Time-Domain Audio Source Separation Based on Wave-U-Net Combined with Discrete Wavelet Transform
We propose a time-domain audio source separation method using down-sampling (DS) and up-sampling (US) layers based on a discrete wavelet transform (DWT). The proposed method is based on one of the state-of-the-art deep neural networks, Wave-U-Net, which successively down-samples and up-samples feature maps. We find that this architecture resembles that of multiresolution analysis, and reveal that the DS layers of Wave-U-Net cause aliasing and may discard information useful for the separation. Although the effects of these problems may be reduced by training, to achieve a more reliable source separation method, we should design DS layers capable of overcoming the problems. With this belief, focusing on the fact that the DWT has an anti-aliasing filter and the perfect reconstruction property, we design the proposed layers. Experiments on music source separation show the efficacy of the proposed method and the importance of simultaneously considering the anti-aliasing filters and the perfect reconstruction property.
💡 Research Summary
The paper addresses a fundamental limitation of the popular time‑domain source separation network Wave‑U‑Net: its down‑sampling (DS) blocks are implemented as simple decimation (stride‑2 convolution or pooling) without any low‑pass filtering, which introduces aliasing and discards potentially useful high‑frequency information. While training can partially compensate for these defects, the authors argue that a more principled design is needed.
By observing that the encoder‑decoder architecture of Wave‑U‑Net closely resembles the structure of a multi‑resolution analysis (MRA) performed by the discrete wavelet transform (DWT), they propose to replace the conventional DS and up‑sampling (US) blocks with DWT‑based layers. A DWT layer first splits each feature map into even and odd samples, predicts the odd samples from the even ones (high‑pass filtering), computes the error, updates the even samples with this error (low‑pass filtering), and finally scales both sub‑bands. The resulting low‑ and high‑frequency sub‑bands are concatenated along the channel dimension, halving the temporal resolution while doubling the channel count. The inverse DWT (iDWT) layer reverses this process, guaranteeing perfect reconstruction of the original feature map. Because DWT inherently includes anti‑aliasing filters and satisfies the perfect reconstruction property, the proposed DS/US blocks avoid the aliasing artifacts and information loss of the original design.
The authors implement the DWT and iDWT using the Haar wavelet via the lifting scheme, which requires only simple additions, subtractions, and scaling operations that are highly parallelizable on GPUs. They integrate these layers into the Wave‑U‑Net encoder‑decoder, preserving the skip‑connections and overall depth (12 levels) while adjusting channel sizes to keep the model comparable in capacity.
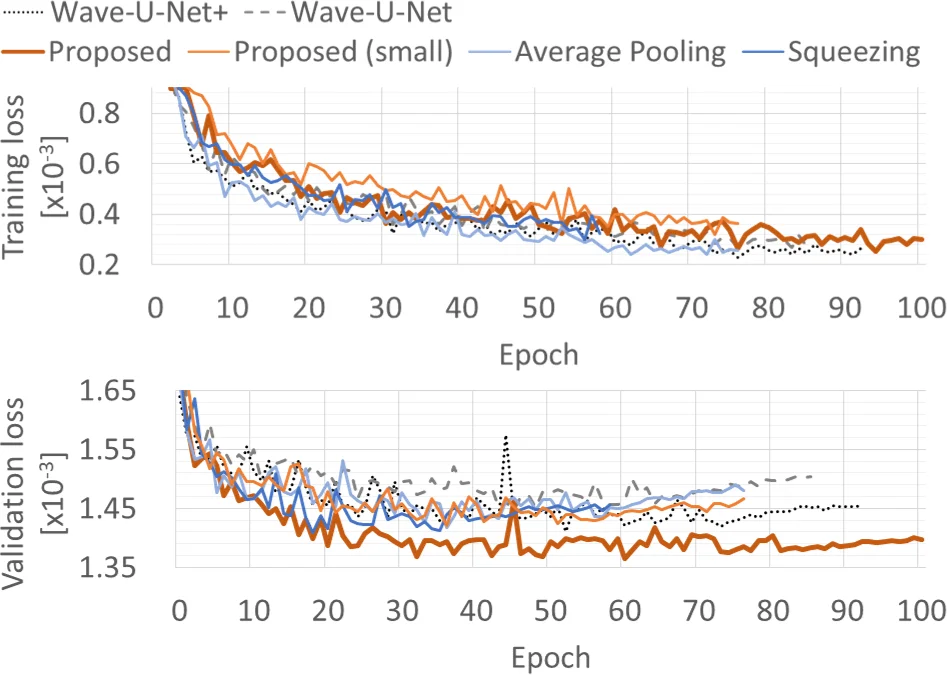
Experiments are conducted on the MUSDB18 dataset (22.05 kHz stereo mixes of 100 training and 50 test songs). Four source categories—bass, drums, vocals, and other—are separated. The proposed model (15.15 M parameters) is compared against the original Wave‑U‑Net (10.26 M), an enlarged Wave‑U‑Net+ (28.31 M), and two ablation variants that isolate the effects of anti‑aliasing (average pooling) and perfect reconstruction (squeezing). Evaluation uses the standard signal‑to‑distortion ratio (SDR) metric, reporting both median and mean values over five runs.
Results show that the proposed model consistently outperforms the baseline Wave‑U‑Net despite having roughly half the parameters of Wave‑U‑Net+. The gains are most pronounced for bass and drums (≈0.2–0.3 dB improvement), with comparable performance for vocals and other instruments. The average‑pooling and squeezing variants perform worse, confirming that both anti‑aliasing filtering and perfect reconstruction are essential for the observed improvements.
The paper concludes that incorporating DWT‑based DS/US layers into time‑domain separation networks yields a more reliable architecture that preserves high‑frequency content and avoids aliasing without sacrificing computational efficiency. Limitations include the exclusive use of Haar wavelets; future work will explore other wavelet families, multi‑level decompositions, and model compression techniques to enable real‑time deployment. The proposed approach is generic and can be applied to other deep audio or even image processing networks that rely on down‑sampling operations.
Comments & Academic Discussion
Loading comments...
Leave a Comment