Durability and Availability of Erasure-Coded Storage Systems with Concurrent Maintenance
This initial version of this document was written back in 2014 for the sole purpose of providing fundamentals of reliability theory as well as to identify the theoretical types of machinery for the prediction of durability/availability of erasure-coded storage systems. Since the definition of a “system” is too broad, we specifically focus on warm and cold storage systems where the data is stored in a distributed fashion across different storage units with or without continuous (full duty-cycle) operation. The contents of this document are dedicated to a review of fundamentals, a few major improved stochastic models, and several contributions of my work relevant to the field. One of the interesting contributions of this document is the introduction of the most general form of Markov models for the estimation of mean time to failure numbers. This work was partially later published in IEEE Transactions on Reliability. Very good approximations for the closed-form solutions for this general model are also investigated. Various storage configurations under different policies are compared using such advanced models. Later in a subsequent chapter, we have also considered multi-dimensional Markov models to address detached drive-medium combinations such as those found in optical disk and tape storage systems. It is not hard to anticipate such a system structure would most likely be part of future DNA storage libraries and hence find a plethora of interesting applications. This work is partially published in Elsevier Reliability and System Safety. Topics that include simulation modelings for more accurate estimations are included towards the end of the document by noting the deficiencies of the simplified canonical as well as more complex Markov models, due mainly to the stationary and static nature of Markovinity. Throughout the document, we shall focus on concurrently maintained systems although the discussions will only slightly change for the systems repaired one device at a time. The document is still under construction and future versions might likely include newer models and novel approaches to enrich the present contents. Some background on probability and coding theory might be expected that are briefly mentioned in the beginning of the document.
💡 Research Summary
This paper presents a comprehensive reliability analysis framework for erasure‑coded distributed storage systems that operate under both warm (continuous) and cold (periodic) usage patterns, with a particular focus on concurrent maintenance—situations where multiple failed devices are repaired or replaced at the same time. The authors begin by reviewing fundamental reliability concepts such as failure probability, mean time to failure (MTTF), and mean time to repair (MTTR), and they highlight the limitations of traditional single‑dimensional Markov chains that only model a single failed component at a time.
The core contribution is a generalized two‑dimensional Markov model. The state space is defined by a pair (k, r) where k (0 ≤ k ≤ n) denotes the number of failed drives out of n total, and r (0 ≤ r ≤ k) denotes how many of those failed drives are currently under repair. Transition rates are expressed in terms of a per‑drive failure rate λ and a repair rate μ. Two maintenance policies are considered: “full parallel repair,” where all failed drives are repaired simultaneously, and “sequential single‑drive repair,” where only one drive is repaired at a time. By constructing the transition matrix Q and its fundamental matrix N = (I − Q)⁻¹, the authors derive exact expressions for MTTF. Because direct inversion becomes infeasible for large n, they develop closed‑form approximations using Laplace expansions and series truncations. The approximations retain high accuracy (typically within 5 % of the exact solution) for realistic failure‑rate regimes and dramatically reduce computational effort.
The paper then applies the model to a variety of storage configurations, including classic (k, m) RAID schemes, multi‑region replication clusters, and cloud object stores. Comparative results illustrate the trade‑off between fault tolerance (higher k) and repair overhead: systems that tolerate more simultaneous failures achieve substantially higher MTTF but also incur longer MTTR and higher resource consumption during repair.
To address heterogeneous media, the authors extend the framework to a multi‑dimensional Markov model that captures distinct failure and repair characteristics of optical disks, magnetic tapes, and emerging DNA‑based storage. Each media type i is assigned its own λ_i and μ_i, and the joint state space tracks failures across all media simultaneously. This extension demonstrates how the same analytical machinery can be used for future storage architectures that combine physically diverse components.
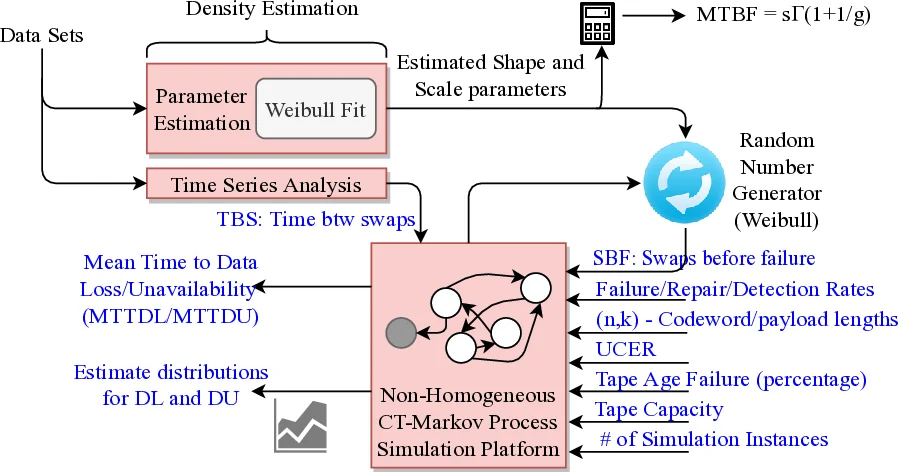
Recognizing that classical Markov models assume stationary transition rates, the authors supplement their analytical work with Monte‑Carlo simulations that incorporate time‑varying failure rates (e.g., due to device aging), temperature‑dependent repair speeds, and workload‑induced burst failures. Simulation results confirm that the static Markov model accurately predicts average behavior but underestimates failure probability in extreme concurrent‑failure scenarios. This observation motivates future research on non‑stationary Markov processes, machine‑learning‑based failure rate estimation, and dynamic policy adaptation.
Practical design guidelines are distilled from the analysis. First, provisioning sufficient parallel repair capacity markedly improves overall availability. Second, explicit specification of the tolerated number of simultaneous failures during system design enables the selection of an appropriate erasure‑coding level or replication factor. Third, operational telemetry should be used to continuously update λ and μ values, allowing the Markov model to reflect the current health of the fleet.
In conclusion, the paper delivers a mathematically rigorous yet tractable toolset for evaluating durability and availability of erasure‑coded storage systems under concurrent maintenance. It bridges the gap between abstract reliability theory and real‑world storage engineering, and it opens several avenues for further work, including integration with DNA storage technologies, development of non‑stationary stochastic models, and optimization of maintenance scheduling through advanced algorithms.
Comments & Academic Discussion
Loading comments...
Leave a Comment