DNN-Based Speech Presence Probability Estimation for Multi-Frame Single-Microphone Speech Enhancement
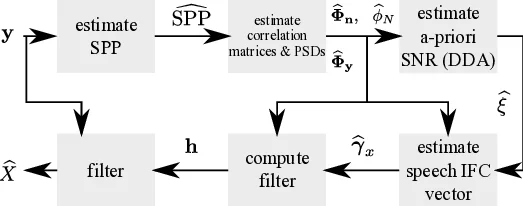
Multi-frame approaches for single-microphone speech enhancement, e.g., the multi-frame minimum-power-distortionless-response (MFMPDR) filter, are able to exploit speech correlations across neighboring time frames. In contrast to single-frame approaches such as the Wiener gain, it has been shown that multi-frame approaches achieve a substantial noise reduction with hardly any speech distortion, provided that an accurate estimate of the correlation matrices and especially the speech interframe correlation (IFC) vector is available. Typical estimation procedures of the IFC vector require an estimate of the speech presence probability (SPP) in each time-frequency (TF) bin. In this paper, we propose to use a bi-directional long short-term memory deep neural network (DNN) to estimate the SPP for each TF bin. Aiming at achieving a robust performance, the DNN is trained for various noise types and within a large signal-to-noise-ratio range. Experimental results show that the MFMPDR in combination with the proposed data-driven SPP estimator yields an increased speech quality compared to a state-of-the-art model-based SPP estimator. Furthermore, it is confirmed that exploiting interframe correlations in the MFMPDR is beneficial when compared to the Wiener gain especially in adverse scenarios.
💡 Research Summary
The paper addresses a critical bottleneck in single‑microphone speech enhancement using the multi‑frame minimum‑power distortionless‑response (MFMPDR) filter: the need for an accurate estimate of the speech inter‑frame correlation (IFC) vector and the associated correlation matrices. Conventional approaches obtain the required speech presence probability (SPP) either through maximum‑likelihood estimation or by assuming complex‑Gaussian statistics for the speech and noise STFT coefficients. However, because the speech IFC varies rapidly across short STFT frames, these model‑based SPP estimators become unreliable, leading to degraded MFMPDR performance.
To overcome this limitation, the authors propose a data‑driven SPP estimator based on a bidirectional long short‑term memory (BLSTM) deep neural network (DNN). The DNN receives as input the magnitude spectrogram of the noisy signal (|Y(k,l)|) and outputs a per‑time‑frequency (TF) SPP estimate. The network architecture consists of an input layer with 33 nodes (corresponding to the number of frequency bins), two BLSTM layers each with 256 hidden units, two fully connected layers with 513 units, and a final 33‑node sigmoid output layer. ReLU activations are used in the hidden layers, and the sigmoid ensures the output lies in the interval (0, 1).
Training data are generated from the WSJ0 speech corpus mixed with noises from the NOISEX‑92 database at signal‑to‑noise ratios (SNRs) ranging from 0 dB to 20 dB. A variety of noise types (white, babble, street, office, etc.) are included to promote robustness. The target SPP values are computed analytically from the theoretical expression (Eq. 25 in the paper), which depends on the a‑priori SNR and the noise power spectral density (PSD). The loss function is the mean‑squared error between the DNN output and the target SPP, and the network weights are initialized with a uniform distribution.
The estimated SPP is employed in two crucial steps of the MFMPDR pipeline. First, it modulates the smoothing factor λ_n(l) used in the recursive estimation of the noise covariance matrix Φ_n(l): λ_n(l) = α_n + (1 − α_n)·SPP(l). This makes the noise PSD estimate more responsive when speech is present and more stable when speech is absent. Second, the SPP‑driven a‑priori SNR ξ(l) is combined with the noisy IF‑correlation γ_y(l) to compute the speech IF‑correlation γ_x(l) via equations analogous to (12), (22), and (23) in the manuscript. With γ_x(l) and the total covariance Φ_y(l) the MFMPDR filter coefficients are obtained as h_MFMPDR = Φ_y⁻¹ γ_x γ_xᴴ Φ_y⁻¹ γ_x, which minimizes output PSD while preserving the speech component.
Experimental evaluation compares three configurations: (i) MFMPDR with the proposed DNN‑based SPP, (ii) MFMPDR with a state‑of‑the‑art model‑based SPP estimator (derived from a complex‑Gaussian assumption), and (iii) a conventional Wiener gain (WG) processor. Objective metrics include PESQ, STOI, and SNR improvement. Tests are performed on both matched and mismatched noise conditions, covering a range of SNRs down to 0 dB. The DNN‑based approach consistently outperforms the model‑based SPP and the Wiener gain, achieving PESQ gains of 0.3–0.5 points, STOI improvements of 0.04–0.07, and SNR gains of 3–5 dB, especially in adverse scenarios where the noise PSD changes rapidly. The model‑based SPP suffers from inaccurate noise PSD estimates, leading to distorted IFC vectors and consequently higher speech distortion.
Limitations are acknowledged: when the test SNR falls far below the training range (e.g., –10 dB) or when encountering highly non‑stationary, non‑speech noises such as music or alarm tones, performance degrades. Moreover, the BLSTM network incurs non‑trivial computational load, which may be prohibitive for low‑power embedded devices without further model compression or pruning.
Future work suggested includes extending the framework to multi‑channel microphone arrays, incorporating online adaptation to track changing acoustic conditions, and exploring more efficient sequence models such as Transformers or lightweight convolutional networks to reduce latency and memory footprint while preserving the robustness demonstrated by the proposed DNN‑based SPP estimator.
Comments & Academic Discussion
Loading comments...
Leave a Comment