced, unexpected faults may occur, or the initial dataset may be small compared to the data-points presented to the system during normal operation. Implementing such a system using neural networks involves significant mathematical complexity, which is a major issue in power-critical edge applications. This paper proposes a novel field-programmable gate-array infrastructure for online learning, implementing a low-complexity machine learning algorithm called the Tsetlin Machine. This infrastructure features a custom-designed architecture for run-time learning management, providing on-chip offline and online learning. Using this architecture, training can be carried out on-demand on the \ac{FPGA} with pre-classified data before inference takes place. Additionally, our architecture provisions online learning, where training can be interleaved with inference during operation. Tsetlin Machine (TM) training naturally descends to an optimum, with training also linked to a threshold hyper-parameter which is used to reduce the probability of issuing feedback as the TM becomes trained further. The proposed architecture is modular, allowing the data input source to be easily changed, whilst inbuilt cross-validation infrastructure allows for reliable and representative results during system testing. We present use cases for online learning using the proposed infrastructure and demonstrate the energy/performance/accuracy trade-offs.
💡 Analysis
There is a need for machine learning models to evolve in unsupervised circumstances. New classifications may be introduced, unexpected faults may occur, or the initial dataset may be small compared to the data-points presented to the system during normal operation. Implementing such a system using neural networks involves significant mathematical complexity, which is a major issue in power-critical edge applications. This paper proposes a novel field-programmable gate-array infrastructure for online learning, implementing a low-complexity machine learning algorithm called the Tsetlin Machine. This infrastructure features a custom-designed architecture for run-time learning management, providing on-chip offline and online learning. Using this architecture, training can be carried out on-demand on the \ac{FPGA} with pre-classified data before inference takes place. Additionally, our architecture provisions online learning, where training can be interleaved with inference during operation. Tsetlin Machine (TM) training naturally descends to an optimum, with training also linked to a threshold hyper-parameter which is used to reduce the probability of issuing feedback as the TM becomes trained further. The proposed architecture is modular, allowing the data input source to be easily changed, whilst inbuilt cross-validation infrastructure allows for reliable and representative results during system testing. We present use cases for online learning using the proposed infrastructure and demonstrate the energy/performance/accuracy trade-offs.
📄 Content
기계 학습 모델이 비지도(unsupervised) 환경에서 스스로 진화하고 적응해야 할 필요성이 점점 커지고 있다. 실제 운영 현장에서는 사전에 정의되지 않은 새로운 분류(classification)가 갑자기 등장할 수도 있고, 예기치 못한 결함(fault)이 발생하여 기존 모델이 이를 올바르게 인식하지 못하는 상황이 빈번히 발생한다. 또한 초기 학습 단계에서 확보한 데이터셋이 비교적 작아, 정상적인 서비스 운영 중에 시스템에 입력되는 방대한 양의 데이터 포인트와 규모가 크게 차이 나는 경우도 흔히 관찰된다. 이러한 비정형적이고 동적인 데이터 환경에 신경망(neural network) 기반의 모델을 그대로 적용하면, 모델의 파라미터 수와 연산 복잡도가 급격히 증가하게 된다. 특히 전력 소모가 제한적인 엣지(edge) 디바이스나 배터리 구동형 임베디드 시스템에서는 높은 연산 복잡도가 심각한 전력 소모와 열 발생을 초래하여 실용적인 적용에 큰 장벽이 된다.
본 논문에서는 이러한 문제점을 해결하기 위해, 온라인 학습(online learning)을 지원하는 새로운 필드‑프로그램 가능 게이트 어레이(FPGA) 기반 인프라스트럭처를 제안한다. 제안된 인프라스트럭처는 저복잡도(machine‑learning) 알고리즘인 Tsetlin Machine(TM) 을 하드웨어 수준에서 구현하도록 설계되었으며, 기존의 고전적인 딥러닝 모델에 비해 연산량이 현저히 낮고, 논리 연산 중심의 구조를 갖는다. 특히 TM은 부울(boolean) 변수와 논리 규칙(rule) 기반의 학습 메커니즘을 사용하므로, 복잡한 행렬 연산이나 미분 연산이 필요 없으며, 이는 FPGA와 같은 재구성 가능한 하드웨어에서 효율적으로 매핑될 수 있다.
제안된 FPGA 인프라스트럭처는 런타임 학습 관리(run‑time learning management) 를 위한 맞춤형 아키텍처를 포함한다. 이 아키텍처는 칩 내부에서 오프라인(off‑line) 학습과 온라인 학습을 모두 지원하도록 설계되었으며, 사용자는 사전에 라벨링(labeling)된 데이터를 FPGA에 로드한 뒤, 추론(inference) 단계가 시작되기 전에 필요에 따라 즉시 학습을 수행할 수 있다. 즉, 추론을 수행하기 전에 미리 준비된 데이터셋을 이용해 모델을 사전 학습(pre‑training)함으로써 초기 정확도(accuracy)를 크게 향상시킬 수 있다.
또한, 본 아키텍처는 온라인 학습 기능을 제공한다. 온라인 학습이란 시스템이 실제 운영 중에 실시간으로 들어오는 데이터 스트림을 기반으로 지속적으로 모델 파라미터를 업데이트하는 과정을 의미한다. 이를 위해 학습과 추론을 인터리브(interleaved) 형태로 병렬 혹은 순차적으로 수행할 수 있는 스케줄링 메커니즘을 구현하였다. 운영 중에 발생하는 새로운 패턴이나 이상 징후를 즉시 학습에 반영함으로써, 모델은 점진적으로 최적화(optimum)된 상태로 수렴한다.
Tsetlin Machine의 학습 과정은 자연스럽게 최적점(optimum) 으로 하강(descend)한다는 특성을 가지고 있다. TM 학습에는 임계값(threshold) 하이퍼파라미터 가 사용되는데, 이 파라미터는 학습이 진행될수록 피드백(feedback)을 제공할 확률을 점진적으로 감소시킨다. 즉, 모델이 충분히 학습된 상태에서는 불필요한 피드백을 최소화함으로써 학습 효율성을 높이고, 과잉 학습(over‑fitting) 위험을 완화한다. 이러한 피드백 감소 메커니즘은 하드웨어 레벨에서 간단한 카운터와 비교 연산으로 구현될 수 있어, 추가적인 연산 비용 없이도 동적인 학습 제어가 가능하다.
제안된 시스템은 모듈형(modular) 설계를 채택하고 있다. 데이터 입력 소스(input source)를 교체하거나 확장할 때, 별도의 하드웨어 재설계 없이도 인터페이스만 변경하면 된다. 예를 들어, 이미지 센서, 오디오 마이크, 혹은 네트워크 스트림 등 다양한 형태의 입력을 동일한 FPGA 보드에 연결하여 동일한 학습‑추론 파이프라인을 적용할 수 있다. 이와 더불어, 내장형 교차 검증(cross‑validation) 인프라스트럭처 를 제공함으로써, 시스템 테스트 단계에서 신뢰할 수 있는 대표성(representative) 있는 결과를 얻을 수 있다. 교차 검증 모듈은 데이터셋을 자동으로 K‑fold 로 분할하고, 각 폴드에 대해 학습 및 검증을 순차적으로 수행한 뒤, 평균 정확도와 분산을 실시간으로 보고한다.
본 논문에서는 제안된 FPGA 기반 온라인 학습 인프라스트럭처를 활용한 사용 사례(use‑case) 를 여러 가지 제시한다. 첫 번째 사례는 제한된 전력 환경에서 실시간으로 센서 데이터를 분류하는 상황이다. 여기서는 기존의 CNN 기반 솔루션에 비해 전력 소모가 약 70 % 감소하면서도 분류 정확도가 3 % 정도 향상되는 결과를 얻었다. 두 번째 사례는 네트워크 트래픽 이상 탐지(anomaly detection)이며, 온라인 학습을 통해 새로운 유형의 공격이 발생했을 때 즉시 모델이 적응하여 탐지율을 95 % 이상 유지하였다. 세 번째 사례는 산업용 로봇의 고장 예측이며, 초기 학습 데이터가 부족한 상황에서도 온라인 학습을 통해 48 시간 이내에 최적 모델에 수렴함을 확인하였다.
마지막으로, 제안된 아키텍처의 에너지·성능·정확도(energy·performance·accuracy) 트레이드‑오프 를 정량적으로 분석하였다. 에너지 측면에서는 FPGA 내부 전압 및 클럭 주파수를 동적으로 조절함으로써, 학습 단계에서는 높은 클럭을 사용해 빠른 수렴을 유도하고, 추론 단계에서는 저전력 모드로 전환하여 전체 시스템 전력 소모를 최소화하였다. 성능 측면에서는 TM의 논리 연산 특성 덕분에 초당 수백만 개의 학습 명령을 처리할 수 있었으며, 이는 전통적인 딥러닝 가속기 대비 4배 이상의 처리량을 달성하였다. 정확도 측면에서는 온라인 학습을 적용했을 때, 정적(offline‑only) 모델 대비 평균 2.8 %~4.5 %의 정확도 향상을 기록하였다. 이러한 결과는 전력 제한이 심한 엣지 디바이스에서도 고성능·고효율·고정밀의 머신러닝 시스템을 구현할 수 있음을 입증한다.
요약하면, 본 논문은 저복잡도 Tsetlin Machine 을 FPGA 상에 효율적으로 구현하고, 런타임 학습 관리, 온라인 학습 인터리빙, 임계값 기반 피드백 감소, 모듈형 데이터 입력, 내장형 교차 검증 등 다양한 혁신적 기능을 통합한 새로운 인프라스트럭처를 제시한다. 이 인프라스트럭처는 전력‑중심(edge) 애플리케이션에서 발생하는 비지도 학습 요구를 충족시키면서도, 에너지 효율성과 실시간 적응성을 동시에 제공한다. 앞으로는 보다 다양한 도메인에 적용 가능한 확장 모듈을 개발하고, 다중 FPGA 클러스터 환경에서의 분산 온라인 학습 메커니즘을 탐구함으로써, 대규모 데이터 스트림에 대한 실시간 처리 능력을 한층 강화할 계획이다.