Memory-assisted Statistically-ranked RF Beam Training Algorithm for Sparse MIMO
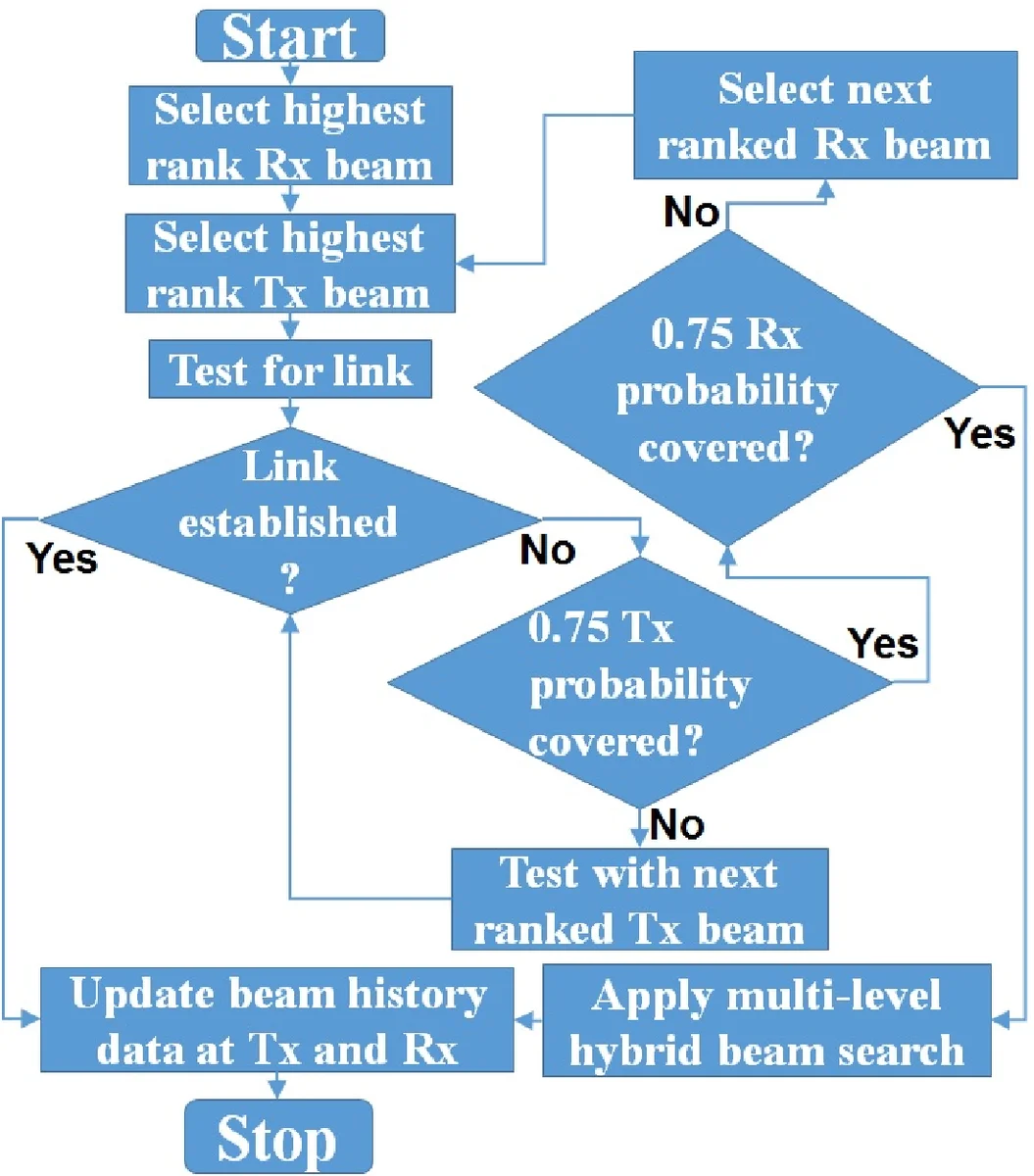
This paper presents a novel radio frequency (RF) beam training algorithm for sparse multiple input multiple output (MIMO) channels using unitary RF beamforming codebooks at transmitter (Tx) and receiver (Rx). The algorithm leverages statistical knowledge from past beam data for expedited beam search with statistically-minimal training overheads. Beams are tested in the order of their ranks based on their probabilities for providing a communication link. For low beam entropy scenarios, statistically-ranked beam search performs excellent in reducing the average number of beam tests per Tx-Rx beam pair identification for a communication link. For high beam entropy cases, a hybrid algorithm involving both memory-assisted statistically-ranked (MarS) beam search and multi-level (ML) beam search is also proposed. Savings in training overheads increase with decrease in beam entropy and increase in MIMO channel dimensions.
💡 Research Summary
The paper introduces a novel RF beam‑training algorithm tailored for sparse multiple‑input multiple‑output (MIMO) channels, where the number of dominant multipath components (MPCs) is far smaller than the antenna array dimensions. Traditional exhaustive beam search tests every possible transmitter (Tx)–receiver (Rx) beam pair, leading to prohibitive training overhead, while hierarchical or multi‑level (ML) beam search reduces the number of tests by progressively narrowing the search space but suffers from low beam gain in the early stages, which is problematic for low‑SNR or long‑range scenarios.
The authors propose a memory‑assisted statistically‑ranked (MarS) algorithm that exploits statistical knowledge accumulated from previous beam‑training sessions. Each beam is assigned a probability pᵢ of establishing a link, derived from historical RSSI measurements. From these probabilities the beam entropy E = −∑pᵢ log pᵢ is computed; low entropy indicates that a few beams dominate the probability mass. The beams are then ranked in descending order of pᵢ and tested sequentially, starting with the highest‑ranked beam on the side (Tx or Rx) that has the lower entropy. A cumulative‑probability threshold (e.g., 0.75) determines when to stop the ranked search and switch to an ML procedure for the remaining low‑probability beams. All failed Tx‑Rx combinations are stored in memory (or cache) so they are never re‑tested, further reducing overhead.
Mathematically, the ranked probability vectors for Rx (r) and Tx (t) are combined via a Kronecker product k = r ⊗ t. An operator “op” multiplies each element of k by its position index, producing a weighted vector x. The average number of beam tests required to discover the first viable Tx‑Rx pair is then m = ∑x. In the illustrative example with 9 Tx beams and 3 Rx beams, m ≈ 4.7, compared with 27 tests for exhaustive search and 12 for pure ML. This corresponds to an 82.6 % reduction relative to exhaustive search and a 60.8 % reduction relative to ML.
For high‑entropy cases—where the beam probability distribution is close to uniform—the pure MarS approach becomes inefficient. The authors therefore propose a hybrid scheme that combines multiple levels of statistically‑ranked searches with ML refinement. In the first level, several narrow beams are merged to form broader beams with artificially lowered entropy, preserving high antenna gain while still limiting the number of candidates. Subsequent levels apply the same ranking principle, and when the cumulative probability exceeds the threshold, the algorithm falls back to an ML tree search. This hybrid method retains the high‑gain advantage of exhaustive testing while achieving the test‑count efficiency of hierarchical search.
Simulation results are obtained via MATLAB Monte‑Carlo experiments. The authors assume a lifetime of 1 × 10⁶ beam‑training operations, reflecting a realistic deployment scenario. Using the probability mass functions (PMFs) listed in Tables I and II (a typical indoor VR use case where users start near the room centre and rotate slowly), the MarS algorithm achieves a 57 % success probability within the first two tests (joint probability of Rx R2 and Tx T5 equals 0.75 × 0.57 = 0.4275). The average number of tests per successful pair is 1.25 for the first two attempts, and overall the average per pair is 4.7. Compared with exhaustive (27 × 10⁶ total tests) and pure ML (12 × 10⁶ total tests) over the system lifetime, MarS reduces the total number of tests to 4.7 × 10⁶, yielding the aforementioned percentage savings.
The paper also discusses practical considerations. The memory requirement is modest because only failed beam combinations need to be cached until the training session completes. The algorithm can be implemented with unitary DFT codebooks on uniform linear arrays (ULAs), but the authors note that extension to 2‑D planar arrays is straightforward. They also highlight that beam‑to‑beam correlation, if present, could be exploited to further prune the search space.
In the concluding section, the authors outline future research directions: (i) incorporating beam correlation statistics, (ii) extending the framework to non‑unitary or adaptive codebooks, (iii) real‑time updating of the probability tables as the environment evolves, and (iv) hardware validation on mmWave/THz testbeds. Overall, the work demonstrates that leveraging historical beam statistics can dramatically cut training overhead while preserving the high antenna gain needed for long‑range, high‑frequency links such as mmWave/THz backhaul or indoor VR/AR communications.
Comments & Academic Discussion
Loading comments...
Leave a Comment