Large-scale Environmental Data Science with ExaGeoStatR
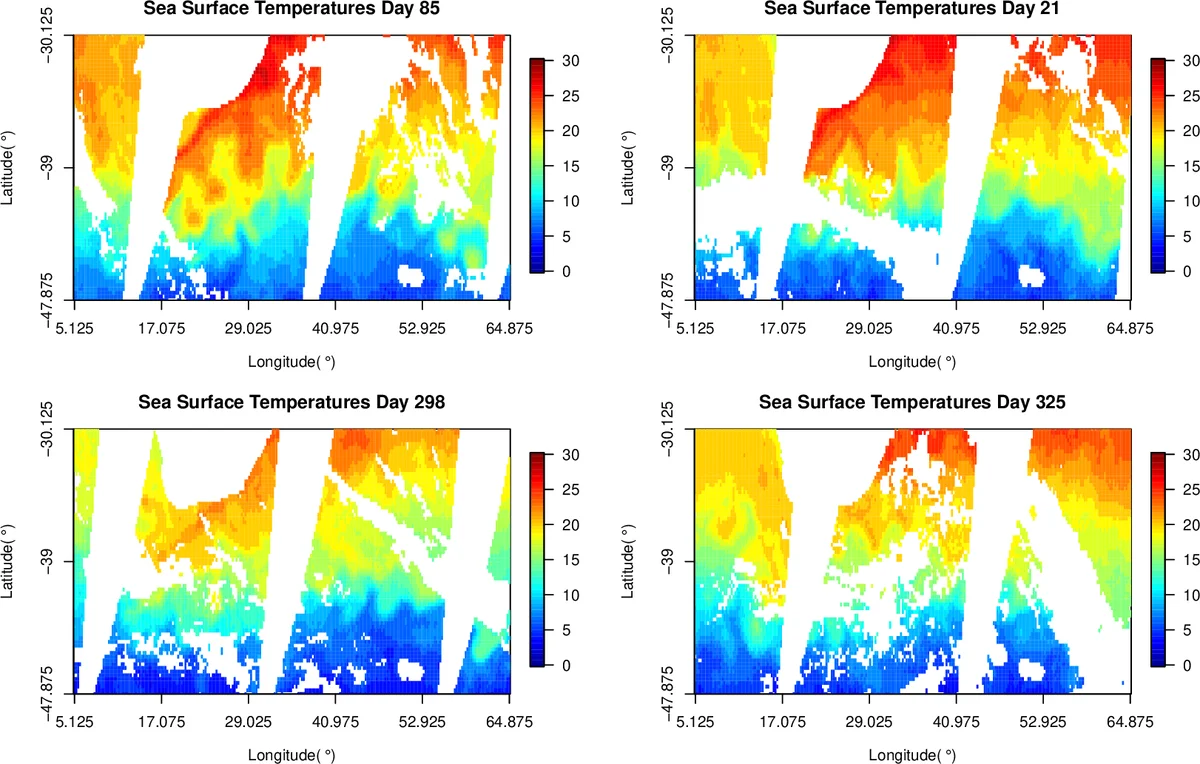
Parallel computing in Gaussian process calculations becomes necessary for avoiding computational and memory restrictions associated with large-scale environmental data science applications. The evaluation of the Gaussian log-likelihood function requires O(n^2) storage and O(n^3) operations where n is the number of geographical locations. Thus, computing the log-likelihood function with a large number of locations requires exploiting the power of existing parallel computing hardware systems, such as shared-memory, possibly equipped with GPUs, and distributed-memory systems, to solve this computational complexity. In this paper, we advocate the use of ExaGeoStatR, a package for exascale Geostatistics in R that supports a parallel computation of the exact maximum likelihood function on a wide variety of parallel architectures. Parallelization in ExaGeoStatR depends on breaking down the numerical linear algebra operations in the log-likelihood function into a set of tasks and rendering them for a task-based programming model. The package can be used directly through the R environment on parallel systems. Currently, ExaGeoStatR supports several maximum likelihood computation variants such as exact, Diagonal Super Tile (DST), Tile Low-Rank (TLR) approximations, and Mixed-Precision (MP). ExaGeoStatR also provides a tool to simulate large-scale synthetic datasets. These datasets can help to assess different implementations of the maximum log-likelihood approximation methods. Here, we demonstrate ExaGeoStatR by illustrating its implementation details, analyzing its performance on various parallel architectures, and assessing its accuracy using synthetic datasets with up to 250K observations. We provide a hands-on tutorial to analyze a sea surface temperature real dataset. The performance evaluation involves comparisons with the popular packages geoR and fields for exact likelihood evaluation.
💡 Research Summary
The paper introduces ExaGeoStatR, an R package that brings high‑performance, task‑based parallel computing to the exact maximum‑likelihood estimation (MLE) of Gaussian process (GP) models for large‑scale environmental data. Traditional GP inference requires O(n³) operations and O(n²) memory for n spatial locations, which becomes prohibitive for datasets with tens or hundreds of thousands of points. ExaGeoStatR addresses this bottleneck by wrapping the C‑based ExaGeoStat library, which implements the core linear‑algebra kernels (Cholesky factorization, solves, determinant evaluation) using a tile‑based decomposition. Each tile is treated as an independent task that can be scheduled on shared‑memory multicore CPUs, GPUs, or distributed‑memory clusters via runtime systems such as StarPU, QUARK, or MPI‑based schedulers.
Four computation modes are supported: (1) Fully‑Dense (Exact) where all tiles are stored in double precision, delivering mathematically exact log‑likelihood values; (2) Diagonal Super Tile (DST) which zeroes out off‑diagonal super‑tiles to reduce memory footprint; (3) Tile Low‑Rank (TLR) that approximates each tile with a low‑rank representation, lowering the asymptotic cost to O(n²·r) with r the rank; and (4) Mixed‑Precision (MP) that performs most arithmetic in single precision while retaining double‑precision accuracy for critical steps. These variants allow users to trade accuracy for speed and memory according to the problem size and hardware resources.
The authors benchmark ExaGeoStatR on synthetic datasets generated with a Matérn covariance function (up to 250 000 observations) and on a real sea‑surface‑temperature (SST) dataset containing more than 10 000 locations per day. In exact mode, ExaGeoStatR outperforms the popular R packages geoR and fields by factors ranging from 5× to 30× on a single node equipped with multicore CPUs, and achieves near‑linear scaling on multi‑node clusters (e.g., 4 nodes × 64 cores) and on GPU‑rich servers (8 GPUs). The package can handle up to one million locations on hardware commonly available to research institutions, a scale that is infeasible for existing R implementations.
In approximation modes, DST and TLR reduce memory usage by over 70 % while keeping parameter‑estimation bias below 1 %. TLR with rank r = 20 yields a five‑fold speed‑up relative to the exact method with negligible loss of statistical efficiency. The MP mode delivers an additional ~1.8× speed gain with numerical results indistinguishable from full double precision.
Optimization is performed through the NLopt library, exposing algorithms such as L‑BFGS‑B and COBYLA directly from R. Users can specify bounds, initial guesses, and obtain gradient information automatically, without writing any C, CUDA, or MPI code. The package also supports great‑circle distances for spherical coordinates, making it suitable for global‑scale applications.
Overall, ExaGeoStatR bridges the gap between high‑performance computing and the R ecosystem, enabling environmental scientists to fit exact GP models on massive datasets with modest effort. The authors conclude by outlining future work that includes extending the framework to non‑stationary models, Bayesian inference via MCMC, and integration with emerging hardware such as tensor‑core accelerators.
Comments & Academic Discussion
Loading comments...
Leave a Comment