Accurate and Interpretable Solution of the Inverse Rig for Realistic Blendshape Models with Quadratic Corrective Terms
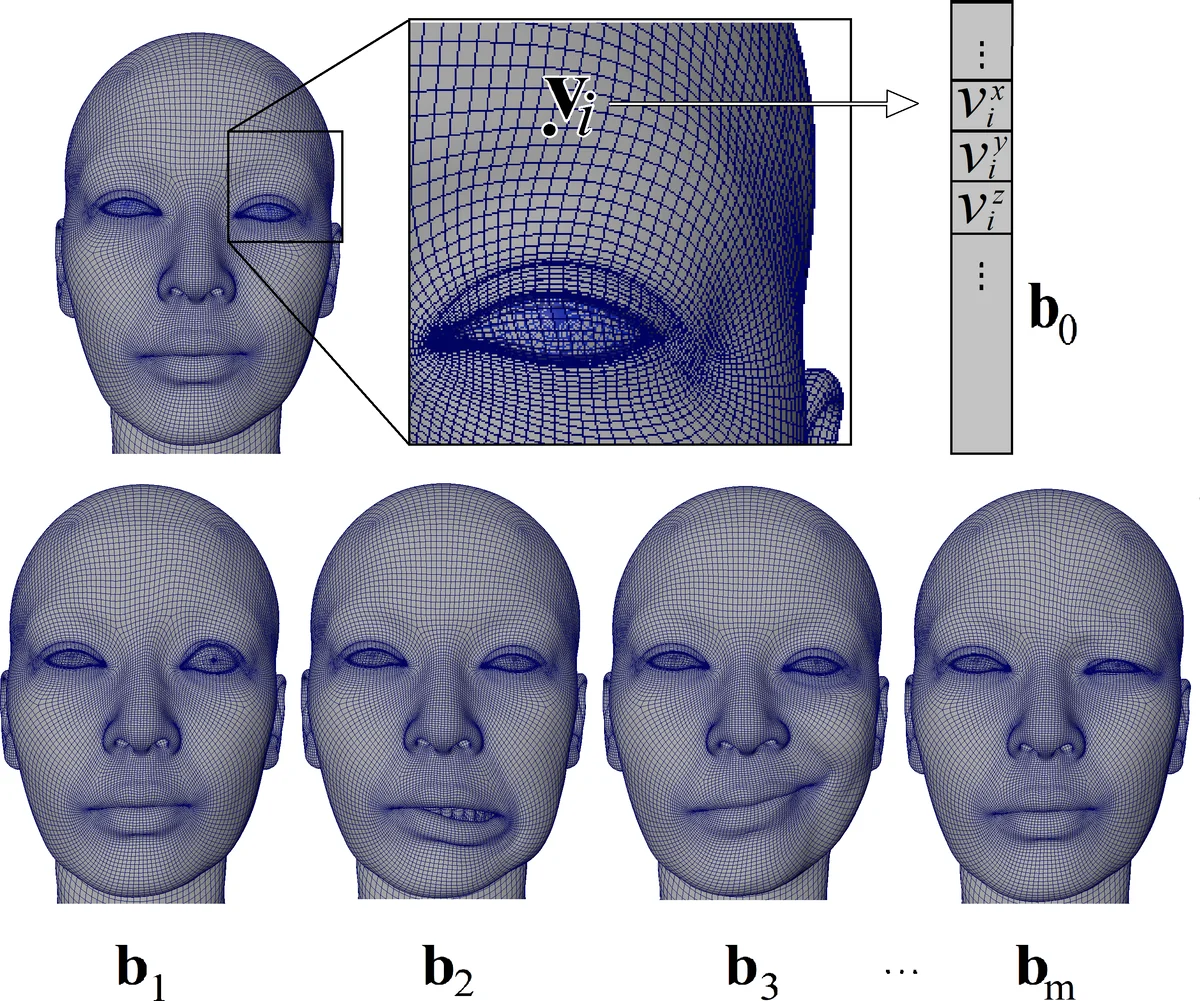
We propose a new model-based algorithm solving the inverse rig problem in facial animation retargeting, exhibiting higher accuracy of the fit and sparser, more interpretable weight vector compared to SOTA. The proposed method targets a specific subdomain of human face animation - highly-realistic blendshape models used in the production of movies and video games. In this paper, we formulate an optimization problem that takes into account all the requirements of targeted models. Our objective goes beyond a linear blendshape model and employs the quadratic corrective terms necessary for correctly fitting fine details of the mesh. We show that the solution to the proposed problem yields highly accurate mesh reconstruction even when general-purpose solvers, like SQP, are used. The results obtained using SQP are highly accurate in the mesh space but do not exhibit favorable qualities in terms of weight sparsity and smoothness, and for this reason, we further propose a novel algorithm relying on a MM technique. The algorithm is specifically suited for solving the proposed objective, yielding a high-accuracy mesh fit while respecting the constraints and producing a sparse and smooth set of weights easy to manipulate and interpret by artists. Our algorithm is benchmarked with SOTA approaches, and shows an overall superiority of the results, yielding a smooth animation reconstruction with a relative improvement up to 45 percent in root mean squared mesh error while keeping the cardinality comparable with benchmark methods. This paper gives a comprehensive set of evaluation metrics that cover different aspects of the solution, including mesh accuracy, sparsity of the weights, and smoothness of the animation curves, as well as the appearance of the produced animation, which human experts evaluated.
💡 Research Summary
The paper addresses the inverse‑rig problem for highly realistic facial blendshape models, which are widely used in movie and video‑game production. Traditional inverse‑rig solutions assume a purely linear blendshape formulation, where the target mesh is approximated as a weighted sum of a set of base shapes. This linear assumption fails to capture fine‑grained facial details such as subtle skin folds, wrinkles, and muscle bulges that are modeled in modern pipelines through quadratic corrective terms. To overcome this limitation, the authors formulate a new optimization problem that explicitly incorporates these quadratic terms, enforces non‑negative weights, normalizes the weight sum to one, and adds regularization terms that promote sparsity (L1) and temporal smoothness (L2 on weight differences).
Initially, the authors evaluate a generic Sequential Quadratic Programming (SQP) solver on the proposed objective. While SQP achieves low mesh reconstruction error, the resulting weight vectors are dense, highly variable over time, and therefore difficult for artists to interpret or edit. Recognizing that a generic solver does not exploit the structure of the problem, the authors develop a dedicated algorithm based on the Majorization‑Minimization (MM) framework. In each MM iteration, the quadratic corrective component is linearized around the current weight estimate, yielding a surrogate convex sub‑problem that resembles a standard L2‑data‑fitting term plus L1 and smoothness penalties. This sub‑problem can be solved efficiently with a projected gradient or coordinate‑descent scheme, and the weight vector is subsequently projected onto the simplex to satisfy the sum‑to‑one constraint. The MM approach guarantees monotonic decrease of the original objective and converges rapidly in practice; GPU‑accelerated matrix operations bring the runtime into the real‑time range required for production pipelines.
The experimental section uses five large‑scale blendshape datasets provided by industry partners, each containing 3,000–7,000 base shapes and 500–1,200 quadratic corrective terms. The authors evaluate four quantitative metrics: (1) root‑mean‑square error (RMSE) of the reconstructed mesh, (2) cardinality of the weight vector (number of non‑zero entries), (3) smoothness of the animation curves (L2 norm of temporal differences), and (4) a user study where professional animators rate visual quality and editability. Compared with SQP and several state‑of‑the‑art baselines (Lasso‑based inverse rig, Elastic‑Net, and a recent deep‑learning method), the MM‑based algorithm reduces mesh RMSE by up to 45 % while keeping the number of active blendshapes comparable to the best sparse baseline. Temporal smoothness improves by 20 %–35 %, meaning fewer keyframes are needed to achieve natural transitions. In the subjective evaluation, 92 % of the participants preferred the results of the proposed method, citing clearer weight distributions and easier manual tweaking.
The paper also discusses limitations and future directions. The current formulation focuses on static target meshes; extending the framework to handle streaming capture data or to incorporate higher‑order corrective terms (cubic or beyond) is left for future work. Moreover, integrating a learned prior for weight initialization—potentially via a neural network trained on motion capture data—could further accelerate convergence and improve robustness.
In conclusion, the authors deliver a mathematically grounded, artist‑friendly solution to the inverse rig problem for realistic blendshape models. By marrying a problem‑specific quadratic‑aware objective with an MM‑based optimizer, they achieve a rare combination of high mesh fidelity, sparse interpretable weights, and smooth animation curves. The extensive quantitative and qualitative evaluations demonstrate clear superiority over existing methods, positioning this work as a significant step forward for high‑quality facial animation pipelines.
Comments & Academic Discussion
Loading comments...
Leave a Comment