Optimizing Multi-GPU Parallelization Strategies for Deep Learning Training
Deploying deep learning (DL) models across multiple compute devices to train large and complex models continues to grow in importance because of the demand for faster and more frequent training. Data parallelism (DP) is the most widely used parallelization strategy, but as the number of devices in data parallel training grows, so does the communication overhead between devices. Additionally, a larger aggregate batch size per step leads to statistical efficiency loss, i.e., a larger number of epochs are required to converge to a desired accuracy. These factors affect overall training time and beyond a certain number of devices, the speedup from leveraging DP begins to scale poorly. In addition to DP, each training step can be accelerated by exploiting model parallelism (MP). This work explores hybrid parallelization, where each data parallel worker is comprised of more than one device, across which the model dataflow graph (DFG) is split using MP. We show that at scale, hybrid training will be more effective at minimizing end-to-end training time than exploiting DP alone. We project that for Inception-V3, GNMT, and BigLSTM, the hybrid strategy provides an end-to-end training speedup of at least 26.5%, 8%, and 22% respectively compared to what DP alone can achieve at scale.
💡 Research Summary
The paper addresses the well‑known scalability limits of pure data parallelism (DP) in deep‑learning training on multi‑GPU systems. While DP replicates the whole model on each device and processes independent mini‑batches, it suffers from two intertwined problems as the number of GPUs grows: (1) the all‑reduce communication required to average gradients becomes a dominant overhead, reducing the scaling efficiency SEₙ; (2) the global batch size increases proportionally to the number of devices, which often degrades statistical efficiency, leading to a larger number of epochs (E₁/Eₙ < 1) needed to reach the target accuracy. Consequently, the overall speedup of DP alone, S_Uⁿ = SEₙ × n × (E₁/Eₙ), plateaus or even declines beyond a certain device count.
Model parallelism (MP) offers a complementary avenue: the computational graph of a network is split across several GPUs, allowing a single mini‑batch to be processed concurrently. This reduces the per‑step time T directly, yielding a per‑step speedup S_Uᵐ that already includes the intra‑model communication cost. However, MP alone is rarely scalable because most modern networks have limited intra‑graph parallelism, and the communication between split partitions can offset the gains.
The authors propose a hybrid strategy that combines DP and MP. They consider a total of M × N GPUs, organized as N data‑parallel workers, each of which internally uses M‑way model parallelism. In this configuration the global batch size remains the same as in pure DP with N workers, so the number of steps per epoch (S) and the number of epochs required for convergence (E) are unchanged. The overall speedup becomes S_U^{M,N} = S_Uᵐ × SEₙ × n × (E₁/Eₙ). By comparing this expression with the pure‑DP speedup, they derive a condition under which hybrid training outperforms DP alone: S_Uᵐ > M × SE_{M·N} × (Eₙ/E_{M·N}). In other words, the per‑step gain from MP must be large enough to offset the additional communication and statistical inefficiencies introduced by scaling DP to more devices.
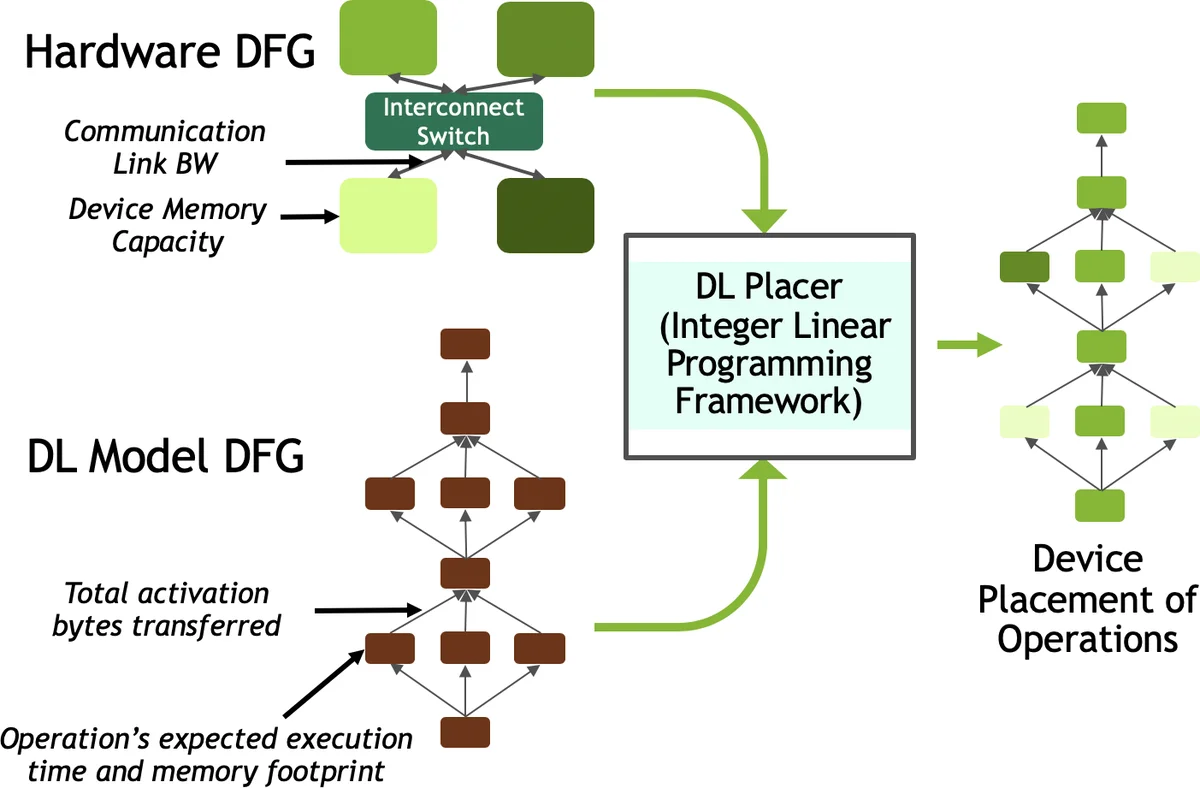
To make the hybrid approach practical, the paper introduces two technical contributions. First, an analytical framework that, given a target hardware configuration and a specific model, predicts the “crossover point” – the device count at which DP’s efficiency drops below the benefit offered by adding MP. Second, DLPlacer, an integer linear programming (ILP) tool that automatically determines the optimal placement of graph operations onto a set of GPUs, explicitly minimizing the total execution time including inter‑GPU data transfers. DLPlacer was validated on Inception‑V3, achieving a measured 1.32× speedup for a 2‑GPU split, within 6 % of the ILP‑predicted optimum.
Empirical evaluation was performed on three representative networks: Inception‑V3 (image classification), GNMT (neural machine translation), and BigLSTM (language modeling). For each network the authors implemented 2‑way and 4‑way MP versions and measured per‑step speedups on a multi‑GPU cluster. The results showed that DP scales reasonably well up to about 32 GPUs, after which SEₙ declines sharply. In contrast, the hybrid strategy continues to deliver gains because the per‑step MP speedup (S_Uᵐ) multiplies the DP base speedup without increasing the global batch size. Quantitatively, hybrid training achieved at least a 26.5 % reduction in total training time for Inception‑V3, an 8 % reduction for GNMT, and a 22 % reduction for BigLSTM compared with the best‑possible DP‑only configuration at the same scale.
The paper’s contributions can be summarized as follows: (1) a rigorous quantitative model that captures both compute and statistical aspects of DP and MP, enabling prediction of when hybridization is beneficial; (2) the DLPlacer ILP‑based optimizer that produces near‑optimal operation‑to‑GPU mappings; (3) a comprehensive experimental validation demonstrating that hybrid DP+MP consistently outperforms pure DP on large‑scale GPU clusters across diverse model architectures. The work provides a concrete roadmap for practitioners seeking to maximize hardware utilization and minimize time‑to‑solution in large‑scale deep‑learning training workloads.
Comments & Academic Discussion
Loading comments...
Leave a Comment