Post-synaptic potential regularization has potential
Improving generalization is one of the main challenges for training deep neural networks on classification tasks. In particular, a number of techniques have been proposed, aiming to boost the performance on unseen data: from standard data augmentatio…
Authors: Enzo Tartaglione, Daniele Perlo, Marco Grangetto
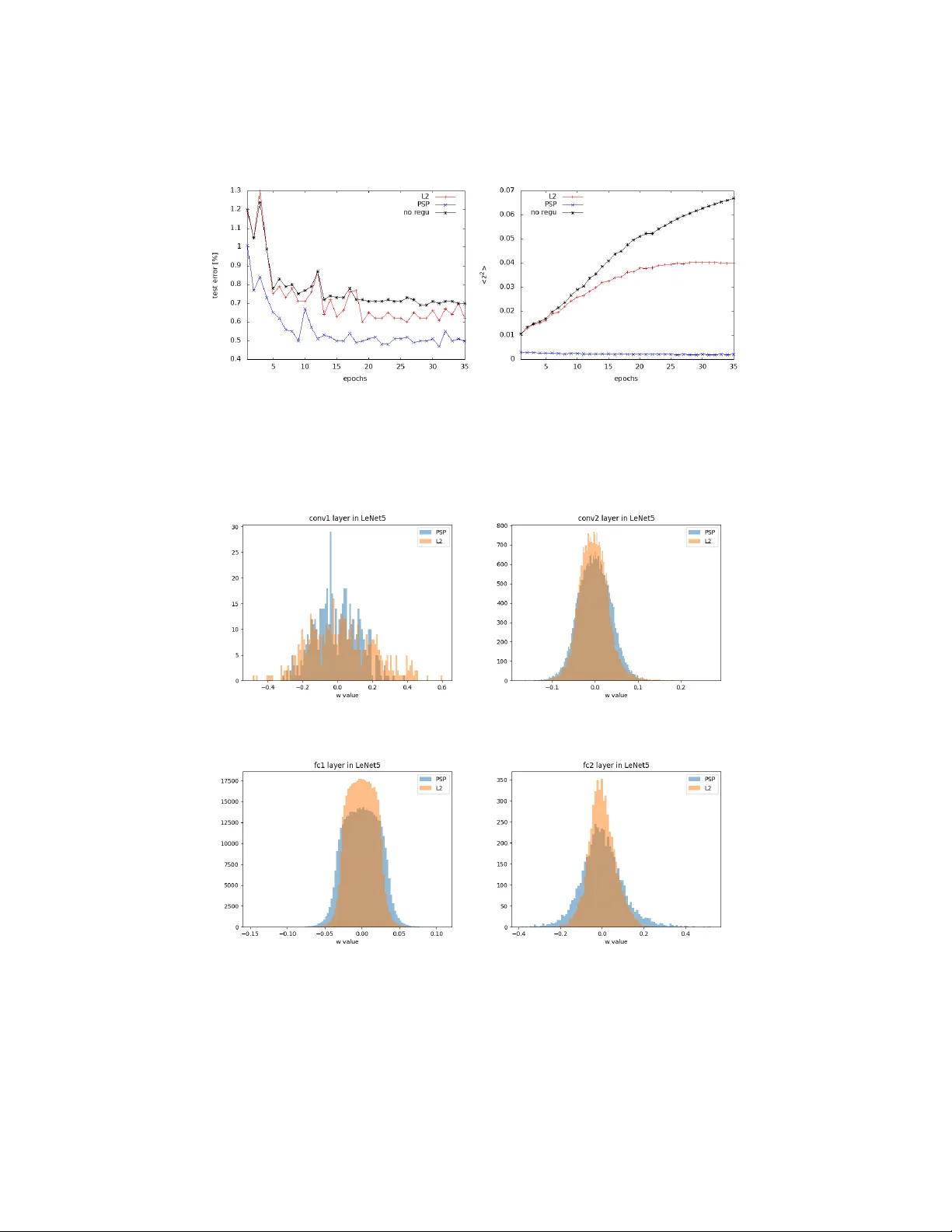
P ost-synaptic p oten tial regularization has p oten tial Enzo T artaglione 1 [0000 − 0003 − 4274 − 8298] , Daniele P erlo 1 , and Marco Grangetto 1 [0000 − 0002 − 2709 − 7864] Univ ersit` a degli studi di T orino, T urin, Italy Abstract. Impro ving generalization is one of the main c hallenges for training deep neural netw orks on classification tasks. In particular, a n umber of tec hniques ha v e been prop osed, aiming to b o ost the perfor- mance on unseen data: from standard data augmentation techniques to the ` 2 regularization, dropout, batch normalization, en tropy-driv en SGD and man y more. In this work we prop ose an elegan t, simple and principled approach: p ost-synaptic potential regularization (PSP). W e tested this regulariza- tion on a num ber of differen t state-of-the-art scenarios. Empirical results sho w that PSP achiev es p erformances comparable to more sophisticated learning strategies in the MNIST scenario, while improv es the general- ization compared to ` 2 regularization in deep arc hitectures trained on CIF AR-10. Keyw ords: Regularization · Generalization · Post-synaptic p oten tial · Neural net works · Classification 1 In tro duction In the last few years artificial neural netw ork (ANN) mo dels received huge in- terest from the research communit y . In particular, their p oten tial capability of solving complex tasks with extremely simple training strategies has been the ini- tial spark, while con volutional neural net works (CNNs), capable of self-extracting relev an t features from images, hav e been the fuel for the burning flame whic h is the research around ANNs. F urthermore, thanks to the ever-in creasing com- putational capabilit y of machines with the in tro duction of GPUs (and, recently , TPUs) in the simulation of neural netw orks, ANNs might be embedded in many p ortable devices and, p oten tially , used in everyda y life. State-of-the-art ANNs are able to learn v ery complex classification tasks: from the now ada ys outdated MNIST [ 15 ], moving to CIF AR-10 and then ev en the ImageNet classification problem. In order to ov ercome the complexit y of these learning tasks, extremely complex architectures hav e b een prop osed: some ex- amples are V GG [ 20 ] and ResNet [ 10 ]. How ever, due to their extremely high n umber of parameters, these mo dels are prone to ov er-fitting the data; hence, they are not able to generalize as they should. In this case, the simple learning strategies (like SGD) are no longer able to guaran tee the netw ork to learn the 2 T artaglione et al. relev an t features from the training set and other strategies need to b e adopted. In order to improv e the generalization of ANNs, several approaches hav e b een prop osed. One of the most t ypical relies on the in tro duction of a “regulariza- tion” term, whose aim is to add an extra constrain t to the o verall ob jectiv e function to b e minimized. Recen tly , other approac hes hav e b een prop osed: from the in tro duction of different optimizers [ 13 ] to data augmentation tec hniques, the prop osal of new techniques like dropout [ 22 ] and even changing the basic arc hitecture of the ANN [ 10 ]. In this work, we prop ose a regularization term inspired by a side effect of the ` 2 regularization (also kno wn ad weight de c ay ) on the parameters. In particular, w e are going to sho w that, naturally , weigh t deca y mak es the post-synaptic p otential dropping to zero in ANN mo dels. F rom this observ ation, a p ost-synaptic p oten- tial regularization (PSP) is here prop osed. Differently from ` 2 regularization, its effect on the parameters is not lo cal: parameters b elonging to la yers closer to the input feel the effect of the regularization on the forward lay ers. Hence, this regularization is aw are of the configuration of the whole netw ork and tunes the parameters using a global information. W e show that the standard ` 2 regular- ization is a sp ecial case of the prop osed regularizer as well. Empirically we show that, when compared to the standard weigh t decay regularization, PSP general- izes b etter. The rest of this pap er is organized as follo ws. In Sec. 2 w e review some of the most relev ant regularization techniques aiming at improving generalization. Next, in Sec. 3 we introduce our prop osed regularization, starting from some simple considerations on the effect of the ` 2 regularization on the p ost synaptic p oten tial and analyzing the p oten tial effects on the learning dynamics. Then, in Sec. 4 we show some empirical results and some extra insights of the prop osed regularization. Finally , in Sec. 5 the conclusions are dra wn. 2 Related w ork Regularization is one of the key features a learning algorithm should particularly tak e care of in deep learning, in order to preven t data ov er-fit and b o osting the generalization [ 8 ]. Even though such a concept is more general and older than the first ANN mo dels [ 24 ], we are going to fo cus on what regularization for deep arc hitectures (trained on finite datasets via sup ervised learning) is. W e can divide the regularization strategies in our con text under four main categories [ 14 ]: – regularization via data : some examples include (but are not limited to) the in tro duction of gaussian noise to the input [ 7 ], dropout to the input [ 22 ], data augmen tation [ 1 ] [ 4 ], batch normalization [ 11 ]. – regularization via network ar chite ctur e : in this case, the architecture is prop- erly selected in order to fit the particular dataset we are aiming to train. It can in volv e the choice of single lay ers (p ooling, conv olutional [ 15 ], drop out [ 22 ]), it can inv olve the insertion of entire blo c ks (residual blo c ks [ 10 ]), the en tire structure can b e designed on-purp ose [ 5 ] [ 2 ] [ 9 ] or even pruned [ 27 ] [ 23 ]. P ost-synaptic p oten tial regularization has p otential 3 – regularization via optimization : an optimizer can determine the nature of the lo cal minima and a v oid “bad” lo cal minima (if an y [ 12 ]), b o osting the gener- alization [ 13 ] [ 3 ]. The initialization also seemed to co v er an imp ortan t role [ 6 ], together with cross-v alidation based techniques like early-stopping [ 18 ]. – regularization via r e gularization term : here a regularization term is added to the loss, and a global ob jective function (sum of loss and regularization term ( 4 ) ) is minimized. This is the scop e of our work. One of the ground-breaking regularization techniques, prop osed few years ago, is dr op out . Sriv av a et al. [ 22 ] prop osed, during the training pro cess, to sto c hasti- cally set a part of the activ ations in an ANN to zero according to an a-priori set drop out probability . Empirically it w as observ ed that, applying dropout on fully- connected architecture, was significantly impro ving the generalization, while its effectiv eness w as less evident in con volutional arc hitectures. Suc h a technique, ho wev er, t ypically requires a longer training time, and sometimes a prop er c hoice of the drop out probability may change the effectiveness of the tec hnique. How- ev er, drop out has many v arian ts aiming to the same goal: one of the most used is drop connect by W an et al. [ 26 ]. A completely differen t approac h to bo ost the generalization is to focus the atten- tion on some regions of the loss functions. It has bee n suggested b y Lin et al. [ 16 ] that “sharp” minima of the loss function do es not generalize as well as “wide” minima. According to this, the design of an optimizer which do es not remain stuc k in sharp minima helps in the generalization. T ow ards this end, some op- timizers like SGD or Adam [ 13 ] are already implicitly lo oking for these kind of solutions. Recently , a sp ecially-purposed optimizer, Entr opy-SGD , designed by Chaudhari et al. [ 3 ], show ed go od generalization results. How ev er, more sophis- ticated optimizers increase the computational complexit y significantly . A regularization technique, prop osed ab out 30 years ago by W eigend et al. and just recently re-disco vered, is weight elimination [ 27 ]: a p enalty term is added to the loss function and the total ob jectiv e function is minimized. The aim of the regularization term is here to estimate the “complexit y” of the mo del, which is minimized together with the loss function. The learning complexity for an ob ject increases with its n umber of parameters: there should exist an optimal n umber of parameters (or, in other words, configuration) for any given classification prob- lem. Supp orting this view, while using their sensitivity-driven r e gularization [ 23 ] aiming to sparsify deep mo dels, T artaglione et al. observed an improv ement of the generalization for lo w compression ratios. An y of the prop osed regularization techniques, ho wev er, is typically used jointly to the ` 2 regularization. Suc h a technique is broadly used during most of the ANN trainings and, despite its simple formulation, under a wide range of differ- en t scenarios, it impro ves the generalization. F urthermore, man y recen t w orks suggest that there is a corresp ondence b et ween ` 2 regularization and other tech- niques: for example, W ager et al. [ 25 ] show ed an equiv alence b et ween drop out and w eight deca y . Is there something else to understand about ` 2 regularization? What’s under the ho od? This will b e our starting p oint, to b e discussed more in details in Sec. 3.2 . 4 T artaglione et al. 3 P ost-synaptic p oten tial regularization In this section we first analyze the effect of weigh t deca y on the output of any neu- ron in an ANN mo del. W e show that ` 2 regularization makes the p ost-synaptic p oten tial drop to zero. Hence, a regularization ov er the p ost-synaptic p oten tial is form ulated (PSP). Next, the parameters up date term is derived and some considerations for m ulti-lay er architectures are drawn. Finally , we show the con- crete effect of p ost-synaptic potential regularization on b oth the output of a single neuron and its parameters. 3.1 Notation Fig. 1: Representation of the k -th neuron of the l -th lay er of an ANN. The input y l − 1 is w eigh ted b y the parameters Θ l,k , passes through some affine function f ( · ) pro ducing the post-synaptic p otential z l,k whic h is fed to the activ ation function ϕ ( · ), pro ducing the output y l,k In this section we introduce the notation to be used in the rest of this work. Let us assume we work with an acyclic, multi-la y er artificial neural net work comp osed of N lay ers, where lay er l = 0 is the input lay er and l = N the output la yer. The ensemble of all the trained parameters in the ANN will b e indicated as Θ . Each of the l la y ers is made of K l neurons (or filters for conv olutional la yers). Hence, the k -th neuron ( k ∈ [1 , K l ]) in the l -th lay er has: – y l,k as its o wn output. – y l − 1 as input v ector. – Θ l,k as its own parameters: w l,k are the weigh ts (from which we iden tify the j -th as w l,k,j ) and b l,k is the bias. P ost-synaptic p oten tial regularization has p otential 5 Eac h of the neurons has its own activ ation function ϕ l,k ( · ) to b e applied after some affine function f l,k ( · ) which can b e conv olution, dot pro duct, adding resid- ual blo cks, batch normalization or any com bination of them. Hence, the output of a neuron can b e expressed by y l,k = ϕ l,k [ f l,k ( θ l,k , y l − 1 )] (1) W e can simplify ( 1 ) if we define the p ost-synaptic p otential (or equiv alen tly , the pre-activ ation p oten tial) z l,k as z l,k = f l,k ( θ l,k , y l − 1 ) (2) As we are going to see, the p ost-synaptic p oten tial will b e cen tral in our metho d and analysis and encloses the true essence of the prop osed regularization strategy . A summary of the in tro duced notation is graphically represented in Fig. 1 . 3.2 Effect of weigh t deca y on the p ost-synaptic p oten tial Most of the learning strategies use the well-kno wn ` 2 regularization term R ` 2 ( Θ ) = 1 2 X l X k X j θ 2 l,k,j (3) Eq. ( 3 ) is minimized together with the loss function L ( · ); hence, the ov erall minimized function is J ( Θ , ˆ y ) = η L ( Θ , ˆ y ) + λR ` 2 ( Θ ) (4) where ˆ y is the desired output and η , λ are p ositive real num b ers, and commonly in range (0 , 1). All the update con tributions are computed using the standard bac k-propagation strategy . Let us fo cus here, for sake of simplicity , on the reg- ularization term ( 3 ). Minimizing it corresp onds to adopt the commonly named weight de c ay strategy for which we hav e the following up date rule: θ t +1 l,k,j := (1 − λ ) θ t l,k,j (5) This generates a p erturbation of the output for the corresponding neuron result- ing in a p erturbation of the p ost-synaptic p oten tial: ∆z l,k = z t +1 l,k − z t l,k (6) Ho w do es the ` 2 regularization affect z l,k ? Clearly , minimizing ( 3 ) means that θ l,k,j → 0 ∀ l , k, j . Now, if we hav e an input pattern for our netw ork y 0 , it is straightforw ard, according to ( 2 ) and ( 5 ), that z l,k → 0, as all the parameters will b e zero. Under this assumption, w e can sa y that the weigh t deca y strategy implicitly aims to fo cus on p eculiar regions of the mostly-used activ ation functions: in the case we use sigmoid or hyp erb olic tangent , w e hav e the maximum v alue for the deriv ativ e for z l,k ≈ 0; while for the ReLU activ ation we are close to the function discon tinuit y . Is this the real essence of weigh t decay and one of the reasons it helps in the generalization? Starting from these v ery simple observ ation, w e are now going to formulate a regularization term whic h explicitly minimizes z l,k . 6 T artaglione et al. 3.3 P ost-synaptic regularization In the previous section we hav e observed that, in the typical deep learning sce- nario, weigh t decay minimizes the p ost-synaptic p oten tial, fo cusing the output of the neuron around some particular regions, whic h might help in the signal bac k-propagation and, indirectly , fav or the generalization. If we wish to explicitly driv e the output y l,k of the neuron, or b etter, its p ost- synaptic p oten tial, w e can imp ose an ` 2 regularization on z l,k : R = 1 2 X l X k ( z l,k ) 2 (7) where k is an index ranging for all the neurons in the l -th lay er. W e can split ( 7 ) for eac h of the k neurons in the l -th lay er: R l,k = 1 2 ( z l,k ) 2 (8) In case we desire to apply the regularization ( 8 ), w e can use the chain rule to c heck what is the up date felt by the parameters of our mo del: ∂ R l,k ∂ θ l,k,j = ∂ R l,k ∂ z l,k · ∂ z l,k ∂ θ l,k,j = z l,k · ∂ z l,k ∂ θ l,k,j (9) Expanding ( 9 ), we hav e ∂ R l,z ∂ θ l,k,j = ∂ z l,k ∂ θ l,k,j · b l,k + X i w l,k,i y ( l − 1 ,i ) ! (10) Here we need to differentiate b et ween bias and weigh t cases: if θ l,k,j is the bias then ( 10 ) can b e easily written as ∂ R l,k ∂ b l,k = b l,k + X i w l,k,i y ( l − 1 ,i ) (11) while, if θ l,k,j is one of the w eights, ∂ R l,k ∂ w l,k,j = ∂ z l,k ∂ w l,k,j · w l,k,j ∂ z l,k ∂ w k,j + b l,k + X i 6 = j w l,k,i y ( l − 1 ,i ) = w l,k,j ∂ z l,k ∂ w l,k,j 2 + ∂ z l,k ∂ w l,k,j b l,k + X i 6 = j w l,k,i y ( l − 1 ,i ) (12) F rom ( 12 ) it is p ossible to reco ver the usual weigh t decay assuming ∂ z l,k ∂ w l,k,j = 1 ∀ l, k , j and completely neglecting the contribution coming from the other pa- rameters for the same neuron. The v ariation in the parameter v alue, according to ( 9 ), is ∆θ l,k,j = − λz l,k ∂ z l,k ∂ θ l,k,j (13) P ost-synaptic p oten tial regularization has p otential 7 where λ ∈ (0 , 1) as usual. As we are minimizing ( 7 ), we can say that z l,k is a b ounded term. F urthermore, looking at y ( l − 1 ,j ) , we need to distinguish tw o cases: – l = 1: in this case, y (0 ,j ) represen ts the input, which we impose to b e a b ounded quantit y . – l 6 = 1: here w e should recall that y ( l − 1 ,j ) is the output of the ( l − 1)-th la yer: if we minimize the post-synaptic potentials also in those lay ers, for the commonly-used activ ation functions, we guarantee it to b e a b ounded quan tity . Hence, as pro duct of b ounded quantities, also ( 13 ) is a limited quantit y . Ho wev er, what w e aim to minimize is not ( 8 ), but the whole summation in ( 7 ). If w e explicitly wish to write what the regularization con tribution to the parameter θ l,k,j is, w e hav e ∂ R p,h ∂ θ l,k,j = z p,h · ∂ z p,h ∂ θ l,k,j (14) Here, three differen t cases can b e analyzed: – p < l : in this case, the gradien t term is ∂ z p,h ∂ θ l,k,j = 0 and the entire contribution is zero. – p = l : here, the gradient term ∂ z p,h ∂ θ l,k,j = y ( l − 1 ,j ) if h = k , zero otherwise. – p > l : this is the most in teresting case: regularization on the last la y ers affects all the previous ones, and such a con tribution is automatically computed using bac k-propagation. Hence, in the most general case, the total up date contribution resulting from the minimization of ( 7 ) on the j -th weigh t b elonging to the k -th neuron at la yer l is indeed ∆θ l,k,j = − λ z l,k ∂ z l,k ∂ θ l,k,j + L X p = l +1 ∂ R p ∂ θ l,k,j (15) where ∂ z l,k ∂ θ l,k,j = 1 if θ l,k,j is bias y ( l − 1 ,j ) if θ l,k,j is w eight (16) In this section we hav e prop osed a p ost-synaptic p oten tial regularization which explicitly minimizes z l,k in all the neurons of the ANN. In particular, we hav e observ ed that the up date term for the single parameter employs a global in- formation coming from forward lay ers, fav oring the regularization. In the next section, results from some simulations in which PSP regularization is tested are sho wn. 8 T artaglione et al. 4 Exp erimen ts In this section w e show the p erformance reac hed b y some of the mostly-used ANNs with our p ost-synaptic p oten tial regularization (PSP) and we compare it to the results obtained with weigh t decay . W e hav e tested our regularization on three different datasets: MNIST, F ashion-MNIST and CIF AR-10 on LeNet5, ResNet-18 [ 10 ], MobileNet v2 [ 19 ] and All-CNN-C [ 21 ]. All the simulationsare p erformed using the standard SGD with CUD A 8 on a Nvidia T esla P-100 GPU. Our regularization has b een implemented using PyT orch 1.1. 1 4.1 Sim ulations on MNIST As very first exp erimen ts, we attempted to train the well-kno wn LeNet-5 mo del o ver the standard MNIST dataset [ 15 ] (60k training images and 10k test im- ages, all the images are 28x28 pixels, grey-scale). W e use SGD with a learning parameter η = 0 . 1, minibatch size 100. In Fig. 2a , w e show a typically observed scenario in our exp erimental setting, where we compare standard SGD with no regularization, the effect of ` 2 regularization ( λ = 1 e − 4) and our pre-activ ation signal potential regularization (PSP , λ = 0 . 001). While the w eigh t decay a v erage p erformance is 0.64% (showing improv emen ts from the standard SGD, which is ab out 0.71%), PSP final performance is ab out 0.50%, with p eaks reac hing 0.46%. W e would like to emphasize that, to the b est of our knowledge, we hit the b est ev er recorded performance for the current dataset with the same arc hitecture [ 3 ]. W e find interesting the b eha vior of z 2 for all the three techniques (Fig. 2b ). In the case of standard SGD, the av eraged z 2 v alue, as it is not con trolled, t ypically gro ws un til the gradient on the loss will not b e zero. F or ` 2 regular- ization, interestingly , it slowly grows until it reaches a final plateau. Finally , in PSP regularization, the z 2 v alue is extremely low, and still slowly decreases. According to the results in Fig. 2a , this is helping in the generalization. A t this p oin t w e can hav e a further look at what is happ ening at the level of the distribution of the parameters lay er-b y-lay er. A typical trained parameters distribution for LeNet5, trained on MNIST, is shown in Fig. 3 . While ` 2 regu- larization typically shrinks the parameters around zero, PSP regularization do es not constrain the parameters with the same strength, while still constrains the pre-activ ation signal (Fig. 2b ). How ever, contrarily to this, the first conv olu- tional lay er, with ` 2 regularization, is less constrained around zero than with PSP (Fig. 3a ). Such a b ehavior can b e explained by ( 15 ): all the regularization con tributions coming from all the forw ard lay ers (in this case, con v2, fc1 and fc2) affect the parameters in con v1, whic h are directly conditioning all the z computed in forw ard lay ers. 1 All the source co de is publicly av ailable at https://gith ub.com/enzotarta/PSP P ost-synaptic p oten tial regularization has p otential 9 (a) Error on the test set (b) Av erage of z 2 v alues Fig. 2: Performance comparison in LeNet5 trained on MNIST (same initialization seed): standard SGD (no regu), ` 2 regularization and post synaptic p oten tial regularization (PSP) (a) First conv olutional lay er (conv1) (b) Second con volutional lay er (conv2) (c) First fullyconnected lay er (fc1) (d) Output la yer (fc2) Fig. 3: Distribution of the parameters in a LeNet5 trained on MNIST with ` 2 regularization ( ` 2 ) and with p ost synaptic p oten tial regularization (PSP) 10 T artaglione et al. 4.2 Sim ulations on F ashion-MNIST W e hav e decided, as a further step, to test LeNet-5 on a more complex dataset: hence, we hav e chosen the F ashion-MNIST dataset [ 28 ]. It is made of 10 classes of 28x28 grey-scale images represen ting v arious pieces of clothing. They are divided in 60k examples for the training set and 10k for the test set. Such a dataset has t wo main adv an tages: the problem dimensionality (input, output) is the same as MNIST; hence, the same ANN can b e used for b oth problems, and it is not as trivial as MNIST to solve. T raining results are sho wn in T able 1 . The sim ulations T able 1: LeNet-5 on F ashion-MNIST. T echnique T est set error[%] SGD+ ` 2 8.9 SGD+PSP 8.0 are p erformed with η = 0 . 1, batch size 100 and λ = 0 . 0001 for ` 2 regularization while λ = 0 . 001 for PSP . Here, the difference in the generalization b etw een ` 2 and PSP is wider than the one presented for MNIST: w e are able, with the same arc hitecture, to improv e the p erformance b y around the 1% without any other heuristics. 4.3 Sim ulations on CIF AR-10 Mo ving tow ards deep architectures, we decided to use CIF AR-10 as dataset. It is made of 32x32 color images (3 channels) divided in 10 classes. The training set is made of 50k images and the test set of 10k samples. This dataset is a go od compromise to make the first tests on deep architectures as the training is p erformed from scratch. Three conv olutional architectures ha ve b een here tested: MobileNet v2 [ 19 ], ResNet-18 [ 10 ] and All-CNN-C [ 21 ]. In order to separate the contribution of our regularizer tow ards other state-of-the-art regularizers, we are going to com- pare our results with our baseline (same data augmen tation, no drop out). All these net works were pre-trained with η = 0 . 1 for 150 ep ochs and then learning rate decay p olicy was applied (drop to 10% ev ery 100 ep o c hs) for 300 ep ochs. Minibatc h size was set to 128 and momentum to 0 . 9. F or standard training, the ` 2 λ w as set to 5 e − 4 while for PSP regularization to 0 . 001. As we can observ e in T able 2 , using PSP-based regularization sho ws improv e- men ts from the baseline and from ` 2 regularization. W e speculate that with a prop er setting of λ , PSP can p oten tially match, or even ov ercome, top p erfor- mance mark ed by state-of-the-art regularizers. P ost-synaptic p oten tial regularization has p otential 11 T able 2: P erformances on CIF AR-10 Arc hitecture Baseline test error[%] PSP test error [%] ResNet-18 5.1 4.6 MobileNet v2 7.0 6.4 All-CNN-C 9.1 8.6 5 Conclusion In this work we hav e prop osed a post-synaptic p otential regularizer for sup er- vised learning problems. Starting from the observ ation that weigh t decay indi- rectly shrinks the p ost-synaptic p otential to zero, w e hav e formulated the new PSP regularization. Contrarily to weigh t deca y , it uses a global information com- ing from other parameters affecting the p ost-synaptic p oten tial. W e ha ve also sho wn that ` 2 regularization is a sp ecial case of our PSP regularization. Lo oking at the computational complexity , if the autograd [ 17 ] pack age is used for back- propagation, no significan t computational ov erhead is added. Empirical results sho w that PSP regularization impro ves the generalization on b oth simple and more complex problems, bo osting the p erformance also on deep arc hitectures. F uture work includes the application of PSP to recurren t neu- ral net w orks, tests on netw orks using non-linear activ ation functions and the definition of a prop er decay p olicy for PSP regularization. References 1. Calimeri, F., Marzullo, A., Stamile, C., T erracina, G.: Biomedical data augmenta- tion using generative adversarial neural netw orks. In: International conference on artificial neural net works. pp. 626–634. Springer (2017) 2. Caruana, R.: Multitask learning. Machine learning 28 (1), 41–75 (1997) 3. Chaudhari, P ., Choromansk a, A., Soatto, S., LeCun, Y., Baldassi, C., Borgs, C., Cha yes, J., Sagun, L., Zecchina, R.: En tropy-sgd: Biasing gradient descent into wide v alleys. arXiv preprint arXiv:1611.01838 (2016) 4. Cui, X., Go el, V., Kingsbury , B.: Data augmentation for deep neural net w ork acous- tic mo deling. IEEE/ACM T ransactions on Audio, Sp eec h and Language Pro cessing (T ASLP) 23 (9), 1469–1477 (2015) 5. Elsk en, T., Metzen, J.H., Hutter, F.: Neural architecture search: A survey . arXiv preprin t arXiv:1808.05377 (2018) 6. Glorot, X., Bengio, Y.: Understanding the difficulty of training deep feedforward neural netw orks. In: Pro ceedings of the thirteenth international conference on ar- tificial in telligence and statistics. pp. 249–256 (2010) 7. Goldb erg, P .W., Williams, C.K., Bishop, C.M.: Regression with input-dep enden t noise: A gaussian pro cess treatmen t. In: Adv ances in neural information pro cessing systems. pp. 493–499 (1998) 8. Go odfellow, I., Bengio, Y., Courville, A.: Deep learning. MIT press (2016) 9. Gulcehre, C., Mo czulski, M., Visin, F., Bengio, Y.: Mollifying net works. arXiv preprin t arXiv:1608.04980 (2016) 12 T artaglione et al. 10. He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Pro ceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016) 11. Ioffe, S., Szegedy , C.: Batch normalization: Accelerating deep netw ork training by reducing in ternal cov ariate shift. arXiv preprint arXiv:1502.03167 (2015) 12. Ka waguc hi, K.: Deep learning without p oor lo cal minima. In: Adv ances in neural information pro cessing systems. pp. 586–594 (2016) 13. Kingma, D.P ., Ba, J.: Adam: A method for sto c hastic optimization. arXiv preprin t arXiv:1412.6980 (2014) 14. Kuk ac k a, J., Golko v, V., Cremers, D.: Regularization for deep learning: A taxon- om y . CoRR abs/1710.10686 (2017), 15. LeCun, Y., Bottou, L., Bengio, Y., Haffner, P ., et al.: Gradient-based learning ap- plied to do cumen t recognition. Pro ceedings of the IEEE 86 (11), 2278–2324 (1998) 16. Lin, H.W., T egmark, M., Rolnick, D.: Why do es deep and cheap learning work so w ell? Journal of Statistical Physics 168 (6), 1223–1247 (2017) 17. Maclaurin, D., Duvenaud, D., Adams, R.P .: Autograd: Effortless gradien ts in n umpy . In: ICML 2015 AutoML W orkshop (2015) 18. Prec helt, L.: Automatic early stopping using cross v alidation: quantifying the cri- teria. Neural Net works 11 (4), 761–767 (1998) 19. Sandler, M., How ard, A., Zhu, M., Zhmoginov, A., Chen, L.C.: Mobilenetv2: In- v erted residuals and linear b ottlenec ks. In: Pro ceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 4510–4520 (2018) 20. Simon yan, K., Zisserman, A.: V ery deep con volutional net works for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014) 21. Springen b erg, J.T., Dosovitskiy , A., Brox, T., Riedmiller, M.: Striving for simplic- it y: The all conv olutional net. arXiv preprint arXiv:1412.6806 (2014) 22. Sriv asta v a, N., Hin ton, G., Krizhevsky , A., Sutsk ever, I., Salakhutdino v, R.: Drop out: a simple wa y to preven t neural netw orks from ov erfitting. The Journal of Mac hine Learning Research 15 (1), 1929–1958 (2014) 23. T artaglione, E., Lepsøy , S., Fiandrotti, A., F rancini, G.: Learning sparse neural net works via sensitivity-driv en regularization. In: Adv ances in Neural Information Pro cessing Systems. pp. 3882–3892 (2018) 24. Tikhono v, A.N.: On the stability of inv erse problems. In: Dokl. Ak ad. Nauk SSSR. v ol. 39, pp. 195–198 (1943) 25. W ager, S., W ang, S., Liang, P .S.: Drop out training as adaptive regularization. In: Adv ances in neural information pro cessing systems. pp. 351–359 (2013) 26. W an, L., Zeiler, M., Zhang, S., Le Cun, Y., F ergus, R.: Regularization of neural net works using drop connect. In: International conference on machine learning. pp. 1058–1066 (2013) 27. W eigend, A.S., Rumelhart, D.E., Huberman, B.A.: Bac k-propagation, weigh t- elimination and time series prediction. In: Connectionist models, pp. 105–116. Elsevier (1991) 28. Xiao, H., Rasul, K., V ollgraf, R.: F ashion-mnist: a no vel image dataset for b enc h- marking mac hine learning algorithms (2017)
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment