A trust model for spreading gossip in social networks
We introduce here a multi-type bootstrap percolation model, which we call T-Bootstrap Percolation (T-BP), and apply it to study information propagation in social networks. In this model, a social network is represented by a graph G whose vertices have different labels corresponding to the type of role the person plays in the network (e.g. a student, an educator, etc.). Once an initial set of vertices of G is randomly selected to be carrying a gossip (e.g. to be infected), the gossip propagates to a new vertex provided it is transmitted by a minimum threshold of vertices with different labels. By considering random graphs, which have been shown to closely represent social networks, we study different properties of the T-BP model through numerical simulations, and describe its implications when applied to rumour spread, fake news, and marketing strategies.
💡 Research Summary
The paper introduces a novel multi‑type bootstrap percolation model, called Trusted Bootstrap Percolation (T‑BP), to capture how information spreads in social networks when the credibility of a message depends on the diversity of its sources. In T‑BP each vertex of a graph G is assigned a label (e.g., student, educator, political affiliation) drawn uniformly from a set of size m. A “trust family” T consists of one or more trust vectors K = (k₁,…,k_m) ∈ ℕ^m. A vertex becomes infected at time t + 1 if there exists a vector K in T such that for every label i the vertex has at least k_i infected neighbours of that label. Classical r‑neighbour bootstrap percolation is recovered when all vectors sum to r and only one label is used.
The authors formalize the notion of an immune vertex: a vertex is immune if for every trust vector there is at least one label i for which the vertex does not have enough neighbours (|N_i(v)| < k_i). They define the “diversity” D_v as the number of distinct labels among a vertex’s neighbours. In the r‑neighbour case, immunity is equivalent to D_v < r, and they derive exact probabilities of this event using Stirling numbers of the second kind. For the most general single‑vector case they obtain a multinomial expression for the immunity probability p_d^I(k) for a vertex of degree d, and then average over a degree distribution P(d) to get the overall immune fraction p^I(G,T).
Two families of underlying graphs are examined. First, random graphs with a power‑law degree distribution (γ≈2–3), which model real‑world social networks. Second, a deterministic hierarchical network introduced in prior work, whose degree distribution also follows a power law with exponent γ = 1 + ln 3/ln 2. For the hierarchical network the authors compute the exact number of vertices of each degree and thus the expected immune fraction using the previously derived p_d^I(k).
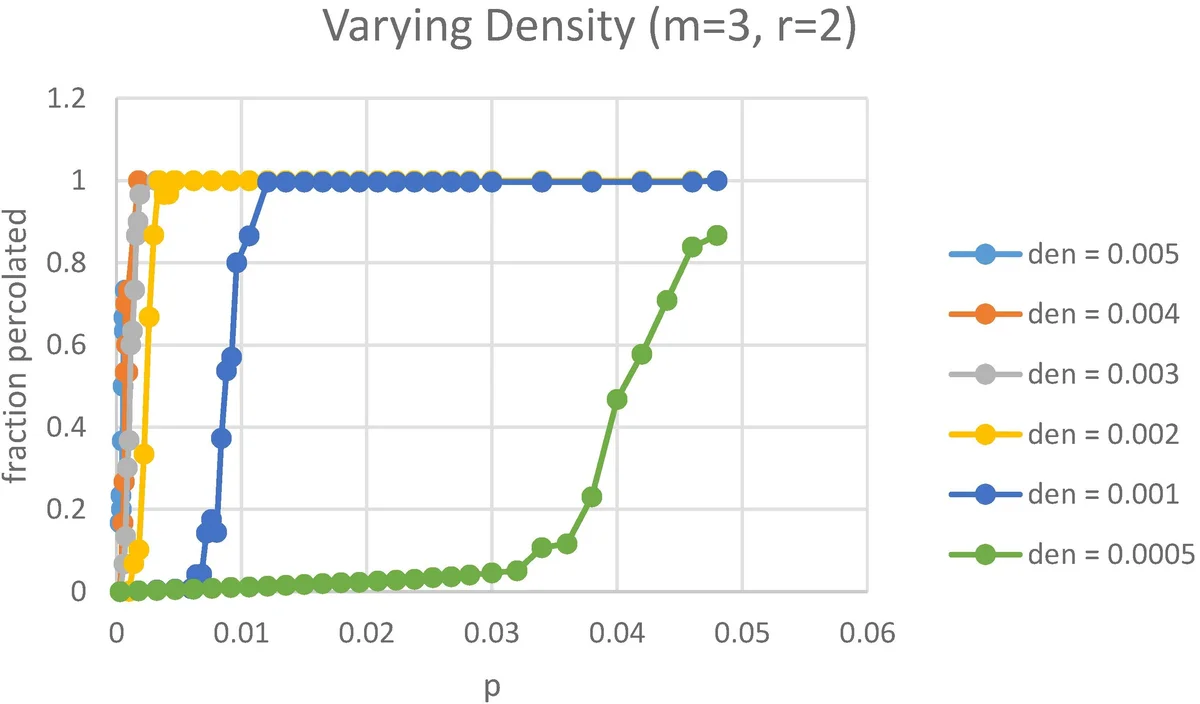
The bulk of the experimental work focuses on Erdős‑Rényi (ER) graphs with n = 10 000 vertices. By varying the edge probability ρ (graph density), the number of labels m, and the required number of distinct labels r, they measure the critical initial infection probability p_c that yields percolation of at least half the network, as well as the final infected fraction A_∞/|V|. Results show a sharp “wall‑crossing” transition: for a given ρ, a small increase in p around p_c produces a large jump in the percolated fraction. Larger ρ lowers p_c dramatically; for ρ ≥ 0.001, even p ≈ 0.01 suffices to infect almost the entire graph. Conversely, for sparse graphs (ρ < 0.0005) the process stalls even when many vertices are initially infected.
Increasing the number of labels m or the required distinct‑label threshold r raises p_c substantially. For example, with m = 4 and r = 3, p_c ≈ 0.0025 when ρ = 0.002, meaning that at least 2.5 % of the population must be seeded to achieve a majority spread. When only two distinct labels are required (r = 2) the same density yields p_c ≈ 0.001, illustrating how diversity requirements act as a barrier to diffusion.
The paper discusses practical implications. In fake‑news mitigation, policymakers could enforce that a claim be corroborated by multiple independent demographic groups before it is widely accepted, thereby increasing the effective r and reducing the chance of viral spread. Marketers can strategically select seed users from a minimal set of distinct consumer segments to trigger organic word‑of‑mouth diffusion, optimizing the trade‑off between seed cost and reach. Public‑health campaigns can benefit by ensuring that health messages reach a diverse set of community leaders, lowering the immune fraction and facilitating herd immunity against misinformation.
In conclusion, T‑BP provides a flexible, analytically tractable framework that incorporates both the heterogeneity of social roles and the trust thresholds governing information acceptance. By linking graph topology, label diversity, and trust parameters, the model yields quantitative predictions for critical seeding thresholds and final adoption levels, offering valuable guidance for designing interventions in modern, multi‑layered social networks.
Comments & Academic Discussion
Loading comments...
Leave a Comment