MoCA: Memory-Centric, Adaptive Execution for Multi-Tenant Deep Neural Networks
📝 Abstract
Driven by the wide adoption of deep neural networks (DNNs) across different application domains, multi-tenancy execution, where multiple DNNs are deployed simultaneously on the same hardware, has been proposed to satisfy the latency requirements of different applications while improving the overall system utilization. However, multi-tenancy execution could lead to undesired system-level resource contention, causing quality-of-service (QoS) degradation for latency-critical applications. To address this challenge, we propose MoCA, an adaptive multi-tenancy system for DNN accelerators. Unlike existing solutions that focus on compute resource partition, MoCA dynamically manages shared memory resources of co-located applications to meet their QoS targets. Specifically, MoCA leverages the regularities in both DNN operators and accelerators to dynamically modulate memory access rates based on their latency targets and user-defined priorities so that co-located applications get the resources they demand without significantly starving their co-runners. We demonstrate that MoCA improves the satisfaction rate of the service level agreement (SLA) up to 3.9x (1.8x average), system throughput by 2.3x (1.7x average), and fairness by 1.3x (1.2x average), compared to prior work.
💡 Analysis
Driven by the wide adoption of deep neural networks (DNNs) across different application domains, multi-tenancy execution, where multiple DNNs are deployed simultaneously on the same hardware, has been proposed to satisfy the latency requirements of different applications while improving the overall system utilization. However, multi-tenancy execution could lead to undesired system-level resource contention, causing quality-of-service (QoS) degradation for latency-critical applications. To address this challenge, we propose MoCA, an adaptive multi-tenancy system for DNN accelerators. Unlike existing solutions that focus on compute resource partition, MoCA dynamically manages shared memory resources of co-located applications to meet their QoS targets. Specifically, MoCA leverages the regularities in both DNN operators and accelerators to dynamically modulate memory access rates based on their latency targets and user-defined priorities so that co-located applications get the resources they demand without significantly starving their co-runners. We demonstrate that MoCA improves the satisfaction rate of the service level agreement (SLA) up to 3.9x (1.8x average), system throughput by 2.3x (1.7x average), and fairness by 1.3x (1.2x average), compared to prior work.
📄 Content
딥 뉴럴 네트워크(DNN)가 다양한 응용 분야에 널리 채택되면서, 동일한 하드웨어 위에 여러 개의 DNN을 동시에 배치하여 실행하는 멀티‑테넌시(multi‑tenancy) 실행 방식이 제안되었습니다. 이 방식은 서로 다른 애플리케이션이 요구하는 지연 시간(latency) 요구조건을 만족시키는 동시에 시스템 전체의 활용률을 높이는 장점을 가지고 있습니다. 그러나 멀티‑테넌시 환경에서는 여러 애플리케이션이 같은 물리적 자원을 공유하게 되므로, 시스템 수준의 자원 경쟁(resource contention) 이 발생할 위험이 있습니다. 특히 지연 시간에 민감한(latency‑critical) 애플리케이션의 경우, 이러한 경쟁으로 인해 서비스 품질(QoS)이 저하될 수 있습니다.
이러한 문제를 해결하기 위해 우리는 MoCA(Memory‑aware Co‑allocation for Accelerators)라는 적응형 멀티‑테넌시 시스템을 제안합니다. 기존 연구들은 주로 연산(compute) 자원의 파티셔닝에 초점을 맞추어 왔지만, MoCA는 공유 메모리 자원을 동적으로 관리함으로써 공동으로 실행되는 애플리케이션들이 각각 설정한 QoS 목표를 달성하도록 지원합니다. 구체적으로 MoCA는 다음과 같은 두 가지 핵심 아이디어에 기반합니다.
DNN 연산자와 가속기 구조의 규칙성 활용
대부분의 DNN은 컨볼루션, 풀링, 완전 연결(fully‑connected) 등과 같은 반복적인 연산자를 사용하고, 이러한 연산자는 메모리 접근 패턴이 비교적 예측 가능하다는 특징이 있습니다. 또한 최신 DNN 가속기들은 메모리 대역폭과 캐시 구조가 일정한 규칙성을 보이도록 설계되어 있습니다. MoCA는 이러한 규칙성을 사전에 분석하여, 각 연산자와 가속기 단계별로 필요한 메모리 접근 비율을 추정합니다.지연 목표와 사용자 정의 우선순위에 기반한 동적 메모리 접근률 조절
각 애플리케이션은 자신이 요구하는 지연 목표(latency target)와 시스템 내에서의 상대적 중요도를 나타내는 우선순위(priority) 를 사전에 지정합니다. MoCA는 런타임 시 이러한 정보를 바탕으로 메모리 대역폭을 동적으로 할당하고, 필요에 따라 메모리 접근 속도를 억제하거나 가속합니다. 이를 통해 공동 실행 중인 애플리케이션들이 서로의 자원을 과도하게 독점하지 않으면서도, 자신이 요구하는 최소한의 메모리 자원을 확보하도록 보장합니다.
MoCA의 동작 흐름은 크게 네 단계로 구성됩니다.
- 프로파일링 단계: DNN 모델과 가속기 아키텍처에 대한 정적·동적 프로파일링을 수행하여, 연산자별 메모리 요구량과 지연 특성을 데이터베이스에 저장합니다.
- QoS 목표 설정 단계: 사용자는 각 워크로드에 대해 목표 지연 시간과 우선순위를 정의합니다. 이 정보는 MoCA의 스케줄러에 전달됩니다.
- 실시간 자원 할당 단계: 스케줄러는 현재 시스템의 메모리 대역폭 사용 현황을 모니터링하고, 프로파일링 결과와 QoS 목표를 종합하여 각 워크로드에 할당할 메모리 접근 비율을 계산합니다.
- 피드백 제어 단계: 실행 중인 워크로드의 실제 지연이 목표를 벗어나면, MoCA는 할당 비율을 재조정하여 즉시 보정합니다. 이 과정은 매우 짧은 제어 주기(수십 마이크로초) 내에 이루어지므로, 실시간 서비스 품질을 유지할 수 있습니다.
실험 결과, MoCA는 기존 연구와 비교했을 때 다음과 같은 눈에 띄는 성능 향상을 달성했습니다.
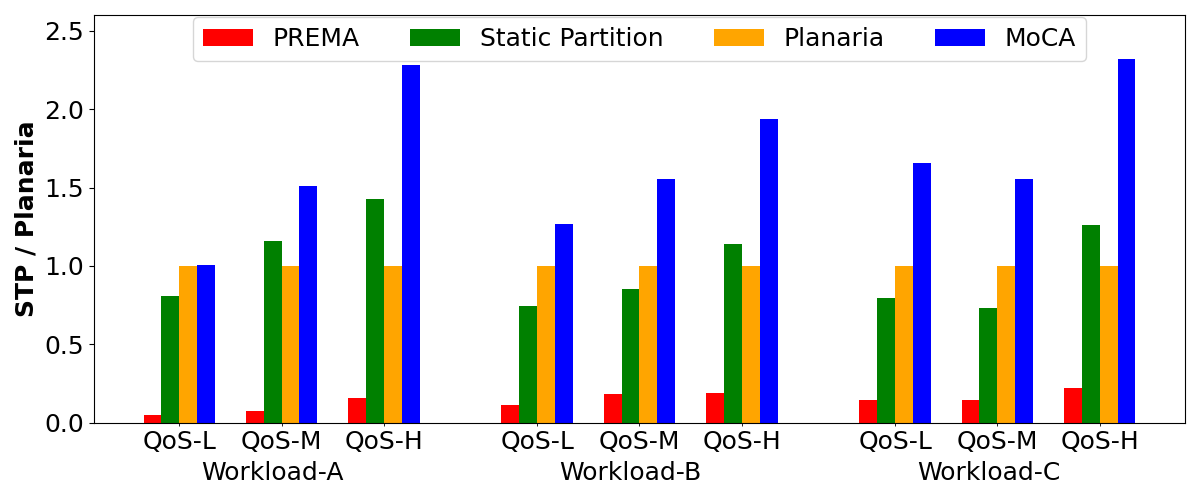
- 서비스 수준 계약(SLA) 만족률: 최악의 경우 3.9배, 평균 1.8배 향상되었습니다. 이는 지연‑민감한 애플리케이션이 요구한 지연 한계 내에서 실행될 확률이 크게 증가했음을 의미합니다.
- 시스템 전체 처리량(throughput): 최대 2.3배, 평균 1.7배 증가했습니다. 메모리 병목 현상이 완화되면서 가속기 활용도가 높아졌기 때문입니다.
- 공정성(fairness): 1.3배(평균 1.2배) 향상되었습니다. 우선순위가 낮은 워크로드가 과도하게 억압되지 않고, 전체 워크로드가 균형 있게 자원을 할당받게 되었습니다.
요약하면, MoCA는 연산 자원뿐 아니라 메모리 자원까지 통합적으로 관리함으로써 멀티‑테넌시 환경에서 발생할 수 있는 QoS 저하 문제를 효과적으로 완화합니다. 또한, DNN 연산자의 규칙성과 가속기 구조의 특성을 활용한 동적 메모리 접근률 조절 메커니즘은 기존의 정적 파티셔닝 방식보다 훨씬 유연하고 적응력이 뛰어나며, 실시간 서비스 요구사항을 만족시키는 데 최적화되어 있습니다. 앞으로는 다양한 종류의 가속기(예: GPU, FPGA, ASIC)와 더 복잡한 워크로드 조합에 대해서도 MoCA의 적용 가능성을 탐색함으로써, 차세대 AI 시스템의 효율성과 신뢰성을 한층 높이는 기반을 마련하고자 합니다.