Introducing Variational Inference in Statistics and Data Science Curriculum
Abstract Probabilistic models such as logistic regression, Bayesian classification, neural networks, and models for natural language processing, are increasingly more present in both undergraduate and graduate statistics and data science curricula due to their wide range of applications. In this article, we present a one-week course module for students in advanced undergraduate and applied graduate courses on variational inference, a popular optimization-based approach for approximate inference with probabilistic models. Our proposed module is guided by active learning principles: In addition to lecture materials on variational inference, we provide an accompanying class activity, an R shiny app, and guided labs based on real data applications of logistic regression and clustering documents using Latent Dirichlet Allocation with R code. The main goal of our module is to expose students to a method that facilitates statistical modeling and inference with large datasets. Using our proposed module as a foundation, instructors can adopt and adapt it to introduce more realistic case studies and applications in data science, Bayesian statistics, multivariate analysis, and statistical machine learning courses.
💡 Research Summary
The paper addresses a growing gap in statistics and data‑science curricula: while probabilistic models such as logistic regression, Bayesian classifiers, neural networks, and natural‑language‑processing models are increasingly taught, the modern, scalable inference technique known as variational inference (VI) is rarely included, especially at the undergraduate level. To remedy this, the authors design a compact, one‑week teaching module that introduces VI through a blend of lecture, hands‑on activities, and interactive software, all grounded in active‑learning pedagogy.
Motivation and Background
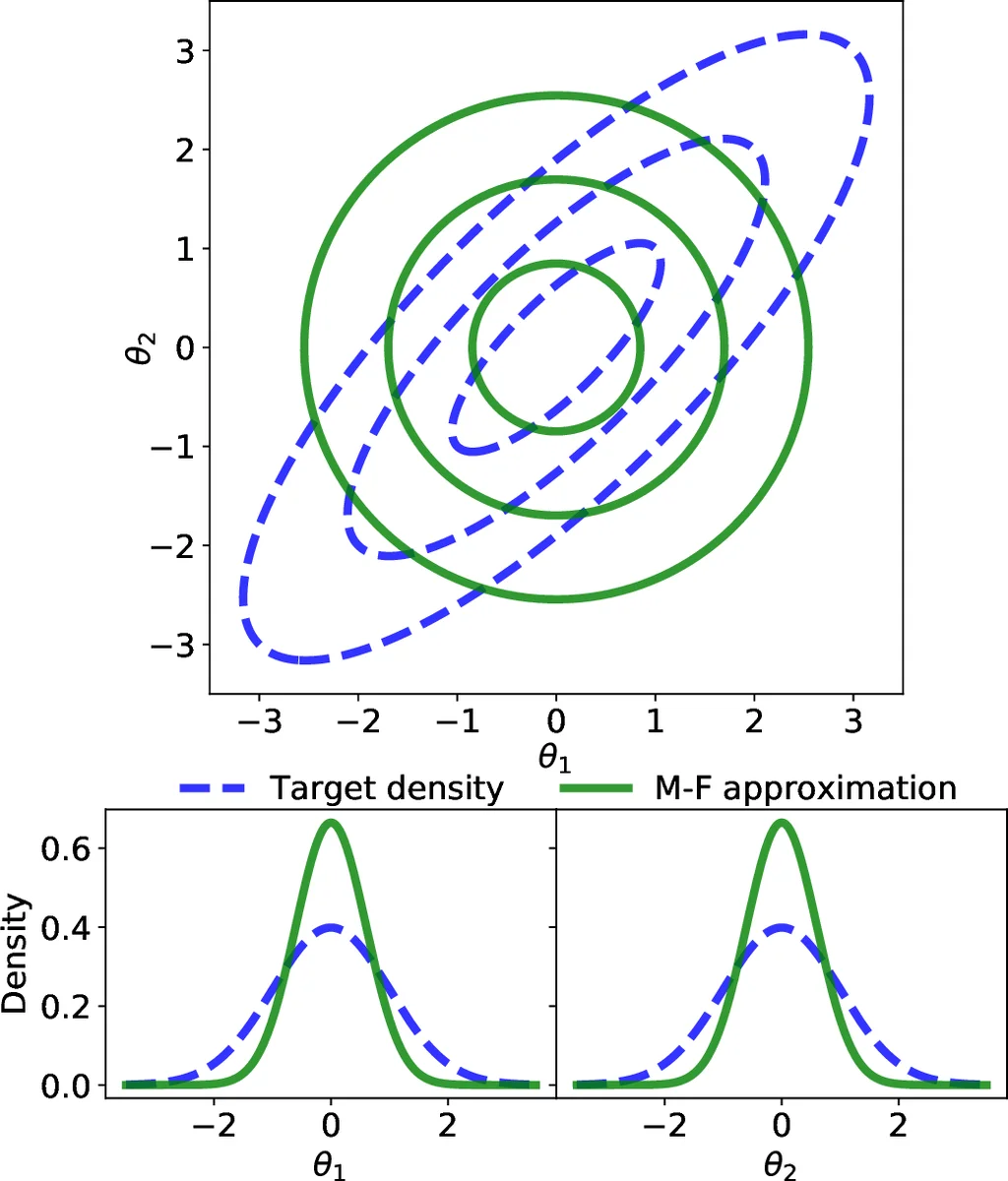
Bayesian inference requires the posterior distribution p(θ|y). Except for a few conjugate cases, the posterior has no closed form and must be approximated. Traditional sampling‑based methods (Gibbs, Metropolis‑Hastings, Hamiltonian Monte Carlo) are accurate but scale poorly with large data sets, limiting their usefulness in classroom case studies that involve massive data. Variational inference reframes posterior approximation as an optimization problem: choose a simple variational family q(θ|λ) and minimize the Kullback‑Leibler (KL) divergence KL(q‖p). Because KL can be expressed as a constant (log p(y)) minus the evidence lower bound (ELBO), maximizing ELBO is equivalent to minimizing KL. This optimization can be performed with gradient‑based or coordinate‑ascent algorithms, making VI amenable to modern automatic‑differentiation tools.
Curriculum Design
The module is split into two class meetings.
Class 1 delivers the theoretical foundations: KL divergence, ELBO, mean‑field variational families, and gradient ascent. Students then apply VI to a simple Gamma‑Poisson model for count data, using a custom R Shiny app that visualizes ELBO progress and parameter updates.
Class 2 offers two optional labs, allowing instructors to match the background of their students:
- Logistic‑Regression Lab – Using a U.S. women laboratory‑participation data set, students fit a Bayesian logistic regression model with VI, illustrating how VI enables fast approximate inference for large binary‑outcome data.
- Document‑Clustering Lab – Students implement Latent Dirichlet Allocation (LDA) on a text corpus, applying VI to infer topic‑word and document‑topic distributions. Both labs are supplied as complete R scripts and a Shiny interface that lets learners explore hyper‑parameter effects in real time.
Pedagogical Choices
The authors deliberately select the mean‑field family for its simplicity, acknowledging its inability to capture posterior correlations but emphasizing that it keeps the optimization tractable for a one‑week module. They compare coordinate ascent (model‑specific derivations) with gradient ascent (black‑box optimization via autodiff). Gradient ascent is recommended because it aligns with current data‑science pipelines, requires fewer derivations, and can be demonstrated using existing libraries (RStan, PyTorch, TensorFlow). The module assumes students have basic probability, Bayesian concepts, and multivariate calculus; the authors suggest a brief refresher on partial derivatives for audiences lacking this background.
Materials and Implementation
All teaching assets—lecture slides, in‑class handouts, a Shiny app, and fully commented R code—are provided as supplementary material, enabling instructors to adopt the module with minimal preparation. The authors also include a detailed outline (Table 1) that maps learning objectives to activities, ensuring alignment with active‑learning principles such as scaffolding, collaborative problem solving, and open‑ended questioning.
Impact and Future Directions
By integrating VI into a short, hands‑on module, the paper demonstrates that students can acquire a practical, scalable inference tool without sacrificing conceptual understanding. The approach bridges the gap between traditional Bayesian education (focused on exact conjugacy or MCMC) and the demands of modern data‑intensive applications. The authors envision extending the module to cover richer variational families (e.g., structured variational approximations, normalizing flows) and advanced optimization schemes (natural gradients, stochastic VI) for graduate‑level extensions.
In summary, the paper offers a concrete, reproducible blueprint for teaching variational inference in undergraduate and applied graduate courses, combining theory, interactive visualization, and real‑world case studies to prepare students for contemporary statistical modeling and machine learning challenges.
Comments & Academic Discussion
Loading comments...
Leave a Comment