Locate: Low-Power Viterbi Decoder Exploration using Approximate Adders
Viterbi decoders are widely used in communication systems, natural language processing (NLP), and other domains. While Viterbi decoders are compute-intensive and power-hungry, we can exploit approximations for early design space exploration (DSE) of trade-offs between accuracy, power, and area. We present Locate, a DSE framework that uses approximate adders in the critically compute and power-intensive Add-Compare-Select Unit (ACSU) of the Viterbi decoder. We demonstrate the utility of Locate for early DSE of accuracy-power-area trade-offs for two applications: communication systems and NLP, showing a range of pareto-optimal design configurations. For instance, in the communication system, using an approximate adder, we observe savings of 21.5% area and 31.02% power with only 0.142% loss in accuracy averaged across three modulation schemes. Similarly, for a Parts-of-Speech Tagger in an NLP setting, out of 15 approximate adders, 7 report 100% accuracy while saving 22.75% area and 28.79% power on average when compared to using a Carry-Lookahead Adder in the ACSU. These results show that Locate can be used synergistically with other optimization techniques to improve the end-to-end efficiency of Viterbi decoders for various application domains.
💡 Research Summary
The paper introduces “Locate,” a design‑space‑exploration (DSE) framework that leverages approximate adders (AAs) to reduce the power and area of Viterbi decoders while keeping accuracy loss minimal. The Viterbi algorithm is a cornerstone of many signal‑processing and machine‑learning tasks, but its most computationally intensive component—the Add‑Compare‑Select Unit (ACSU)—relies heavily on fast, accurate adders such as carry‑lookahead adders (CLAs). CLAs, however, consume significant silicon area and dynamic power, especially when the decoder must operate at high throughput.
Locate addresses this bottleneck by systematically substituting the exact CLA in the ACSU with a library of fifteen state‑of‑the‑art approximate adders. For each AA, the authors pre‑characterize both its hardware metrics (gate count, critical‑path delay, static and dynamic power) and its functional error characteristics (offset, mean absolute error, worst‑case error). The framework then proceeds in two main phases.
-
Accuracy Impact Modeling: Using Monte‑Carlo simulations over a wide range of input sequences and channel conditions (different signal‑to‑noise ratios, modulation schemes, and NLP sentence lengths), the authors quantify how the error introduced by an AA propagates through the path‑metric computation and influences the final decision of the Viterbi algorithm. This phase yields a probabilistic bound on acceptable error for a given application‑level accuracy target (e.g., bit‑error‑rate ≤ 10⁻⁵ for communications, 100 % tagging accuracy for NLP).
-
Hardware Evaluation & Multi‑Objective DSE: Candidate AAs that satisfy the error bound are instantiated in RTL, synthesized, placed‑and‑routed, and measured for area and power. A multi‑objective optimizer (based on NSGA‑II) then explores the Pareto front of accuracy, power, and area, delivering a set of “Pareto‑optimal” configurations.
The authors validate Locate on two representative workloads.
-
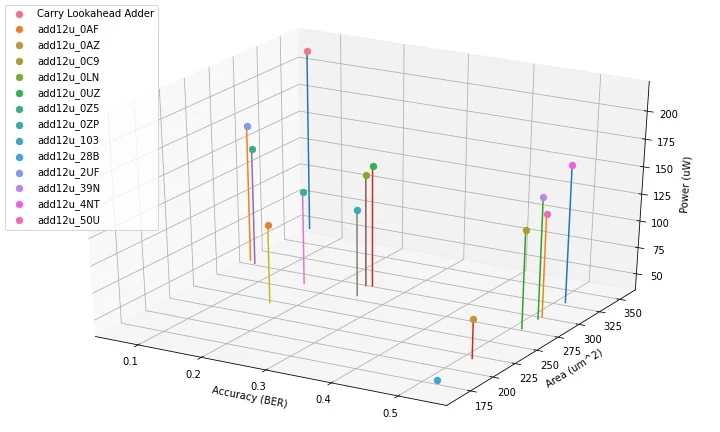
Communication System: A Viterbi decoder is used for three modulation schemes (16‑QAM, 64‑QAM, 256‑QAM). Substituting a carefully chosen AA in the ACSU yields an average accuracy degradation of only 0.142 % while cutting silicon area by 21.5 % and dynamic power by 31.02 % compared with a baseline CLA implementation.
-
Natural‑Language‑Processing (POS Tagger): The same methodology is applied to a hidden‑Markov‑model‑based part‑of‑speech tagger. Out of the fifteen AAs, seven achieve identical tagging accuracy to the exact CLA (100 % correctness) while delivering average area savings of 22.75 % and power reductions of 28.79 %.
Key insights from the study include:
- Early‑stage trade‑off visibility: By modeling accuracy loss analytically before hardware synthesis, Locate enables rapid pruning of unsuitable AAs, dramatically shortening the design cycle.
- Robustness of AAs for Viterbi: Despite the cumulative nature of metric calculations, many AAs introduce errors that cancel out or remain below the decision threshold, especially in high‑SNR regimes or when the underlying statistical model (e.g., HMM) is tolerant to small metric perturbations.
- Synergy with other optimizations: Locate can be combined with voltage scaling, clock gating, or architectural techniques (e.g., parallel path pruning) to further push the efficiency envelope.
The paper also discusses limitations. The error model assumes statistically independent input patterns; pathological sequences or extremely low‑SNR channels could amplify AA errors, necessitating additional verification. Moreover, the current focus is solely on the ACSU; extending approximation to the traceback unit or memory interfaces could unlock additional savings but would require new modeling techniques. Finally, integrating the AA library and the DSE flow into a commercial ASIC design environment would benefit from automated toolchains for library generation and re‑characterization across process corners.
In conclusion, Locate demonstrates that approximate arithmetic, when applied judiciously and guided by a rigorous accuracy‑impact model, can substantially improve the power‑area efficiency of Viterbi decoders across disparate domains. The framework provides a practical pathway for hardware designers to explore and adopt approximate computing techniques early in the design process, paving the way for more energy‑aware communication and machine‑learning hardware.
Comments & Academic Discussion
Loading comments...
Leave a Comment