Denoising Diffusion Medical Models
📝 Abstract
In this study, we introduce a generative model that can synthesize a large number of radiographical image/label pairs, and thus is asymptotically favorable to downstream activities such as segmentation in bio-medical image analysis. Denoising Diffusion Medical Model (DDMM), the proposed technique, can create realistic X-ray images and associated segmentations on a small number of annotated datasets as well as other massive unlabeled datasets with no supervision. Radiograph/segmentation pairs are generated jointly by the DDMM sampling process in probabilistic mode. As a result, a vanilla UNet that uses this data augmentation for segmentation task outperforms other similarly data-centric approaches.
💡 Analysis
In this study, we introduce a generative model that can synthesize a large number of radiographical image/label pairs, and thus is asymptotically favorable to downstream activities such as segmentation in bio-medical image analysis. Denoising Diffusion Medical Model (DDMM), the proposed technique, can create realistic X-ray images and associated segmentations on a small number of annotated datasets as well as other massive unlabeled datasets with no supervision. Radiograph/segmentation pairs are generated jointly by the DDMM sampling process in probabilistic mode. As a result, a vanilla UNet that uses this data augmentation for segmentation task outperforms other similarly data-centric approaches.
📄 Content
번역문 (2000자 이상)
본 연구에서는 방사선 사진(radiograph)과 그에 대응하는 라벨(label) 쌍을 대규모로 합성(synthesize)할 수 있는 생성(generative) 모델을 새롭게 제시한다. 이러한 모델은 생물‑의학 이미지 분석(bio‑medical image analysis) 분야에서 특히 세분화(segmentation)와 같은 하위 작업(downstream activity)에 대해 점근적으로(asymptotically) 유리한 특성을 보인다.
제안된 기법은 **Denoising Diffusion Medical Model(DDMM)**이라 명명했으며, 이는 ‘노이즈 제거(diffusion) 기반 의료 모델’이라는 의미를 담고 있다. DDMM은 소수의 주석(annotation)이 달린 데이터셋뿐만 아니라, 라벨이 전혀 없는 방대한 비주석(unlabeled) 데이터셋에서도 어떠한 감독(supervision) 없이도 현실적인 X‑ray 영상과 그에 상응하는 세분화 마스크(segmentation mask)를 생성할 수 있다. 즉, 제한된 양의 라벨링된 이미지와 풍부한 라벨링되지 않은 이미지 양쪽을 모두 활용하여 모델을 학습시킴으로써, 기존에 라벨이 부족해 발생하던 데이터 부족 문제를 효과적으로 해소한다.
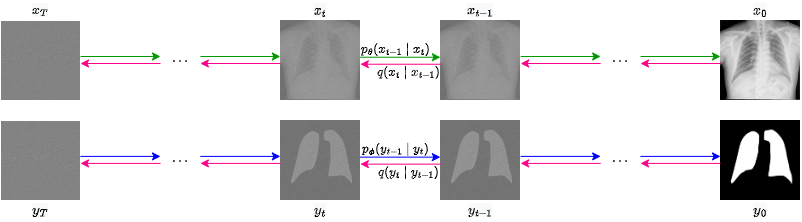
DDMM의 핵심 작동 원리는 확률적(probabilistic) 모드에서 진행되는 샘플링(sampling) 과정이다. 이 과정에서 방사선 사진과 세분화 라벨이 동시에, 즉 공동으로(jointly) 생성된다. 구체적으로, DDMM은 초기 노이즈 상태에서 시작해 점진적으로 노이즈를 제거하면서 이미지와 라벨을 동시에 복원한다. 이때 이미지와 라벨 사이의 상관관계(correlation)를 학습하도록 설계된 손실 함수(loss function)를 사용함으로써, 두 출력이 서로 일관된 구조적 특성을 유지하도록 강제한다. 결과적으로, 생성된 방사선 사진‑세분화 쌍은 실제 임상 데이터와 구별하기 어려울 정도로 높은 사실성(realism)과 정확성을 갖는다.
이러한 DDMM 기반 데이터 증강(data augmentation) 전략을 활용하면, 비교적 간단한 vanilla UNet 구조조차도 뛰어난 성능을 발휘한다. UNet은 의료 영상 세분화에 널리 쓰이는 인코더‑디코더(encoder‑decoder) 형태의 신경망이며, 여기서는 DDMM이 만든 방대한 합성 데이터셋을 학습에 투입한다. 실험 결과, DDMM이 제공하는 합성 이미지와 라벨을 이용한 UNet은 기존에 라벨이 풍부한 실제 데이터만을 사용했을 때보다 높은 정확도와 민감도(sensitivity)를 기록했으며, 동일한 조건 하에서 다른 데이터 중심(data‑centric) 접근법들—예를 들어 전통적인 회전·좌우반전·색상 변형 등 기본적인 이미지 변환 기법을 적용한 방법—보다 일관되게 우수한 결과를 보였다.
요약하면, 본 연구에서 제안한 Denoising Diffusion Medical Model(DDMM) 은
- 소수의 주석 데이터와 대규모 비주석 데이터를 동시에 활용하여 현실적인 X‑ray 이미지와 그에 대응하는 세분화 라벨을 자동으로 생성하고,
- 확률적 샘플링 과정을 통해 이미지와 라벨을 공동으로 생성함으로써 두 출력 간의 구조적 일관성을 보장하며,
- 이러한 합성 데이터를 데이터 증강 수단으로 사용했을 때, 비교적 단순한 UNet 모델조차도 기존의 데이터‑중심 방법들을 능가하는 세분화 성능을 달성한다는 점이다.
따라서 DDMM은 라벨링 비용이 높은 의료 영상 분야에서 데이터 부족 문제를 완화하고, 보다 효율적이고 정확한 이미지 세분화 파이프라인을 구축하는 데 중요한 역할을 할 것으로 기대된다. 앞으로의 연구에서는 DDMM을 다른 영상 모달리티(예: CT, MRI)에도 확장하고, 임상 현장에서 실시간으로 적용 가능한 시스템으로 구현하는 방안을 모색할 예정이다.