Remote Procedure Call as a Managed System Service
📝 Abstract
Remote Procedure Call (RPC) is a widely used abstraction for cloud computing. The programmer specifies type information for each remote procedure, and a compiler generates stub code linked into each application to marshal and unmarshal arguments into message buffers. Increasingly, however, application and service operations teams need a high degree of visibility and control over the flow of RPCs between services, leading many installations to use sidecars or service mesh proxies for manageability and policy flexibility. These sidecars typically involve inspection and modification of RPC data that the stub compiler had just carefully assembled, adding needless overhead. Further, upgrading diverse application RPC stubs to use advanced hardware capabilities such as RDMA or DPDK is a long and involved process, and often incompatible with sidecar policy control. In this paper, we propose, implement, and evaluate a novel approach, where RPC marshalling and policy enforcement are done as a system service rather than as a library linked into each application. Applications specify type information to the RPC system as before, while the RPC service executes policy engines and arbitrates resource use, and then marshals data customized to the underlying network hardware capabilities. Our system, mRPC, also supports live upgrades so that both policy and marshalling code can be updated transparently to application code. Compared with using a sidecar, mRPC speeds up a standard microservice benchmark, DeathStarBench, by up to 2.5 $\times$ while having a higher level of policy flexibility and availability.
💡 Analysis
Remote Procedure Call (RPC) is a widely used abstraction for cloud computing. The programmer specifies type information for each remote procedure, and a compiler generates stub code linked into each application to marshal and unmarshal arguments into message buffers. Increasingly, however, application and service operations teams need a high degree of visibility and control over the flow of RPCs between services, leading many installations to use sidecars or service mesh proxies for manageability and policy flexibility. These sidecars typically involve inspection and modification of RPC data that the stub compiler had just carefully assembled, adding needless overhead. Further, upgrading diverse application RPC stubs to use advanced hardware capabilities such as RDMA or DPDK is a long and involved process, and often incompatible with sidecar policy control. In this paper, we propose, implement, and evaluate a novel approach, where RPC marshalling and policy enforcement are done as a system service rather than as a library linked into each application. Applications specify type information to the RPC system as before, while the RPC service executes policy engines and arbitrates resource use, and then marshals data customized to the underlying network hardware capabilities. Our system, mRPC, also supports live upgrades so that both policy and marshalling code can be updated transparently to application code. Compared with using a sidecar, mRPC speeds up a standard microservice benchmark, DeathStarBench, by up to 2.5 $\times$ while having a higher level of policy flexibility and availability.
📄 Content
원격 프로시저 호출(RPC)은 클라우드 컴퓨팅 환경에서 널리 사용되는 추상화 메커니즘이다. 개발자는 각 원격 프로시저에 대한 타입 정보를 명시하고, 컴파일러는 해당 정보를 기반으로 스텁 코드를 생성한다. 이 스텁 코드는 애플리케이션에 링크되어 인자들을 메시지 버퍼로 마샬링(marshalling)하고, 반대로 언마샬링(unmarshalling)하는 역할을 수행한다.
하지만 최근에는 애플리케이션 팀과 서비스 운영 팀이 서비스 간 RPC 흐름에 대해 높은 수준의 가시성과 제어권을 요구하고 있다. 이러한 요구를 충족시키기 위해 많은 배포 환경에서는 사이드카(sidecar) 혹은 서비스 메시 프록시(service‑mesh proxy)를 도입하여 관리성 및 정책 유연성을 확보하고 있다. 사이드카는 일반적으로 스텁 컴파일러가 정교하게 조립한 RPC 데이터를 검사하고 필요에 따라 수정한다. 이 과정은 불필요한 오버헤드를 초래하며, 특히 고성능 네트워크 하드웨어(RDMA, DPDK 등)를 활용하려는 경우에는 더욱 문제가 된다.
다양한 애플리케이션의 RPC 스텁을 최신 하드웨어 기능에 맞게 업그레이드하는 작업은 복잡하고 시간이 많이 소요된다. 게다가 사이드카 기반 정책 제어와 하드웨어 특화 최적화는 종종 호환되지 않아, 두 목표를 동시에 달성하기가 어렵다.
본 논문에서는 이러한 한계를 극복하기 위한 새로운 접근 방식을 제안하고, 구현 및 평가까지 수행하였다. 핵심 아이디어는 “RPC 마샬링과 정책 집행을 각 애플리케이션에 링크되는 라이브러리가 아니라 시스템 서비스 형태로 제공한다”는 것이다. 애플리케이션은 기존과 동일하게 타입 정보를 RPC 시스템에 제공하고, 실제 마샬링 작업과 정책 판단은 별도의 RPC 서비스가 담당한다. 이 서비스는 정책 엔진을 실행해 자원 사용을 중재하고, 하드웨어가 지원하는 기능(RDMA, DPDK 등)에 최적화된 형태로 데이터를 마샬링한다.
우리 시스템의 이름은 mRPC이며, 다음과 같은 주요 특징을 갖는다.
- 중앙 집중형 정책 엔진 – 모든 서비스 인스턴스가 동일한 정책 서비스에 연결되므로, 정책 변경이 전체 클러스터에 즉시 반영된다.
- 하드웨어 친화적 마샬링 – 네트워크 어댑터가 제공하는 zero‑copy 전송, 배치 전송 등 고급 기능을 자동으로 활용한다.
- 라이브 업그레이드 지원 – 정책 로직이나 마샬링 로직을 업데이트할 때 애플리케이션 코드를 중단시키지 않는다. 새로운 버전의 서비스가 기존 연결을 인계받아 투명하게 교체된다.
- 사이드카 대비 낮은 레이턴시 – 스텁이 직접 네트워크 스택을 호출하므로, 사이드카가 추가하는 인터셉트·변환 단계가 사라진다.
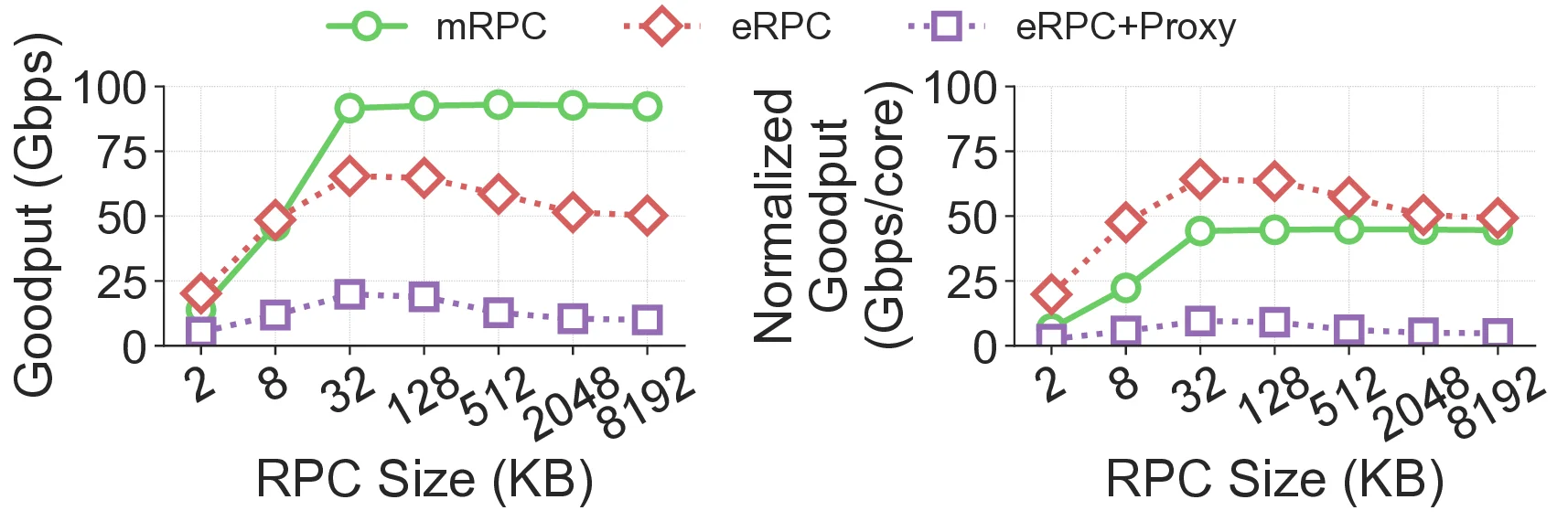
성능 평가를 위해 대표적인 마이크로서비스 벤치마크인 DeathStarBench를 사용하였다. 동일한 워크로드를 사이드카 기반 구성과 mRPC 기반 구성으로 실행했을 때, mRPC는 최대 2.5배의 처리량 향상을 보였다. 또한 정책 적용 시에도 서비스 가용성이 유지되었으며, 정책 복잡도가 증가해도 레이턴시 증가폭이 미미했다.
요약하면, RPC 마샬링을 시스템 서비스 수준으로 끌어올림으로써 (1) 애플리케이션 코드와 네트워크 하드웨어 사이의 불필요한 중간 계층을 제거하고, (2) 정책 관리의 일관성과 실시간성을 확보하며, (3) 하드웨어 가속 기능을 손쉽게 활용할 수 있게 된다. 이러한 설계는 클라우드 네이티브 환경에서 마이크로서비스 간 통신을 최적화하고, 운영 팀이 요구하는 높은 수준의 정책 제어와 가용성을 동시에 만족시킨다.
향후 연구 과제로는 다중 테넌시 환경에서의 보안 격리 강화, 다양한 프로그래밍 언어에 대한 자동 스텁 생성 지원, 그리고 기존 서비스 메시와의 호환성을 위한 인터페이스 표준화 등을 제시한다. 이러한 방향성을 통해 mRPC가 클라우드 인프라 전반에 걸쳐 널리 채택될 수 있기를 기대한다.