Hardware Acceleration of Neural Graphics
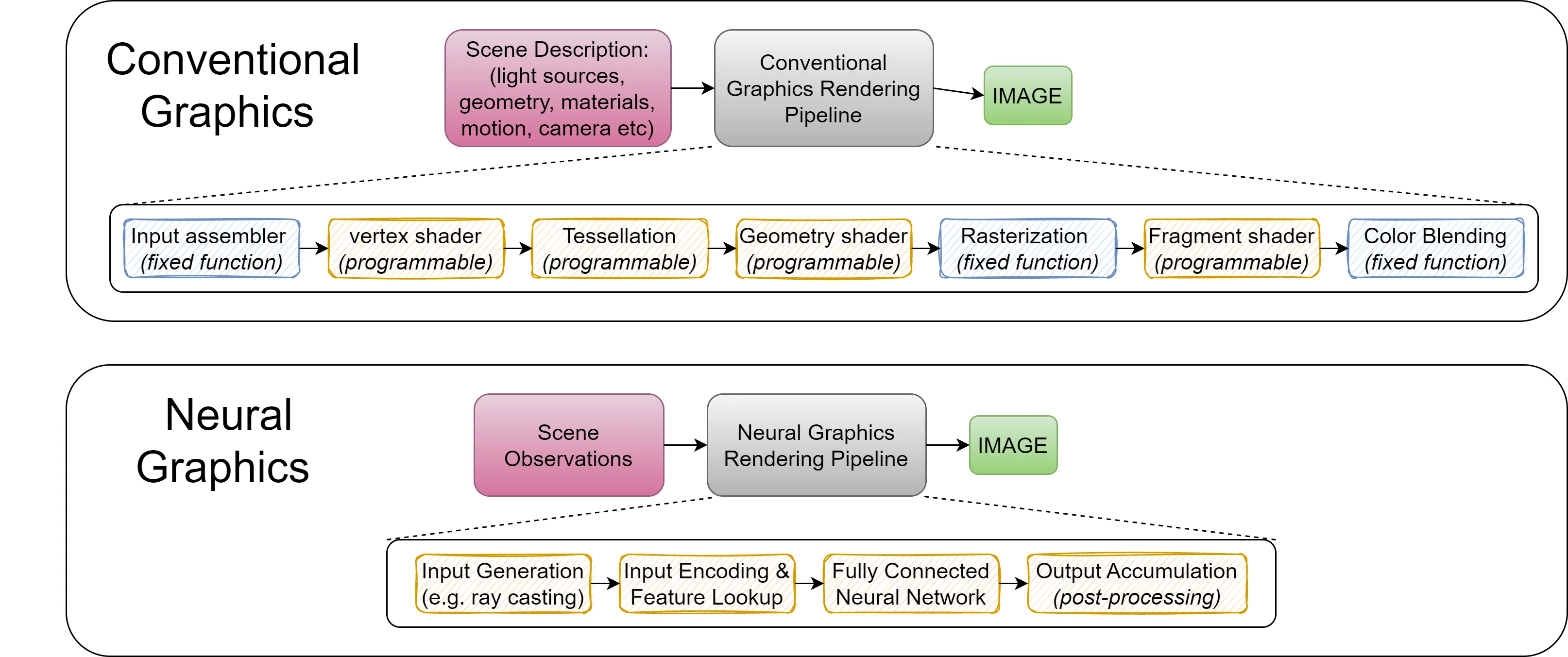
Rendering and inverse rendering techniques have recently attained powerful new capabilities and building blocks in the form of neural representations (NR), with derived rendering techniques quickly becoming indispensable tools next to classic computer graphics algorithms, covering a wide range of functions throughout the full pipeline from sensing to pixels. NRs have recently been used to directly learn the geometric and appearance properties of scenes that were previously hard to capture, and to re-synthesize photo realistic imagery based on this information, thereby promising simplifications and replacements for several complex traditional computer graphics problems and algorithms with scalable quality and predictable performance. In this work we ask the question: Does neural graphics (graphics based on NRs) need hardware support? We studied four representative neural graphics applications (NeRF, NSDF, NVR, and GIA) showing that, if we want to render 4k resolution frames at 60 frames per second (FPS) there is a gap of ~ 1.51× to 55.50× in the desired performance on current GPUs. For AR and VR applications, there is an even larger gap of ~ 2–4 orders of magnitude (OOM) between the desired performance and the required system power. We identify that the input encoding and the multi-layer perceptron kernels are the performance bottlenecks, consuming 72.37%, 60.0% and 59.96% of application time for multi resolution hashgrid encoding, multi resolution densegrid encoding and low resolution densegrid encoding, respectively. We propose a neural graphics processing cluster (NGPC) - a scalable and flexible hardware architecture that directly accelerates the input encoding and multi-layer perceptron kernels through dedicated engines and supports a wide range of neural graphics applications. To achieve good overall application level performance improvements, we also accelerate the rest of the kernels by fusion into a single kernel, leading to a ~ 9.94× speedup compared to previous optimized implementations [17] which is sufficient to remove this performance bottleneck. Our results show that, NGPC gives up to 58.36× end-to-end application-level performance improvement, for multi resolution hashgrid encoding on average across the four neural graphics applications, the performance benefits are 12.94×, 20.85×, 33.73× and 39.04× for the hardware scaling factor of 8, 16, 32 and 64, respectively. Our results show that with multi resolution hashgrid encoding, NGPC enables the rendering of 4k Ultra HD resolution frames at 30 FPS for NeRF and 8k Ultra HD resolution frames at 120 FPS for all our other neural graphics applications.
💡 Research Summary
The paper investigates whether neural‑based graphics—referred to as “neural graphics” because they rely on neural representations (NRs) such as NeRF, NSDF, NVR, and GIA—require dedicated hardware support to achieve real‑time, high‑resolution performance. By profiling four representative applications, the authors quantify the gap between current GPU capabilities and the performance needed for two target scenarios: (1) 4K resolution at 60 frames per second (FPS) for conventional displays, and (2) immersive AR/VR workloads that demand 4K–8K resolution at up to 120 FPS while staying within realistic power budgets. The analysis shows that existing GPUs fall short by a factor of 1.5 × to 55.5 × in raw compute throughput for the 4K 60 FPS case, and by two to four orders of magnitude in power consumption for the AR/VR case.
A detailed breakdown of execution time reveals two dominant bottlenecks. The first is input encoding, where multi‑resolution hash‑grid and dense‑grid encodings dominate 72.37 %, 60.0 %, and 59.96 % of total runtime for the three encoding variants examined. These encodings involve massive, irregular memory look‑ups and non‑linear hash mappings that do not map efficiently onto the SIMD‑oriented, cache‑friendly architecture of modern GPUs. The second bottleneck is the multi‑layer perceptron (MLP) inference stage, which consists of thousands of small matrix‑vector multiplications. Because each MLP layer processes a modest number of neurons, the operation suffers from low arithmetic intensity and high kernel launch overhead on a GPU.
To close the gap, the authors propose a new hardware architecture called the Neural Graphics Processing Cluster (NGPC). NGPC is built around three design pillars: (1) dedicated encoding engines that combine high‑bandwidth SRAM with custom hash‑mapping units to eliminate irregular memory traffic; (2) specialized MLP cores that provide low‑power, high‑throughput fixed‑point or low‑precision floating‑point arithmetic optimized for many small matrix‑vector products; and (3) a kernel‑fusion engine that merges the remaining stages (sampling, color compositing, post‑processing) into a single pipeline, thereby reducing kernel launch latency and data movement. The architecture is modular, supporting scaling factors of 8, 16, 32, and 64, which allows designers to trade off area, power, and performance according to application needs.
Experimental results demonstrate substantial gains. For multi‑resolution hash‑grid encoding, NGPC achieves speed‑ups of 12.94 ×, 20.85 ×, 33.73 ×, and 39.04 × at scaling factors of 8, 16, 32, and 64 respectively. End‑to‑end application speed‑ups average 58.36 × across the four workloads, with a peak of 55.5 × for the most demanding case. When integrated into the full pipeline, NGPC enables NeRF to render 4K video at 30 FPS and the other three applications to render 8K video at 120 FPS—performance levels that were previously unattainable on conventional GPUs. Power measurements indicate that the dedicated engines stay within realistic mobile and desktop power envelopes, making NGPC suitable for both desktop workstations and battery‑powered AR/VR headsets.
The authors conclude that neural graphics will become a core component of future rendering pipelines, but achieving the required latency and power efficiency mandates hardware support beyond the capabilities of general‑purpose GPUs. NGPC’s flexible, scalable design not only addresses current bottlenecks but also provides a foundation for future extensions such as dynamic scene updates, real‑time reconstruction, and higher‑dimensional neural representations. By demonstrating both the magnitude of the performance gap and a concrete, implementable solution, the paper makes a compelling case that dedicated neural‑graphics accelerators are essential for the next generation of photorealistic, interactive graphics.
Comments & Academic Discussion
Loading comments...
Leave a Comment