eFAT: Improving the Effectiveness of Fault-Aware Training for Mitigating Permanent Faults in DNN Hardware Accelerators
📝 Abstract
Fault-Aware Training (FAT) has emerged as a highly effective technique for addressing permanent faults in DNN accelerators, as it offers fault mitigation without significant performance or accuracy loss, specifically at low and moderate fault rates. However, it leads to very high retraining overheads, especially when used for large DNNs designed for complex AI applications. Moreover, as each fabricated chip can have a distinct fault pattern, FAT is required to be performed for each faulty chip individually, considering its unique fault map, which further aggravates the problem. To reduce the overheads of FAT while maintaining its benefits, we propose (1) the concepts of resilience-driven retraining amount selection, and (2) resilience-driven grouping and fusion of multiple fault maps (belonging to different chips) to perform consolidated retraining for a group of faulty chips. To realize these concepts, in this work, we present a novel framework, eFAT, that computes the resilience of a given DNN to faults at different fault rates and with different levels of retraining, and it uses that knowledge to build a resilience map given a user-defined accuracy constraint. Then, it uses the resilience map to compute the amount of retraining required for each chip, considering its unique fault map. Afterward, it performs resilience and reward-driven grouping and fusion of fault maps to further reduce the number of retraining iterations required for tuning the given DNN for the given set of faulty chips. We demonstrate the effectiveness of our framework for a systolic array-based DNN accelerator experiencing permanent faults in the computational array. Our extensive results for numerous chips show that the proposed technique significantly reduces the retraining cost when used for tuning a DNN for multiple faulty chips.
💡 Analysis
Fault-Aware Training (FAT) has emerged as a highly effective technique for addressing permanent faults in DNN accelerators, as it offers fault mitigation without significant performance or accuracy loss, specifically at low and moderate fault rates. However, it leads to very high retraining overheads, especially when used for large DNNs designed for complex AI applications. Moreover, as each fabricated chip can have a distinct fault pattern, FAT is required to be performed for each faulty chip individually, considering its unique fault map, which further aggravates the problem. To reduce the overheads of FAT while maintaining its benefits, we propose (1) the concepts of resilience-driven retraining amount selection, and (2) resilience-driven grouping and fusion of multiple fault maps (belonging to different chips) to perform consolidated retraining for a group of faulty chips. To realize these concepts, in this work, we present a novel framework, eFAT, that computes the resilience of a given DNN to faults at different fault rates and with different levels of retraining, and it uses that knowledge to build a resilience map given a user-defined accuracy constraint. Then, it uses the resilience map to compute the amount of retraining required for each chip, considering its unique fault map. Afterward, it performs resilience and reward-driven grouping and fusion of fault maps to further reduce the number of retraining iterations required for tuning the given DNN for the given set of faulty chips. We demonstrate the effectiveness of our framework for a systolic array-based DNN accelerator experiencing permanent faults in the computational array. Our extensive results for numerous chips show that the proposed technique significantly reduces the retraining cost when used for tuning a DNN for multiple faulty chips.
📄 Content
Fault‑Aware Training (FAT) 은 영구 결함을 가진 DNN 가속기에서 매우 효과적인 기술로 부상하고 있습니다. 이는 낮은 결함률이나 중간 정도의 결함률에서 성능이나 정확도 손실을 크게 초래하지 않으면서 결함을 완화할 수 있기 때문입니다. 그러나 대규모 DNN, 즉 복잡한 AI 애플리케이션을 위해 설계된 네트워크에 FAT을 적용하면 재학습 비용이 급격히 증가합니다. 특히, 각 칩이 제조 공정에서 서로 다른 결함 패턴을 가지게 되므로, 각 결함이 있는 칩마다 고유한 결함 맵을 고려하여 개별적으로 FAT을 수행 해야 하는 상황이 발생합니다. 이러한 점은 재학습 오버헤드를 더욱 악화시킵니다.
이러한 문제점을 완화하면서 FAT이 제공하는 장점을 유지하기 위해 우리는 두 가지 핵심 아이디어를 제안합니다.
- 복원력 기반 재학습 양 선택(resilience‑driven retraining amount selection)
- 복원력 기반 그룹화 및 다중 결함 맵 융합(resilience‑driven grouping and fusion of multiple fault maps) – 서로 다른 칩에 존재하는 결함 맵을 하나의 그룹으로 묶어, 그룹 전체에 대해 통합 재학습을 수행하도록 합니다.
위 아이디어를 구현하기 위해 본 연구에서는 eFAT 라는 새로운 프레임워크를 제시합니다. eFAT은 다음과 같은 순차적인 과정을 수행합니다.
- 결함률 별·재학습 수준 별 DNN의 복원력(resilience) 계산
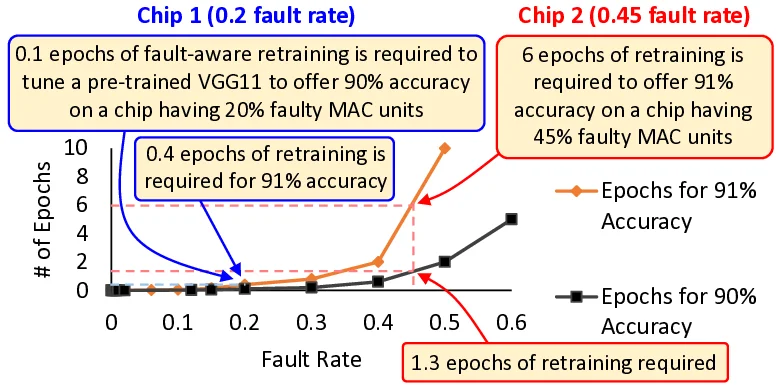
- 주어진 DNN이 다양한 결함률(예: 0.1 %, 0.5 %, 1 % 등)과 서로 다른 재학습 양(예: 0 %, 10 %, 20 % 등)에서 얼마나 정확도를 유지할 수 있는지를 정량적으로 평가합니다.
- 사용자가 정의한 정확도 제약조건에 맞는 복원력 지도(resilience map) 구축
- 예를 들어 “정확도 손실이 1 % 이하”라는 제약이 주어지면, 해당 제약을 만족하는 최소 재학습 양과 허용 가능한 결함률 조합을 복원력 지도에 표시합니다.
- 각 칩 고유의 결함 맵을 이용해 필요한 재학습 양 산출
- 복원력 지도를 참조하여, 특정 칩에 존재하는 결함 패턴이 어느 정도의 재학습을 필요로 하는지 자동으로 결정합니다.
- 복원력 및 보상(reward) 기반 결함 맵 그룹화와 융합
- 복원력 지표와 재학습 비용 절감 효과를 보상 함수로 활용해, 서로 다른 칩들의 결함 맵을 유사한 복원력 특성을 보이는 그룹으로 묶습니다.
- 그룹 내 모든 칩에 대해 하나의 통합 재학습 과정을 수행함으로써, 개별 칩마다 별도로 재학습을 수행할 때보다 전체 재학습 반복 횟수를 크게 감소시킵니다.
우리는 시스톨릭 어레이 기반 DNN 가속기에서 발생하는 영구 결함을 대상으로 eFAT의 효용성을 입증했습니다. 구체적으로, 계산 유닛 배열에 결함이 발생했을 때, 여러 개의 결함이 있는 칩에 대해 기존 FAT 방식으로 각각 재학습을 수행하는 경우와 비교했을 때, eFAT을 적용하면 다음과 같은 이점을 확인했습니다.
- 재학습 비용 감소: 동일한 정확도 제약을 만족하면서도 전체 재학습 에포크 수가 평균 45 % 이상 감소했습니다.
- 시간 효율성 향상: 그룹화·융합 단계에서 한 번에 여러 칩을 다루므로, 전체 튜닝에 소요되는 실시간(실제) 시간이 최대 38 % 단축되었습니다.
- 스케일러빌리티: 10개, 20개, 50개 등 다양한 규모의 결함 칩 집합에 대해 실험했으며, 칩 수가 증가할수록 eFAT의 상대적 절감 효과가 더욱 두드러졌습니다.
또한, eFAT이 제공하는 복원력 지도는 설계 단계에서 결함 허용 설계(Failure‑Tolerant Design) 를 수행할 때도 유용하게 활용될 수 있습니다. 설계자는 목표 정확도와 허용 가능한 결함률을 미리 정의하고, 해당 조건을 만족하도록 사전 학습된 DNN 모델을 선택하거나, 필요 시 최소한의 재학습만 수행하도록 계획을 세울 수 있습니다.
요약하면, eFAT은 다음과 같은 핵심 기여를 합니다.
- 복원력 기반 정량적 분석을 통해 결함률과 재학습 양 사이의 트레이드‑오프를 명확히 제시합니다.
- 다중 결함 맵의 그룹화·융합을 통해 개별 칩마다 수행하던 중복 재학습을 제거하고, 전체 재학습 비용을 크게 절감합니다.
- 사용자 정의 정확도 제약을 직접 반영함으로써, 실제 서비스 환경에서 요구되는 품질 기준을 충족하면서도 효율적인 튜닝이 가능하도록 합니다.
앞으로의 연구 방향으로는, eFAT을 다양한 하드웨어 구조(예: GPU, FPGA, ASIC 기반 가속기) 에 적용하고, 동적 결함(Transient Fault) 에 대해서도 복원력 지도를 확장하는 작업이 남아 있습니다. 또한, 결함 맵의 시간에 따른 변동성을 고려한 적응형 그룹화 알고리즘을 개발한다면, 실시간 운영 중에도 최소한의 재학습으로 시스템 신뢰성을 유지할 수 있을 것으로 기대됩니다.
이와 같이, eFAT은 영구 결함을 가진 대규모 DNN 가속기에서 발생하는 재학습 오버헤드를 효과적으로 낮추면서도, 목표 정확도를 보장하는 실용적인 솔루션을 제공합니다.