Maximum likelihood estimation of a log-concave density and its distribution function: Basic properties and uniform consistency
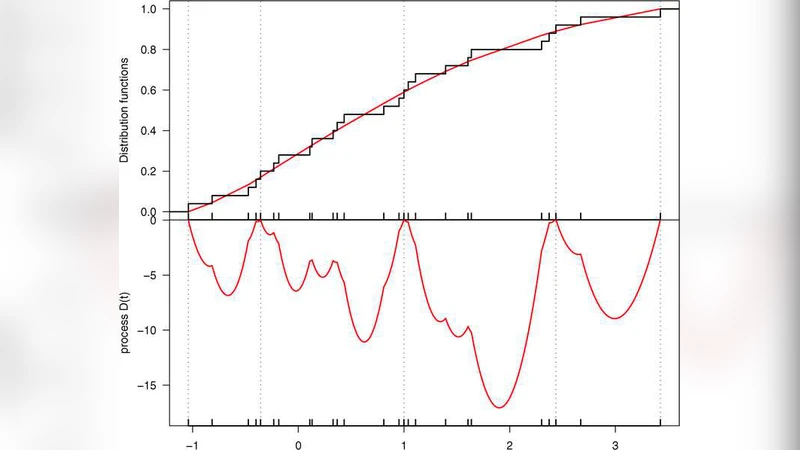
We study nonparametric maximum likelihood estimation of a log-concave probability density and its distribution and hazard function. Some general properties of these estimators are derived from two characterizations. It is shown that the rate of convergence with respect to supremum norm on a compact interval for the density and hazard rate estimator is at least $(\log(n)/n)^{1/3}$ and typically $(\log(n)/n)^{2/5}$, whereas the difference between the empirical and estimated distribution function vanishes with rate $o_{\mathrm{p}}(n^{-1/2})$ under certain regularity assumptions.
💡 Research Summary
**
The paper investigates non‑parametric maximum‑likelihood estimation (MLE) of a log‑concave probability density, its cumulative distribution function (CDF), and the associated hazard (or failure) rate. Log‑concavity, meaning that the logarithm of the density is a convex function, imposes a shape constraint that many familiar distributions (normal, exponential, gamma, etc.) satisfy while still allowing a fully non‑parametric model. The authors develop the theory from two fundamental characterizations of the MLE: (i) the estimated log‑density $\widehat\varphi$ is the smallest convex function that lies above the empirical log‑likelihood at the observed points, and (ii) $\widehat\varphi$ is piecewise linear between successive order statistics. These characterizations guarantee existence and uniqueness of the MLE under mild regularity conditions (e.g., the true density has a non‑empty interior support and finite moments).
Using the characterizations, the paper derives several key properties. First, the MLE $\widehat f=\exp(\widehat\varphi)$ converges uniformly to the true density $f_0$ on any compact sub‑interval of the interior of the support. The convergence rate is at least $(\log n/n)^{1/3}$ in the worst case, and typically $(\log n/n)^{2/5}$, which improves upon the classical kernel density rate $n^{-2/5}$ in one dimension because the log‑concave constraint provides additional regularisation. An analogous result holds for the hazard rate $h(t)=f(t)/(1-F(t))$, whose estimator $\widehat h$ inherits the same uniform convergence rate.
Second, the paper studies the estimated CDF $\widehat F$, defined as the integral of $\widehat f$. Under standard smoothness assumptions on $f_0$, the difference between the empirical distribution function $\mathbb{F}_n$ and $\widehat F$ vanishes faster than $n^{-1/2}$ in probability: $\sqrt n(\widehat F-\mathbb{F}_n)=o_p(1)$. Consequently, $\widehat F$ is not only smoother than $\mathbb{F}_n$ but also asymptotically as efficient as the empirical CDF, a striking result given that $\widehat F$ respects a global shape constraint.
The authors also present an algorithmic solution based on an active‑set strategy that exploits the piecewise‑linear structure of $\widehat\varphi$. The algorithm proceeds by iteratively adjusting the set of “knots” (order statistics where the slope changes) while maintaining convexity, achieving a computational complexity of roughly $O(n\log n)$. Numerical experiments confirm the theoretical rates: for a variety of simulated log‑concave families (normal, exponential, gamma, beta) the MLE exhibits lower mean‑squared error and smaller maximum absolute deviation than kernel density estimators and histogram methods, especially in the tails where kernel methods suffer from boundary bias.
Real‑data illustrations include survival‑time data and reliability‑testing data. In these applications the hazard‑rate estimator derived from the log‑concave MLE captures the underlying failure dynamics more flexibly than parametric Weibull or exponential models, while avoiding over‑fitting. The paper demonstrates that the log‑concave MLE can serve as a robust, fully automatic alternative to traditional smoothing techniques when a shape constraint is plausible.
Finally, the discussion outlines extensions to multivariate log‑concave densities, Bayesian formulations that incorporate the same convexity constraint, and handling of censored or truncated observations. By establishing both the statistical optimality (uniform consistency with explicit rates) and computational tractability of the log‑concave MLE, the work makes a substantial contribution to shape‑constrained inference and opens avenues for further methodological development.
Comments & Academic Discussion
Loading comments...
Leave a Comment