A Fully Time-domain Neural Model for Subband-based Speech Synthesizer
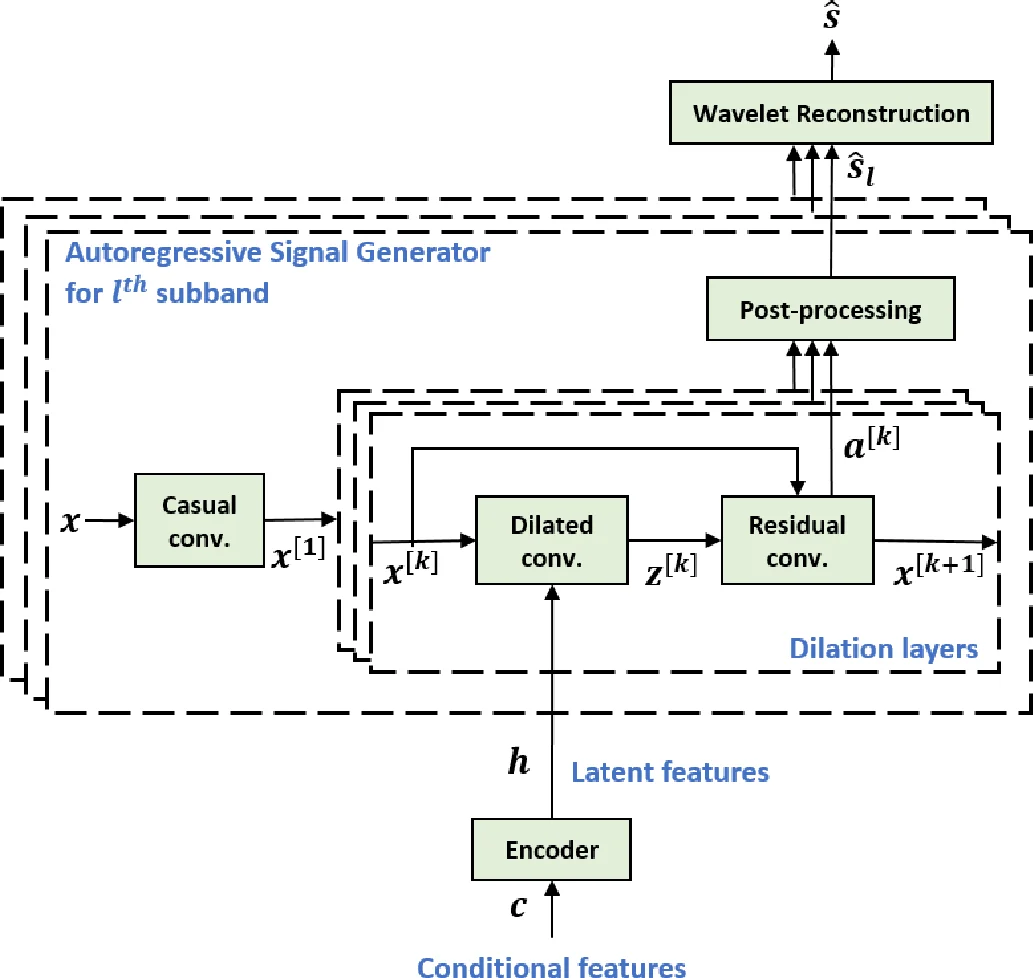
This paper introduces a deep neural network model for subband-based speech synthesizer. The model benefits from the short bandwidth of the subband signals to reduce the complexity of the time-domain speech generator. We employed the multi-level wavelet analysis/synthesis to decompose/reconstruct the signal into subbands in time domain. Inspired from the WaveNet, a convolutional neural network (CNN) model predicts subband speech signals fully in time domain. Due to the short bandwidth of the subbands, a simple network architecture is enough to train the simple patterns of the subbands accurately. In the ground truth experiments with teacher-forcing, the subband synthesizer outperforms the fullband model significantly in terms of both subjective and objective measures. In addition, by conditioning the model on the phoneme sequence using a pronunciation dictionary, we have achieved the fully time-domain neural model for subband-based text-to-speech (TTS) synthesizer, which is nearly end-to-end. The generated speech of the subband TTS shows comparable quality as the fullband one with a slighter network architecture for each subband.
💡 Research Summary
The paper proposes a novel time‑domain subband speech synthesizer that leverages multi‑level wavelet decomposition to split a full‑band audio waveform into several narrow‑band sub‑signals, each of which is generated by a lightweight convolutional neural network inspired by WaveNet. By using Daubechies‑db10 wavelets with eight decomposition levels, the authors obtain eight subband streams without down‑sampling, preserving the original sample rate while drastically reducing the spectral bandwidth of each stream. This reduction in bandwidth allows each subband generator to be much simpler than a full‑band WaveNet: only five dilated convolution layers (dilations 1, 2, 4, 8, 16) are employed per subband, compared with the 24‑layer, four‑stack configuration used for the full‑band baseline.
The conditional input to the system is a phoneme sequence derived from text normalization and the CMU pronunciation dictionary, encoded into a 70‑dimensional vector. An encoder consisting of three 1‑D convolutional layers (kernel size 5, 256 channels) processes this sequence into latent features h, which are shared across all subband generators. This shared encoder acts as an implicit linguistic model, eliminating the need for a separate acoustic model and enabling an almost end‑to‑end text‑to‑speech pipeline. Experiments show that removing the encoder degrades performance markedly, confirming its importance.
Training minimizes the sum of cross‑entropy losses over all subbands, encouraging each generator to learn the conditional probability distribution of its own waveform samples given past samples and the shared latent features. During teacher‑forcing evaluation, the model receives the ground‑truth previous samples, achieving a signal‑to‑noise ratio (SNR) of 23.5 dB, spectral distortion (SD) of 4.3 dB, and mel‑spectral distortion (MSD) of 2.5 dB—substantially better than the full‑band counterpart (SNR 18.8 dB, SD 8.1 dB, MSD 5.5 dB). In free synthesis (where the model feeds back its own generated samples), both subband and full‑band systems perform worse due to the lack of richer acoustic conditioning, yet the subband model remains competitive.
Objective metrics confirm that the wavelet analysis/reconstruction alone yields near‑perfect fidelity (≈41 dB SNR), demonstrating that the decomposition does not introduce perceptible artifacts. The proposed architecture also benefits from parallelism: each subband can be processed independently, reducing overall computational load despite the inherent sequential nature of autoregressive generation.
The authors discuss limitations, notably the still‑sequential sample‑wise generation which hampers real‑time synthesis speed. They suggest future extensions such as incorporating speaker identity, prosody, or noise conditions into the latent vector, and exploring non‑autoregressive or normalizing‑flow based decoders to achieve faster inference.
In summary, this work shows that combining wavelet‑based subband decomposition with a compact, shared‑encoder WaveNet‑style generator yields a fully time‑domain TTS system that is both computationally efficient and capable of high‑quality speech synthesis, offering a promising alternative to large‑scale full‑band neural vocoders.
Comments & Academic Discussion
Loading comments...
Leave a Comment