Training LSTM Networks with Resistive Cross-Point Devices
In our previous work we have shown that resistive cross point devices, so called Resistive Processing Unit (RPU) devices, can provide significant power and speed benefits when training deep fully connected networks as well as convolutional neural networks. In this work, we further extend the RPU concept for training recurrent neural networks (RNNs) namely LSTMs. We show that the mapping of recurrent layers is very similar to the mapping of fully connected layers and therefore the RPU concept can potentially provide large acceleration factors for RNNs as well. In addition, we study the effect of various device imperfections and system parameters on training performance. Symmetry of updates becomes even more crucial for RNNs; already a few percent asymmetry results in an increase in the test error compared to the ideal case trained with floating point numbers. Furthermore, the input signal resolution to device arrays needs to be at least 7 bits for successful training. However, we show that a stochastic rounding scheme can reduce the input signal resolution back to 5 bits. Further, we find that RPU device variations and hardware noise are enough to mitigate overfitting, so that there is less need for using dropout. We note that the models trained here are roughly 1500 times larger than the fully connected network trained on MNIST dataset in terms of the total number of multiplication and summation operations performed per epoch. Thus, here we attempt to study the validity of the RPU approach for large scale networks.
💡 Research Summary
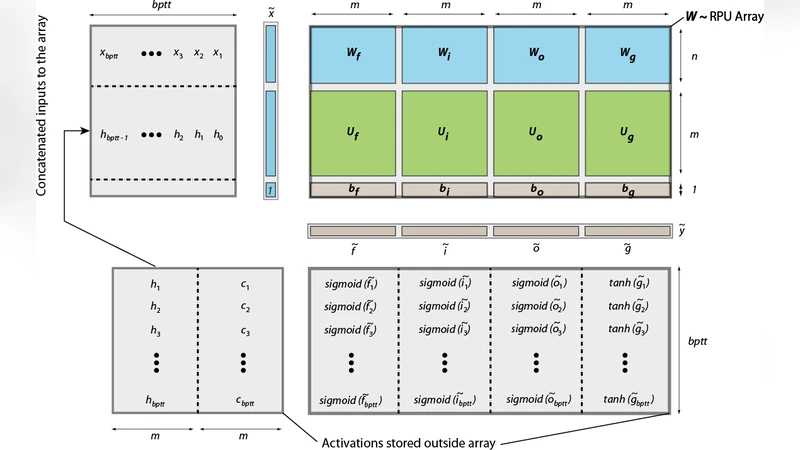
The paper extends the Resistive Processing Unit (RPU) concept—previously demonstrated for fully‑connected and convolutional neural networks—to the training of recurrent neural networks, specifically Long Short‑Term Memory (LSTM) models. By exploiting the weight‑sharing property of LSTMs across time steps, all trainable parameters of an LSTM block can be consolidated into a single large matrix that is mapped onto one analog cross‑point array. During the forward pass, a concatenated input vector (current input, previous hidden state, and bias) is multiplied by this matrix in a single analog matrix‑vector operation; all nonlinearities (sigmoid, tanh, and element‑wise products) are handled by external digital non‑linear function (NLF) units. The backward pass similarly uses the same array for the transpose multiplication, while gradient computation and weight updates follow a rank‑1 outer‑product scheme compatible with the parallel nature of RPUs.
The authors evaluate the approach on two large character‑level language modeling tasks: Tolstoy’s “War and Peace” (≈3.2 M characters, 87‑character vocabulary) and the Linux kernel source (≈6.4 M characters, 101‑character vocabulary). They train models with one or two stacked LSTM layers and hidden sizes of 64, 128, 256, and 512, resulting in up to ~1.2 × 10⁹ parameters and ~7 × 10¹² multiply‑accumulate operations per epoch—roughly 1,000‑fold more work than a fully‑connected MNIST benchmark used in earlier RPU studies.
Key hardware non‑idealities are systematically examined:
- Update Asymmetry – Positive and negative conductance changes must be symmetric. The study shows that even a 2–5 % asymmetry degrades test perplexity dramatically, because errors accumulate over many time steps.
- Input Signal Resolution – A minimum of 7‑bit DAC resolution is required for stable training. However, employing stochastic rounding reduces the effective resolution requirement to 5 bits without noticeable loss in accuracy.
- Device‑to‑Device Variability and Noise – Conductance increments are modeled with 30 % cycle‑to‑cycle variation and a 2 % device‑to‑device asymmetry ratio. Gaussian noise (σ ≈ 0.07 Δw) and output saturation limits are also added. Interestingly, this intrinsic noise acts as a regularizer, allowing dropout rates to be lowered (or even omitted) without over‑fitting.
Baseline simulations using high‑precision floating‑point (FP) stochastic gradient descent (SGD) reproduce or slightly improve upon published results, confirming that simple SGD (mini‑batch = 1, learning rate ≈ 3e‑3, unroll = 100) is sufficient for these tasks. When the same training regimen is run with the RPU model, test errors increase with network size unless the above hardware constraints are satisfied.
The paper concludes that LSTM training on analog RPU arrays is feasible and can deliver substantial speed and energy benefits, but only if the hardware is engineered to meet strict symmetry (≤ 1 % asymmetry), resolution (≥ 7 bits or stochastic rounding), and noise management specifications. These findings provide concrete design guidelines for future large‑scale analog accelerators targeting recurrent architectures.
Comments & Academic Discussion
Loading comments...
Leave a Comment