READ Avatars: Realistic Emotion-controllable Audio Driven Avatars
We present READ Avatars, a 3D-based approach for generating 2D avatars that are driven by audio input with direct and granular control over the emotion. Previous methods are unable to achieve realistic animation due to the many-to-many nature of audio to expression mappings. We alleviate this issue by introducing an adversarial loss in the audio-to-expression generation process. This removes the smoothing effect of regression-based models and helps to improve the realism and expressiveness of the generated avatars. We note furthermore, that audio should be directly utilized when generating mouth interiors and that other 3D-based methods do not attempt this. We address this with audio-conditioned neural textures, which are resolution-independent. To evaluate the performance of our method, we perform quantitative and qualitative experiments, including a user study. We also propose a new metric for comparing how well an actor’s emotion is reconstructed in the generated avatar. Our results show that our approach outperforms state of the art audio-driven avatar generation methods across several metrics. A demo video can be found at \url{https://youtu.be/QSyMl3vV0pA}
💡 Research Summary
READ Avatars introduces a comprehensive 3‑D‑based pipeline that generates photorealistic 2‑D talking‑head videos from audio while offering fine‑grained, continuous control over the speaker’s emotion. The authors identify two fundamental obstacles that have limited prior work: (1) the many‑to‑many relationship between audio and facial expressions, which causes regression‑based models to produce over‑smoothed lip motions, and (2) the inability of existing 3‑D morphable models (e.g., FLAME) to represent complex lip shapes and interior mouth details such as the tongue and teeth.
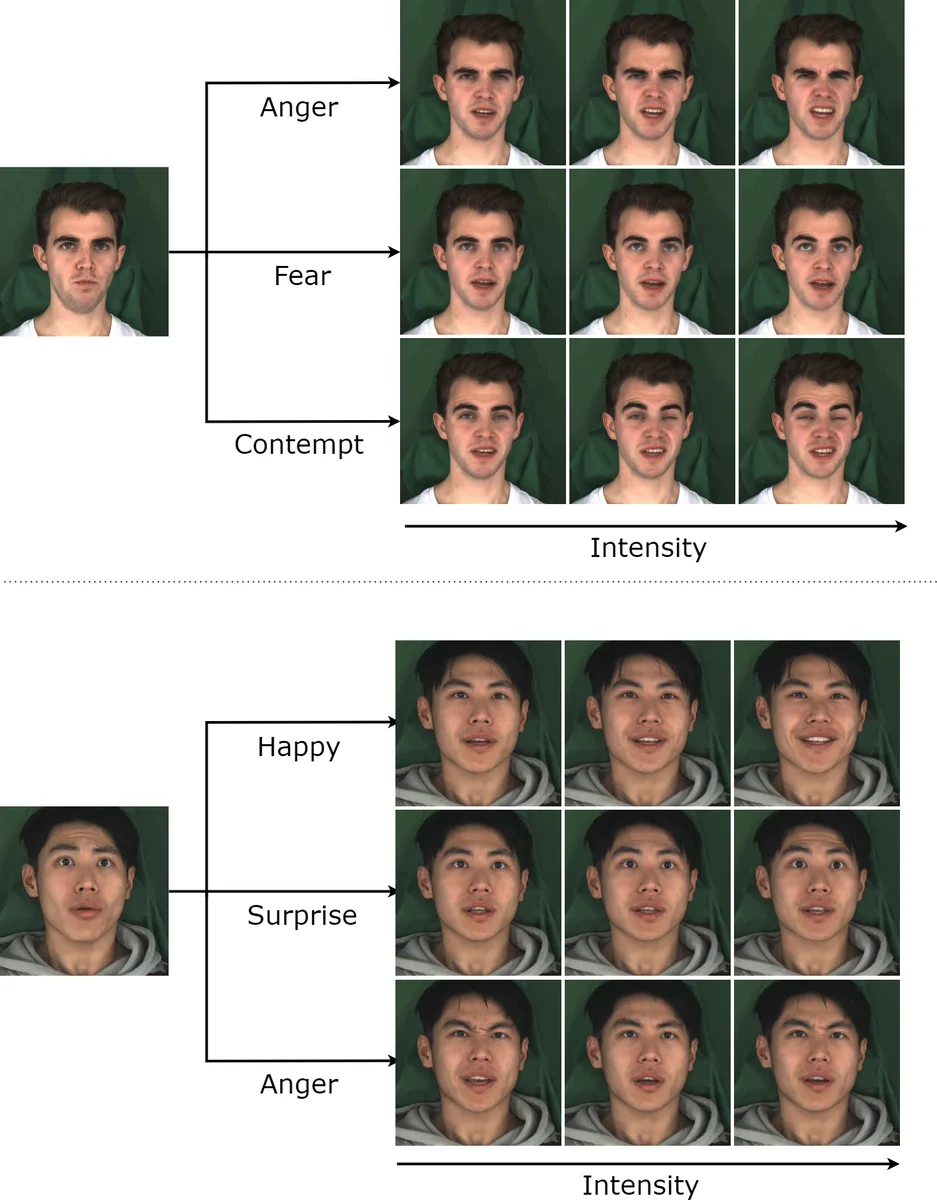
To address (1), the paper replaces the conventional L1‑only audio‑to‑expression regressor with a conditional Generative Adversarial Network (cGAN) inspired by Pix2Pix. The generator receives a short window of MFCC features together with an explicit emotion vector C. Emotions are encoded as an (N‑1)‑dimensional continuous label where neutral corresponds to the zero vector and each other emotion occupies a dedicated dimension scaled by intensity (0–1). This design enables users to specify both the type and strength of an emotion, achieving semantic yet granular control. The discriminator is conditioned on the same audio and emotion label, forcing the generator to produce expression parameters that are indistinguishable from real ones. The loss combines L1 reconstruction, adversarial loss (λ_GAN = 0.02), and a velocity loss (λ_vel = 100) that promotes temporal consistency.
For (2), the authors augment the 3‑D pipeline with an audio‑conditioned neural texture. Instead of a static learned texture map, they employ a SIREN‑based multilayer perceptron that maps UV coordinates directly to a high‑dimensional feature vector. Audio conditioning is achieved by concatenating a compact audio embedding a_enc to the UV input. The audio embedding is derived from a pretrained wav2vec2 model that predicts phoneme probabilities (50 fps); these probabilities are resampled to 60 fps, aggregated over a temporal window, and passed through a small fully‑connected + temporal‑conv network. By injecting phoneme‑level information, the texture can synthesize realistic tongue, teeth, and inner‑mouth movements that vary with speech. The texture outputs a 16‑channel rasterized image, which is then refined by a UNet‑based deferred neural renderer to produce the final photorealistic frame.
The overall pipeline consists of three stages: (1) fitting a FLAME 3‑D morphable model to a reference video (shape, texture, lighting are fixed per subject; per‑frame pose and expression are estimated), (2) generating per‑frame expression parameters from audio and emotion using the cGAN, and (3) rendering the mesh with the audio‑conditioned neural texture and UNet decoder.
Evaluation is thorough. Quantitative metrics include Fréchet Inception Distance (FID) for visual quality, LSE‑D/C for lip‑sync accuracy, and a newly proposed Audio‑Video Emotion Matching Distance (A/V‑EMD) that measures how well the generated emotion matches the target. READ Avatars outperforms three strong baselines—TVG (2‑D landmark‑based), MEAD (audio‑driven with discrete emotion control), and EVP (audio‑driven emotional video portraits)—across all metrics, achieving notably lower A/V‑EMD scores and higher user‑study ratings for realism and emotional clarity.
The paper also discusses limitations. The method requires a subject‑specific 3‑DMM fitting stage, which involves capturing a high‑quality reference video and may hinder scalability to arbitrary users. The audio‑conditioned texture could overfit to the training speaker, raising questions about generalization to unseen identities. GAN training can be unstable, potentially leading to occasional unrealistic expressions. Future work could explore domain‑adaptive fitting, lightweight texture networks, and more robust adversarial training strategies.
In summary, READ Avatars successfully tackles the many‑to‑many audio‑expression mapping with adversarial learning and enriches mouth interior realism via audio‑conditioned neural textures. The result is a state‑of‑the‑art, emotion‑controllable, audio‑driven avatar system that sets a new benchmark for both visual fidelity and expressive flexibility.
Comments & Academic Discussion
Loading comments...
Leave a Comment